Structured output 운영 — JSON Schema와 강제 형식이 LLM 사고를 줄이는 법
LLM이 자유 텍스트로 답하면 파서가 깨집니다. JSON Schema·strict mode로 출력 형식을 강제하면 자유도는 줄지만 운영 안정성은 폭증. 마케팅 자동화에서 자주 만나는 자리와 함정.
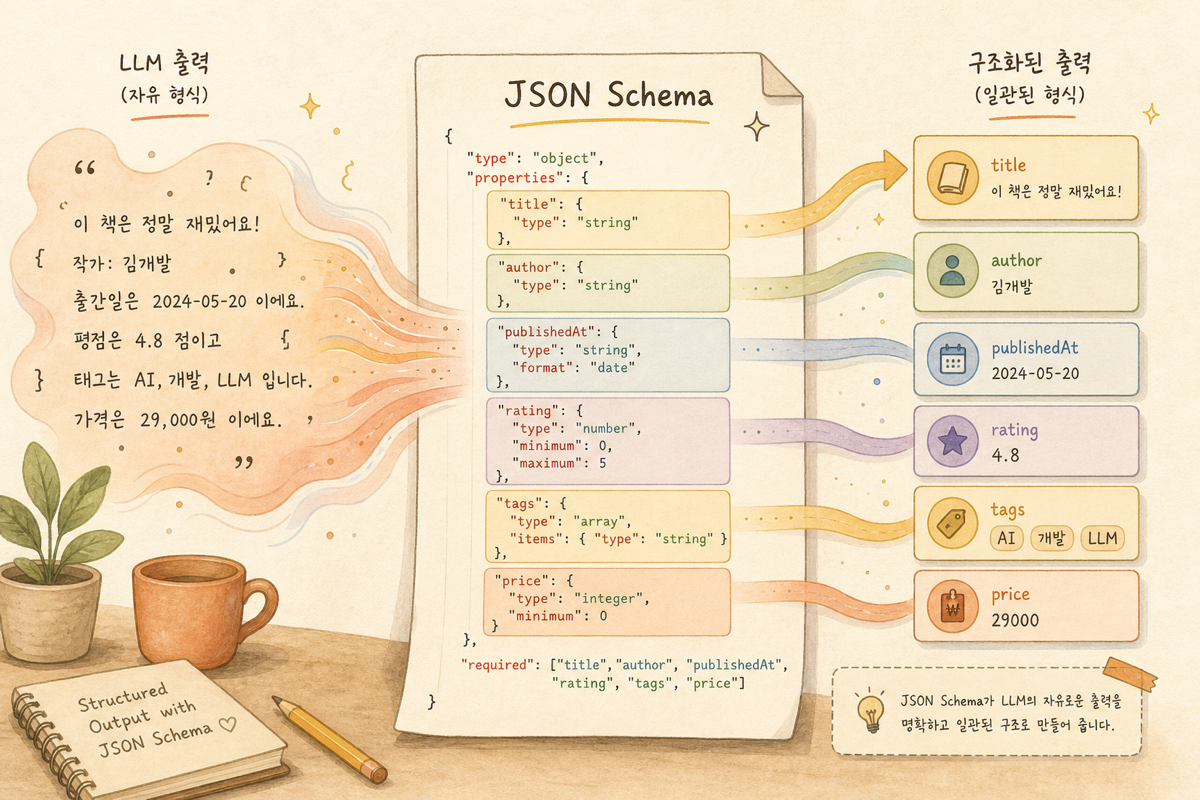
“이 캠페인 분석해서 카테고리·우선순위·메모로 정리해줘”라고 LLM에게 부탁하면, 어떤 날엔 마크다운 표로 답하고, 다른 날엔 자유 산문으로 답합니다. 자동화 파이프라인 입장에서는 매번 답 형식이 달라져 파서가 깨집니다. structured output은 이 문제를 해결합니다 — JSON Schema로 출력 형식을 박아두면 모델이 그 schema를 만족하는 JSON만 뱉습니다. 마케터가 LLM을 운영 자동화에 끼워 넣을 때 가장 먼저 쥐어야 할 도구입니다.
마케터가 이 글을 읽어야 하는 이유: 카피 양산·캠페인 분류·KPI 추출 같은 작업이 자동화되면, 매일 수백 번 LLM이 호출됩니다. 출력 한 줄이 다른 형식이면 파이프라인 한 단계가 통째로 멈춥니다. structured output은 그 안정성을 보장하는 가장 단순하고 강력한 장치이고, 마케터가 schema 한 줄만 잘 적어도 자동화의 운영 사고가 절반 이상 사라집니다.
1. 왜 자유 텍스트가 운영에서 깨지는가
LLM의 기본 출력 모드는 자유 텍스트입니다. 같은 프롬프트에 같은 모델이라도 응답 형식이 매번 흔들립니다.
| 호출 | 모델 응답 형식 |
|---|---|
| 1회차 | ”카테고리는 검색 광고이고, 우선순위는 높음입니다. 메모로는…“ |
| 2회차 | ”[카테고리] 검색 광고 / [우선순위] 높음” (마크다운 굵게 사용) |
| 3회차 | ”검색 광고 - 우선순위 상 - 메모: 시즌 종료 임박” |
| 4회차 | { category: '검색', priority: 'high', memo: ... } (따옴표 누락) |
자동화 파이프라인은 이 변동을 감당하기 어렵습니다. 정규식·텍스트 파싱으로 잡으려고 하면 새로운 형식이 나올 때마다 깨지고, 그때마다 파이프라인이 멈춥니다.
2. JSON Schema의 한 줄 직관
JSON Schema는 JSON이 만족해야 할 형식을 적은 메타 문서입니다.
출력에 어떤 키가 있어야 하고, 각 키의 타입·허용 값이 무엇인지를 미리 박아둔 계약서.
마케팅 자리의 예시:
| 항목 | 타입 | 제약 |
|---|---|---|
category | string | enum: ["search", "display", "video", "social"] |
priority | string | enum: ["low", "mid", "high"] |
memo | string | 최대 200자 |
tags | array of string | 최대 5개 |
이 schema를 LLM에 함께 넘기면, 모델은 자유 텍스트가 아닌 schema를 만족하는 JSON만 출력합니다. 4개 키 모두 있고, category는 4개 enum 값 중 하나이고, tags는 5개 이내입니다. 자동화 파이프라인이 안정적으로 받습니다.
3. Strict mode — 문법 보장과 의미 보장
JSON Schema에는 두 단계 보장이 있습니다.
3-1. 문법 보장 — JSON으로 파싱 가능한가
가장 약한 단계입니다. 따옴표·괄호·콤마가 깨지지 않은 valid JSON인지만 검사합니다. OpenAI의 response_format={"type": "json_object"}나 Anthropic의 JSON mode가 이 단계입니다.
3-2. 의미 보장 — schema와 정확히 일치하는가
OpenAI의 response_format={"type": "json_schema", "schema": ..., "strict": true} 또는 Anthropic의 tool use를 활용한 schema enforcement가 이 단계입니다. 키 이름, 타입, enum 값까지 schema와 정확히 일치하는 JSON만 통과합니다.
운영에서는 거의 항상 두 번째 단계를 씁니다. 문법만 맞고 키가 빠지거나 enum 외 값이 들어오면 다음 단계가 깨지기 때문입니다.
4. 마케팅 자동화에서 자주 만나는 자리 4가지
4-1. 캠페인 분류·라벨링
수백 개의 캠페인 메모를 카테고리·우선순위·플랫폼으로 라벨링하는 작업. 입력은 자유 텍스트, 출력은 정형화된 JSON. structured output의 가장 흔한 자리.
4-2. 카피 풀에서 메타데이터 추출
100개 광고 카피에서 “타겟 페르소나”, “감정 톤”, “CTA 종류”를 추출하는 작업. 한 카피에 여러 라벨이 동시에 붙는 경우 array of enum 활용.
4-3. 보고서 자동 생성의 데이터 단
LLM이 보고서를 작성하기 전에, 데이터 요약을 schema로 먼저 받습니다. “이번 주 ROAS 상위 캠페인 3개와 그 변화율”을 schema로 받고, 그 데이터를 바탕으로 자유 산문 보고서를 작성하는 두 단계 흐름. 산문 단계는 non-strict, 데이터 단은 strict.
4-4. 사용자 의도 분류
챗봇에 들어오는 질문을 “데이터 조회 vs 일반 질문 vs 액션 요청”으로 분류해 다른 도구로 보내는 라우팅 단계. 의도 분류가 깨지면 모든 후속 단계가 깨지므로 strict 필수.
| 자리 | strict 필요? | schema 깊이 |
|---|---|---|
| 분류·라벨링 | 강제 | 얕음 (1-2 level) |
| 메타데이터 추출 | 강제 | 중간 (array of object) |
| 보고서 데이터 단 | 강제 | 깊음 (nested object) |
| 의도 분류 | 강제 | 매우 얕음 (single enum) |
| 자유 답변 | 비-strict | — |
5. 코드 한 묶음 — strict mode 호출
이게 글에 박는 유일한 코드입니다. OpenAI의 strict mode로 캠페인 분류 자동화를 보여줍니다.
import openaifrom pydantic import BaseModelfrom typing import Literal
class CampaignLabel(BaseModel): category: Literal["search", "display", "video", "social"] priority: Literal["low", "mid", "high"] memo: str tags: list[str]
client = openai.OpenAI()resp = client.beta.chat.completions.parse( model="gpt-5", messages=[ {"role": "system", "content": "캠페인 메모를 카테고리·우선순위·태그로 라벨링."}, {"role": "user", "content": "M2026Q2-display, 시즌 종료 임박, 예산 소진 빠름"}, ], response_format=CampaignLabel,)label = resp.choices[0].message.parsedprint(label.category, label.priority, label.tags)# 'display' 'high' ['시즌종료', '예산소진']Pydantic 모델이 그대로 schema가 되어 모델에 넘어가고, 응답은 valid CampaignLabel 인스턴스로 파싱됩니다. 자유 텍스트 파서를 쓸 일이 없습니다.
6. Schema 설계의 작은 디테일
같은 작업이라도 schema 설계 한 줄로 안정성이 크게 달라집니다.
6-1. enum을 적극 사용
자유 문자열보다 enum이 모델 정확도와 다운스트림 안정성 둘 다에 좋습니다. category가 자유 문자열이면 같은 의미의 다른 표기가 섞입니다(Search, search, 검색). enum 4개 값으로 제약하면 깔끔.
6-2. description을 각 필드에 적기
JSON Schema의 description 필드는 모델에 노출됩니다. “category: 광고 매체 종류 (검색·디스플레이·영상·소셜)“처럼 적으면 모델이 분류 기준을 명확히 잡습니다.
6-3. nested object는 얕게
3-level 이상 중첩 schema는 모델이 헤매기 시작합니다. 가능하면 1-2 level로 평탄화하고, 깊은 구조가 필요하면 두 단계 호출로 분리.
6-4. required 필드를 명시
required로 지정하지 않으면 모델이 어떤 필드를 빠뜨릴 수 있습니다. 다운스트림 코드가 None을 처리해야 해 깨지기 쉽습니다.
7. 모델별 지원 현황과 한계
7-1. OpenAI
response_format={"type": "json_schema", "strict": true}로 schema enforcement 지원. GPT-4o 이상 권장. enum, nested object, required 모두 지원.
7-2. Anthropic Claude
직접 schema enforcement는 tool use 기능을 통해 우회. 도구 input schema가 그대로 응답 형식이 됩니다. Claude는 자유 텍스트 답변 능력이 뛰어나니, 산문 단계는 Claude, schema 단계는 OpenAI 식으로 모델을 분리해 쓰는 팀도 있습니다.
7-3. 오픈소스 모델
llama.cpp의 grammar mode, vLLM의 guided decoding 등이 표준. 모델 자체에 schema 학습이 안 되어 있어도 디코딩 단계에서 강제 가능. 자체 호스팅 환경에서 비용 절감하면서 schema 안정성 확보.
7-4. 한계
strict mode가 강하면 모델이 답을 못 만들고 멈추거나, 모든 필드를 안전한 기본값으로 채워 정보가 빈약해질 수 있습니다. enum 값이 너무 많으면(10+) 모델 정확도가 떨어집니다. 6개 이내로 유지하는 게 일반적입니다.
8. 자유 산문과 strict의 두 단계 흐름
복잡한 자동화에서는 한 단계 호출로 끝내기 어렵습니다. 두 단계로 나누는 패턴이 표준이 되어가고 있습니다.
1단계 (strict): 입력 데이터 → schema에 맞는 JSON 추출 2단계 (free): 1단계 JSON → 자유 산문 보고서
예시: 광고 운영 일일 보고서 자동화
- 1단계: 캠페인 데이터에서
top_3_campaigns,roas_change,anomaliesschema 추출 (strict) - 2단계: 그 schema 데이터를 바탕으로 “오늘의 운영 한 줄 요약” 자유 산문 작성
두 단계를 분리하면 1단계가 안정적인 기반이 되고, 2단계의 자유도가 안전하게 살아납니다. LLM 비용도 1단계는 작은 모델, 2단계는 큰 모델로 나눠 절감 가능. token economics는 LLM token economics 글을 참조.
9. 마치며 — 자동화의 안정성은 schema에서 시작
LLM 자동화의 운영 안정성은 프롬프트 엔지니어링이 아니라 schema 설계에서 시작합니다. 자유 텍스트로 받지 않고 strict JSON Schema로 받는 한 가지 결정만으로 자동화 파이프라인의 운영 사고가 절반 이상 사라집니다.
다음 분기에 한 번만 시도해 볼 만한 것은 사내 LLM 자동화 중 자유 텍스트로 받고 있는 자리를 찾아내 schema로 바꾸는 흐름입니다. 한 자리만 바꿔도 그 다음 자리들이 자연스럽게 따라옵니다.
다음에 읽을 글
- Function calling 설계 패턴 — 도구 호출이 사실 JSON Schema의 한 변형이라는 직관
- LLM as judge — 평가에서도 strict 출력이 평가 안정성을 만든다
- RAG 평가 — 평가 지표 자체를 strict schema로 받는 자리
참고
- OpenAI, “Structured outputs guide”: https://platform.openai.com/docs/guides/structured-outputs
- Anthropic, “Tool use for structured output”: https://docs.anthropic.com/en/docs/build-with-claude/tool-use
- JSON Schema, “Specification”: https://json-schema.org/
- Pydantic, “Models”: https://docs.pydantic.dev/latest/concepts/models/
- vLLM, “Guided decoding”: https://docs.vllm.ai/en/latest/usage/structured_outputs.html
AI·LLM 카테고리의 다른 글
전체 보기 →-
2026·05·16
LLM 운영 비용 폭주를 막는 6가지 guardrail — 마케팅 자동화의 cost·latency·품질 동시 관리
LLM을 운영에 올리면 어느 날 갑자기 비용이 10배로 튑니다. retry storm·프롬프트 폭증·모델 자동 승격·context 누적 등 폭주 패턴 6가지와 그것을 막는 guardrail을 정리합니다.
-
2026·05·10
LLM evaluation harness — 분기마다 챗봇 품질을 자동 평가하는 공장
챗봇·에이전트가 운영에 들어가면 한 번 평가가 아니라 분기 자동 평가가 필요합니다. 골든셋·regression·hyperparameter A/B를 묶는 evaluation harness 설계와 마케팅 자리에서의 적용.
-
2026·05·09
Context engineering — 200k 토큰 컨텍스트의 설계 원칙 5가지
컨텍스트 창이 200k 토큰까지 커졌지만 단순히 다 넣으면 lost-in-the-middle·비용 폭발·정확도 하락이 옵니다. 마케팅 자동화에 적용하는 5가지 컨텍스트 설계 원칙.
-
2026·05·09
Function calling 설계 패턴 — LLM이 도구를 부를 때 마케터가 점검할 것
LLM이 광고 API·BigQuery·Slack을 직접 부르기 시작하면, 답변 품질보다 "어느 도구를 언제 부를지"가 운영 사고의 진앙이 됩니다. function calling의 한 줄 직관과 마케터가 점검할 5가지.