BigQuery 비용 최적화 12가지 — 마케팅 데이터 운영자가 매달 확인할 것
BigQuery 청구서가 매달 두 배 되지 않게 막는 12가지. 파티션·클러스터링 설계부터 SELECT 금지, on-demand vs slot 결정, INFORMATION_SCHEMA 비용 모니터링, GA4 raw 이벤트 cost-aware 패턴까지 운영자 체크리스트로 정리합니다.
BigQuery 청구서를 처음 받아 본 마케팅 데이터팀이 가장 많이 하는 말은 “쿼리 몇 번 돌렸을 뿐인데 왜 이렇게 나오죠?”예요. BigQuery는 서버를 빌리는 게 아니라 스캔한 데이터 양에 돈을 냅니다. 그래서 같은 결과를 뽑아도 어떻게 쓰느냐에 따라 비용이 10배, 100배 차이 납니다. 이 글은 광고·마케팅 데이터를 BigQuery에서 운영하는 사람이 매달 한 번씩 훑어볼 12가지 절감 포인트를 체크리스트로 정리합니다. 코드를 직접 짜지 않는 운영자도 “이 패턴이 비싸구나”를 알아볼 수 있게, 의사결정 기준 위주로 풀었습니다.
BigQuery 비용은 어디서 새는가
BigQuery on-demand 요금의 본질은 단순합니다. 쿼리가 실제로 읽은 바이트 수에 비례해 과금합니다. 행 수도, 쿼리 횟수도, 걸린 시간도 아닙니다. 오직 스캔한 컬럼의 바이트입니다.
대략적인 비용 모델은 이렇게 씁니다.
여기서 는 스캔 1TB당 단가(리전·시점에 따라 다르며 보통 미화 6~7달러 선)입니다. 핵심은 분자인 bytes scanned를 줄이는 모든 행위가 곧 비용 절감이라는 점입니다.
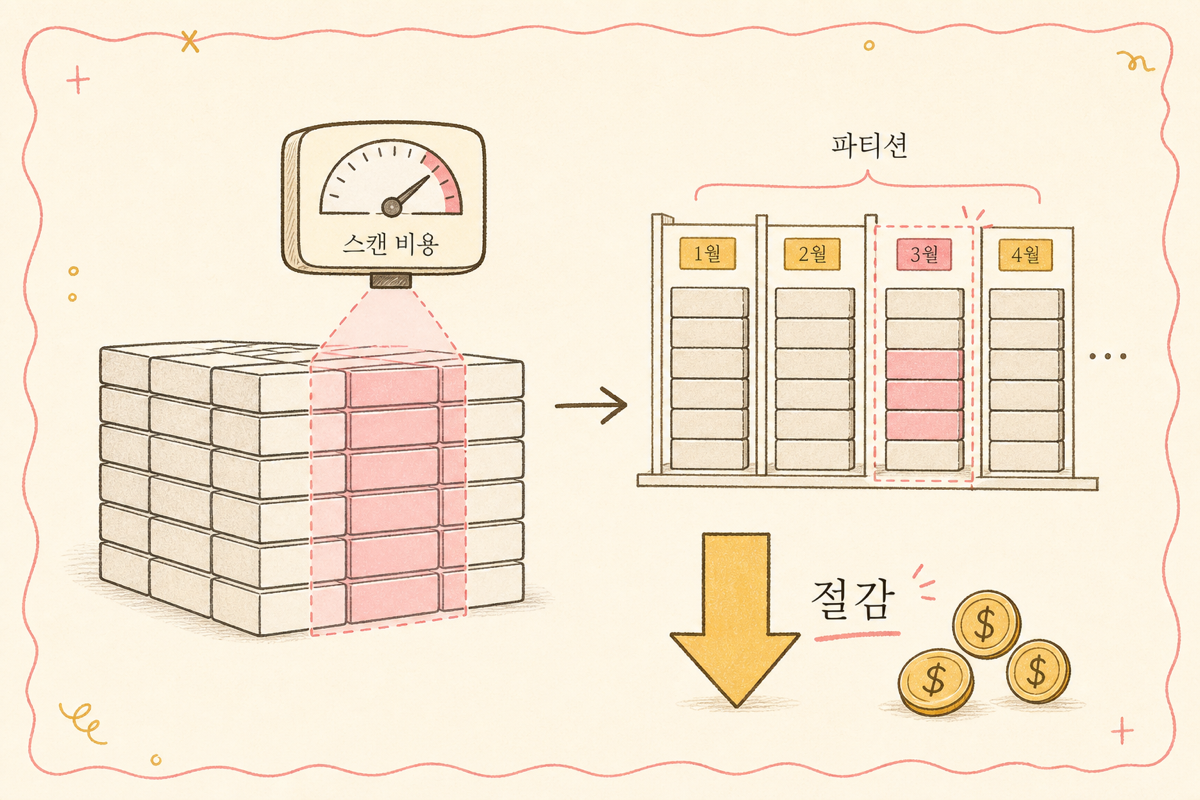
스캔 바이트가 늘어나는 전형적인 누수는 세 곳입니다. 첫째, 필요 없는 컬럼까지 읽는 것(SELECT 전체). 둘째, 필요 없는 기간·파티션까지 읽는 것(파티션 미사용). 셋째, 같은 쿼리를 캐시 없이 반복해서 읽는 것. 12가지 절감안은 결국 이 세 누수를 막는 변주입니다.
1~3. 설계 레벨 — 파티션과 클러스터링
가장 큰 절감은 쿼리를 고치기 전에 테이블 설계에서 나옵니다. 여기서 80%가 결정됩니다.
1) 날짜 파티션을 반드시 건다
마케팅 데이터는 거의 전부 시계열입니다. 일자별 광고비, 일자별 전환, 일자별 이벤트. 테이블을 날짜로 파티션하면, 날짜 조건이 들어올 때 해당 날짜 블록만 읽습니다. 이걸 파티션 프루닝(pruning)이라고 합니다.
전체 1년치 테이블에서 최근 7일만 보는 쿼리라면, 이론상 스캔 바이트가 이렇게 줄어듭니다.
즉 98% 절감. 파티션 하나로 같은 쿼리 비용이 1/50이 되는 셈입니다. 마케팅 테이블에서 파티션 미설정은 가장 비싼 실수입니다.
2) 자주 거르는 컬럼으로 클러스터링한다
파티션이 “날짜로 책장을 나눈다”면, 클러스터링은 “책장 안에서 자주 찾는 순서로 정렬”하는 것입니다. channel, campaign_id, country처럼 필터·그룹화에 자주 등장하는 컬럼으로 클러스터링하면, 그 조건이 들어올 때 읽는 블록이 더 줄어듭니다.
3) 파티션 만료와 필수 필터
오래된 데이터를 자동 삭제하는 파티션 만료를 걸면 저장 비용이 줄고, 필수 파티션 필터(require_partition_filter)를 켜면 날짜 조건 없는 풀스캔 쿼리를 아예 막아 사고를 예방합니다. 신입이 실수로 1년치를 통째로 긁는 일을 차단하는 안전장치입니다. 파티션·클러스터·안전장치를 한 번에 거는 테이블 정의(DDL) 예시는 글 끝의 접힘 박스에 넣어 두었습니다.
4~6. 쿼리 레벨 — 읽는 바이트를 줄인다
4) 전체 컬럼 선택을 금지한다
BigQuery는 컬럼 단위로 저장(columnar)합니다. 모든 컬럼을 부르는 쿼리는 안 쓰는 컬럼까지 전부 읽으므로, 필요한 컬럼만 명시하는 것만으로 비용이 즉시 내려갑니다. GA4 events 테이블처럼 컬럼이 수십 개에 중첩(nested) 구조까지 있는 경우, 전체 선택과 컬럼 3개 선택의 차이는 수십 배가 됩니다.
5) 쿼리 전에 스캔량을 미리 본다
BigQuery 콘솔은 쿼리를 실행하기 전에 “이 쿼리는 N GB를 처리합니다”라고 견적을 보여줍니다(dry run). 비싼 쿼리를 돌리기 전에 이 숫자를 확인하는 습관 하나로 사고를 막을 수 있습니다. 운영 파이프라인이라면 dry-run 플래그로 CI에서 자동 검사할 수도 있습니다.
6) LIMIT은 비용을 줄여주지 않는다
여기서 마케터·주니어가 가장 자주 오해합니다. LIMIT 10을 붙이면 싸질 것 같지만, BigQuery는 먼저 스캔한 뒤 마지막에 자른다는 점입니다. 즉 LIMIT은 결과 행만 줄일 뿐 스캔 바이트는 그대로입니다. 미리보기는 LIMIT 대신 콘솔의 테이블 프리뷰 탭이나 파티션 조건을 쓰세요.
7. on-demand vs Editions(slot) — 언제 갈아타나
여기까지가 “쿼리당 스캔 과금(on-demand)“을 줄이는 법이었습니다. 사용량이 커지면 정액제 성격의 Editions(slot 예약)가 더 쌀 수 있습니다. slot은 쿼리를 처리하는 연산 단위로, 시간당 빌리는 모델입니다.
결정 기준은 손익분기입니다. 월간 on-demand 비용이 slot 예약 비용을 넘기 시작하면 갈아탈 때입니다.
| 상황 | 추천 |
|---|---|
| 쿼리가 산발적·예측 불가 | on-demand |
| 매일 무거운 dbt run·대시보드 새로고침이 일정함 | Editions(slot) |
| 월 스캔량이 작고 팀이 작음 | on-demand |
| 비용 상한을 예측 가능하게 묶고 싶음 | slot(오토스케일 상한 설정) |
8~10. 반복 비용을 없애는 캐시·뷰·엔진
8) 캐시와 예약 쿼리(scheduled query)
BigQuery는 동일 쿼리 결과를 24시간 캐시합니다(테이블이 안 바뀌면). 대시보드가 같은 쿼리를 하루에 수백 번 호출한다면 캐시가 비용을 0으로 만듭니다. 단, 쿼리에 현재 시각 함수가 끼면 매번 다른 쿼리로 인식돼 캐시가 깨지니 주의하세요.
9) Materialized View로 무거운 집계를 미리 굽는다
자주 쓰는 무거운 집계(예: 채널×일자 spend 합계)는 Materialized View로 만들어 두면, BigQuery가 증분만 갱신하고 쿼리는 미리 구운 결과를 읽습니다. 매번 raw를 풀스캔하는 대시보드 쿼리를 이걸로 갈아끼우면 효과가 큽니다.
10) BI Engine으로 대시보드 응답을 인메모리로
Looker Studio·Looker 같은 BI 도구가 BigQuery를 자주 때린다면 BI Engine(인메모리 가속) 예약으로 반복 스캔 비용과 지연을 함께 줄일 수 있습니다.
11~12. 비용을 보이게 만들고, GA4를 길들인다
11) 비용 모니터링 — 측정해야 줄인다
비용은 보이지 않으면 절대 안 줄어듭니다. BigQuery는 INFORMATION_SCHEMA.JOBS에 모든 쿼리의 스캔 바이트와 실행자를 남깁니다. 누가·어떤 쿼리로·얼마를 태웠는지 주간으로 보는 것만으로도 상위 몇 개 쿼리가 비용의 대부분임을 알게 됩니다.
-- 지난 7일, 스캔량 큰 사용자 TOP 10 (누가 비용을 태우는가)SELECT user_email, ROUND(SUM(total_bytes_processed)/POW(2,40), 2) AS tb_scannedFROM `region-us`.INFORMATION_SCHEMA.JOBSWHERE creation_time > TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY)GROUP BY user_email ORDER BY tb_scanned DESC LIMIT 10;여기에 더해 쿼리·테이블에 labels를 붙여 팀·용도별로 비용을 쪼개고, 프로젝트 단위로 일일 스캔 상한(custom quota)을 걸면 폭주 사고를 원천 차단합니다.
12) GA4 raw 이벤트의 cost-aware 패턴
GA4 BigQuery export(events_YYYYMMDD)는 마케팅 데이터에서 가장 비싸지기 쉬운 테이블입니다. 이벤트가 행마다 중첩 파라미터를 들고 있어 풀스캔이 무겁기 때문입니다. 세 가지만 지키면 됩니다. 첫째, 테이블 접미사(_TABLE_SUFFIX)로 날짜 범위를 좁혀 필요한 일자 샤드만 읽습니다. 둘째, 필요한 이벤트·파라미터만 staging 테이블로 한 번 정제해 두고 다운스트림은 그걸 봅니다. 셋째, 자주 보는 지표는 일 1회 배치로 마트에 구워 대시보드가 raw를 직접 안 때리게 합니다.
12가지 체크리스트 요약
| # | 항목 | 레벨 | 효과 |
|---|---|---|---|
| 1 | 날짜 파티션 | 설계 | 매우 큼 |
| 2 | 클러스터링 | 설계 | 큼 |
| 3 | 파티션 만료·필수 필터 | 설계 | 사고 예방 |
| 4 | 전체 컬럼 선택 금지 | 쿼리 | 큼 |
| 5 | dry run으로 사전 견적 | 쿼리 | 사고 예방 |
| 6 | LIMIT 오해 버리기 | 쿼리 | 인식 교정 |
| 7 | on-demand vs slot 판단 | 과금 | 큼 |
| 8 | 캐시·예약 쿼리 | 반복 | 큼 |
| 9 | Materialized View | 반복 | 큼 |
| 10 | BI Engine | 반복 | 중간 |
| 11 | INFORMATION_SCHEMA 모니터링 | 운영 | 필수 |
| 12 | GA4 raw cost-aware 패턴 | 운영 | 매우 큼 |
마치며
BigQuery 비용 최적화는 한 번의 영웅적 작업이 아니라 매달 돌아오는 위생 점검에 가깝습니다. 설계(파티션·클러스터)에서 큰 덩어리를 잡고, 쿼리 습관(전체 컬럼 선택·LIMIT 오해)에서 누수를 막고, 모니터링(INFORMATION_SCHEMA)으로 보이게 만든 뒤, GA4 raw를 마트 뒤로 숨기면 청구서가 예측 가능해집니다.
가장 먼저 할 일을 하나만 고르라면, 11번 모니터링 쿼리를 돌려 “이번 주 비용 상위 10개”를 보는 것입니다. 거의 항상 소수의 쿼리가 비용의 대부분을 차지하고, 그 몇 개만 고쳐도 절반이 빠집니다.
파티션 + 클러스터 + 안전장치를 한 번에 건 테이블 정의 (DDL)
CREATE TABLE mart.daily_ad_spend ( event_date DATE, channel STRING, campaign_id STRING, spend FLOAT64)PARTITION BY event_dateCLUSTER BY channel, campaign_idOPTIONS (require_partition_filter = true, partition_expiration_days = 540);