LLM이 어떻게 답을 만드는가 — 토큰·다음 단어 예측·temperature 기초 체력
GPT·Claude·Gemini가 답을 어떻게 만드는지 한 번도 안 들여다보면 LLM 활용이 늘 신비로 남습니다. 토큰화·다음 단어 예측·temperature·top-p의 4가지 핵심만 잡으면 LLM이 왜 그렇게 답하는지 보입니다. 마케터가 LLM을 다룰 때의 첫 기초 체력.
“GPT한테 물어봤더니 답을 잘 해주더라”의 자리는 마케터·운영자에게 일상이 됐습니다. 그런데 그 안에서 무엇이 일어나는지를 한 번도 안 들여다보면 LLM 활용이 늘 신비로 남습니다. 답이 좋을 땐 운이 좋고, 나쁠 땐 왜 그런지 모릅니다. 이 글은 LLM이 답을 만드는 4가지 핵심 — 토큰화·다음 단어 예측·temperature·top-p — 을 마케터 시각으로 풀어냅니다. 한 번 잡아두면 그 다음의 모든 LLM 글이 다르게 읽힙니다.
1. LLM이 답을 만드는 흐름의 한 줄
LLM(GPT·Claude·Gemini)이 “한 답”을 만드는 흐름을 한 줄로 적으면 다음입니다.
입력 텍스트를 토큰으로 잘라, 그 다음 토큰을 한 개씩 예측해, 멈춤 신호가 나올 때까지 이어 붙인다.
이 한 줄 안에 4가지 개념이 들어 있습니다.
- 토큰화 — 텍스트를 어떻게 자르나
- 다음 토큰 예측 — 각 토큰의 확률을 어떻게 계산하나
- 샘플링 — 확률 분포에서 어떻게 한 토큰을 고르나(temperature·top-p)
- 멈춤 — 언제 답을 끝내나
각자가 LLM 출력의 다른 자리에 영향을 줍니다. 한 번 잡아두면 LLM이 왜 그렇게 답하는지가 보입니다.
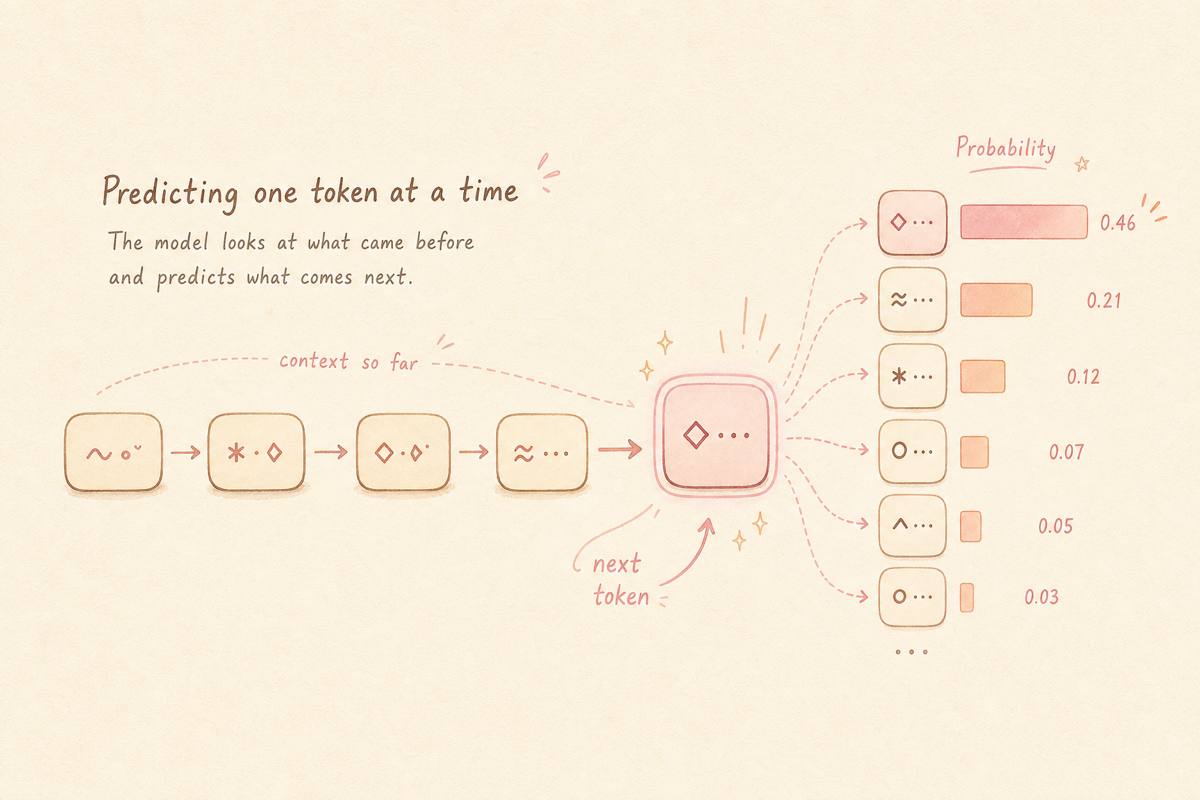
2. 토큰화 — 텍스트가 잘리는 자리
LLM은 글자나 단어가 아니라 토큰 단위로 작동합니다. 토큰은 글자보다 크고 단어보다 작은 단위 — 보통 자주 나오는 단어 조각·짧은 단어 자체.
영어 예시:
- “marketing” → 1 토큰
- “marketability” → “market” + “ability” = 2 토큰
- “GPT-4” → “G” + “PT” + ”-” + “4” = 4 토큰
한국어 예시 (GPT 토크나이저 기준):
- “안녕하세요” → “안녕” + “하” + “세요” = 3 토큰
- “광고 카피” → “광” + “고” + ” 카” + “피” = 4 토큰
- “마케터” → “마” + “케터” = 2 토큰
같은 의미의 한국어가 영어보다 토큰을 1.52배 많이 쓰는 게 일반적입니다. LLM API 비용은 토큰당이라 — 한국어가 같은 글에 1.52배 비싼 이유.
2-1. 토큰화의 운영 영향
- 비용 — 입력·출력 토큰 수에 비례
- 속도 — 토큰 1개씩 생성하므로 출력 토큰 수가 latency 결정
- 컨텍스트 한계 — 모델 최대 토큰 수(예: GPT-4o 128k) 안에 입력·출력이 모두 들어와야 함
2-2. 토큰화에서 나오는 흔한 함정
- 한국어 마케팅 카피 평가 시 “30자 이내”라고 시키면 모델이 자르는 단위가 토큰이라 정확히 30자가 아닐 수 있음
- “JSON 형식으로 답해”라고 시키면
{·}하나씩 토큰. JSON 출력이 자유 텍스트보다 토큰 수가 많음 - 외래어·신조어가 많은 한국어 카피는 토큰화가 비효율적
3. 다음 토큰 예측 — 모델이 진짜 하는 일
LLM이 “답을 한다”의 본질은 다음 한 줄입니다.
지금까지의 토큰들 다음에 올 가장 가능성 큰 토큰을 확률로 예측한다.
지금까지의 토큰이 [“광고”, “카피”, “는”]이라면, 모델은 다음 토큰의 확률 분포를 출력:
- “짧” — 0.18
- “친” — 0.12
- “임” — 0.09
- “효” — 0.07
- … (수만 개 토큰 각각의 확률)
이 분포에서 한 토큰을 골라 입력에 추가하고, 그 다음 토큰의 분포를 다시 계산. 반복.
이 흐름이 가지는 두 가지 운영적 함의:
3-1. 같은 입력에 다른 답
분포에서 무작위로 샘플링하므로, 같은 입력에 다른 답이 나올 수 있습니다. random seed를 고정하지 않으면 매번 다른 결과. 운영 일관성 필요한 자리는 seed 고정 또는 temperature=0.
3-2. 멀리 있는 정보가 약하게 영향
모델은 “지금까지의 모든 토큰”에 영향을 받지만 가까운 토큰에 더 큰 가중치. 긴 컨텍스트의 앞부분 정보는 뒷부분에서 잘 안 쓰일 수 있음(lost-in-the-middle 현상). 중요한 정보는 컨텍스트의 처음·끝에 둬야 합니다.
4. Temperature — 샘플링의 보수성
분포에서 한 토큰을 어떻게 고르나의 답이 샘플링 전략입니다. 가장 흔한 도구가 temperature.
수식으로:
가 temperature. 의미:
- — 가장 확률 높은 토큰을 결정적으로 선택. 같은 입력에 같은 답
- — 거의 보수적, 약간의 변동성
- — 모델이 학습한 분포 그대로 샘플링
- — 분포를 평탄화 — 다양성 강화, 가끔 이상한 토큰
운영 자리별 temperature 가이드:
| 자리 | 권장 temperature |
|---|---|
| 사실 답변·RAG | 0.0~0.3 |
| 광고 카피 변형 | 0.7~1.0 |
| 창의적 브레인스토밍 | 1.0~1.3 |
| 코드 생성 | 0.0~0.2 |
5. Top-p (nucleus sampling) — 후보 풀의 크기
temperature 외에 자주 쓰이는 도구가 top-p (nucleus sampling). 한 줄 정의:
분포의 상위 누적 확률 안의 토큰들만 후보로 두고, 그 안에서 샘플링.
이면 상위 90% 확률 차지하는 토큰들만 후보. 나머지는 무시. temperature가 분포의 모양을 바꾼다면, top-p는 분포의 꼬리를 자르는 역할.
운영적으로 자주 쓰이는 결합:
- temperature=0.7 + top-p=0.9 — 다양성 적당, 이상한 토큰 차단
- temperature=0.0 — top-p 무관 (이미 결정적)
from openai import OpenAI
client = OpenAI()r = client.chat.completions.create( model='gpt-4o', messages=[{'role': 'user', 'content': '광고 카피 5개 만들어줘'}], temperature=0.8, top_p=0.95, seed=42,)print(r.choices[0].message.content)이게 본문에 박는 유일한 코드입니다. temperature·top_p·seed 세 파라미터가 출력을 통제하는 핵심.
6. 멈춤 — 언제 답을 끝내나
LLM이 답을 끝내는 트리거는 두 가지입니다.
6-1. 멈춤 토큰
모델이 학습 시 본 “답의 끝” 신호 — 보통 <|endoftext|> 같은 특수 토큰. 모델이 이 토큰을 충분히 높은 확률로 예측하면 자동 멈춤.
6-2. max_tokens 한계
운영자가 명시적으로 정한 최대 출력 토큰 수. 도달하면 강제 멈춤.
운영적 의미:
- 짧은 답이 필요하면 max_tokens 명시 (비용·latency 통제)
- 그러나 max_tokens가 너무 짧으면 답이 중간에 잘림 — 의도한 것과 다른 답
- 한국어는 같은 길이 답에 토큰이 1.5~2배 필요하므로 max_tokens도 그만큼
7. 마케팅 운영의 4가지 적용
7-1. 카피 자동 생성
temperature 0.81.0, top_p 0.9. 다양성 보장하면서 이상한 토큰 차단. 같은 입력에 매번 다른 카피 510개 생성.
7-2. RAG 챗봇 답변
temperature 0.1~0.3. 사실 답변에 다양성 필요 없음. 같은 질문에 같은 답이 일관성 측면에서 유리. seed 고정으로 디버깅 쉬워짐.
7-3. 광고 분류·태깅
temperature 0.0. 결정적 분류. JSON 출력 형식이면 함수 호출(function calling) 사용 — 더 안정적인 형식 보장.
7-4. 마케팅 리포트 narrative
temperature 0.5~0.7. 사실 기반(낮은 temperature 필요)이지만 너무 단조롭지 않게. 보고서 톤에 약간의 자연스러운 변동.
8. LLM 답이 깨질 때 — 흔한 함정 3가지
8-1. 한국어 토큰 비효율 무시
같은 답에 영어보다 1.5-2배 토큰. 비용·latency·max_tokens 모두 영향. API 사용 시 한국어 토큰 카운팅을 별도로 모니터링하는 게 안전.
8-2. Temperature를 자리마다 안 다르게
모든 호출에 default temperature(보통 1.0) 사용. 사실 답변에도 1.0 쓰면 다양성이 일관성을 깨뜨려 RAG 정확도 떨어짐. 자리별 적합한 temperature 정의가 운영 표준.
8-3. max_tokens 안 명시
명시 안 하면 모델 디폴트(보통 4096~8192)까지 생성 가능. 비용·latency 폭발 가능. 자리별 적정 max_tokens 명시.
9. 마치며 — LLM의 출력은 분포에서 한 번 뽑은 결과
LLM이 어떻게 답을 만드는가의 한 줄 정리:
다음 토큰의 확률 분포를 매번 새로 계산하고, temperature·top-p로 그 분포에서 한 토큰을 샘플링하고, 멈춤 토큰까지 반복한다.
이 한 줄을 잡고 있으면 LLM 출력의 변동성·일관성·비용·latency가 어디서 오는지 보입니다. 운영 결정 자리에서 “왜 이 답이 나왔지”의 답을 직관적으로 찾을 수 있게 됩니다.
다음 글에서는 같은 자리의 또 다른 기초 — 임베딩의 직관을 다룹니다. 단어가 어떻게 벡터가 되고, 그 벡터로 무엇을 할 수 있는지.
참고
- Vaswani et al. (2017), Attention Is All You Need, NeurIPS — 트랜스포머 원전, LLM의 모태
- Brown et al. (2020), Language Models are Few-Shot Learners (GPT-3), NeurIPS — LLM 시대를 연 논문
- Liu et al. (2023), Lost in the Middle: How Language Models Use Long Contexts — 긴 컨텍스트의 함정
- OpenAI Tokenizer 시각화 — 한국어 토큰화 직접 확인 가능
- tiktoken — Python 토크나이저 라이브러리 — 운영 적용 표준
- huny.log 내부 글: LLM-as-judge, 임베딩 운영, RAG 평가
AI·LLM 카테고리의 다른 글
전체 보기 →-
2026·05·16
LLM 운영 비용 폭주를 막는 6가지 guardrail — 마케팅 자동화의 cost·latency·품질 동시 관리
LLM을 운영에 올리면 어느 날 갑자기 비용이 10배로 튑니다. retry storm·프롬프트 폭증·모델 자동 승격·context 누적 등 폭주 패턴 6가지와 그것을 막는 guardrail을 정리합니다.
-
2026·05·10
LLM evaluation harness — 분기마다 챗봇 품질을 자동 평가하는 공장
챗봇·에이전트가 운영에 들어가면 한 번 평가가 아니라 분기 자동 평가가 필요합니다. 골든셋·regression·hyperparameter A/B를 묶는 evaluation harness 설계와 마케팅 자리에서의 적용.
-
2026·05·09
Context engineering — 200k 토큰 컨텍스트의 설계 원칙 5가지
컨텍스트 창이 200k 토큰까지 커졌지만 단순히 다 넣으면 lost-in-the-middle·비용 폭발·정확도 하락이 옵니다. 마케팅 자동화에 적용하는 5가지 컨텍스트 설계 원칙.
-
2026·05·09
Function calling 설계 패턴 — LLM이 도구를 부를 때 마케터가 점검할 것
LLM이 광고 API·BigQuery·Slack을 직접 부르기 시작하면, 답변 품질보다 "어느 도구를 언제 부를지"가 운영 사고의 진앙이 됩니다. function calling의 한 줄 직관과 마케터가 점검할 5가지.