광고 attribution 핵심 논문 7편 — Shapley부터 incrementality·MMM·DDA까지
어트리뷰션 도구가 내놓는 숫자 뒤에는 수십 년의 학술 계보가 있습니다. 협력 게임 이론의 Shapley value부터 MMM, incrementality, data-driven attribution까지 광고 기여도 측정의 뿌리가 된 논문 7편을 마케터 관점에서 정리했습니다.
어트리뷰션 도구의 화면에는 “이 채널이 매출의 32%에 기여했다” 같은 숫자가 떠 있습니다. 그 32%가 어떻게 나온 건지 물으면 답이 막히는 경우가 많습니다. last-click인지, 알고리즘이 나눈 건지, 실험으로 검증한 건지에 따라 같은 캠페인의 기여도가 두세 배 차이 납니다. 이 차이를 이해하려면 도구의 설정 화면이 아니라, 그 도구가 구현한 방법의 뿌리를 봐야 합니다.
광고 기여도 측정에는 수십 년의 학술 계보가 있습니다. 협력 게임 이론에서 출발한 공정 배분의 아이디어, 거시적 채널 기여도를 회귀로 푸는 전통, 그리고 그 모든 추정이 진짜 인과인지 묻는 실험적 접근까지. 이 글은 그 계보를 만든 논문 7편을 마케터 관점에서 정리합니다. 수식은 직관 위주로만 다루고, 각 논문이 실무 보고서의 어느 숫자를 떠받치는지에 초점을 둡니다.
왜 마케터가 원전을 봐야 하나
논문을 읽자는 제안에 거부감이 들 수 있습니다. 하지만 어트리뷰션은 벤더가 블랙박스로 파는 영역이라, 방법의 가정을 모르면 숫자에 끌려다니게 됩니다. 원전을 한 번 훑으면 도구가 어떤 가정 위에서 작동하는지, 그 가정이 깨지면 숫자가 어떻게 틀리는지를 가늠할 수 있습니다.
이 7편은 세 흐름으로 묶입니다. 기여도를 공정하게 나누는 배분의 계보(Shapley, data-driven attribution), 채널 효과를 거시적으로 추정하는 모델링의 계보(MMM, adstock과 saturation), 그리고 그 추정을 인과로 검증하는 실험의 계보(incrementality, geo experiment)입니다. 세 흐름은 경쟁이 아니라 보완 관계입니다.
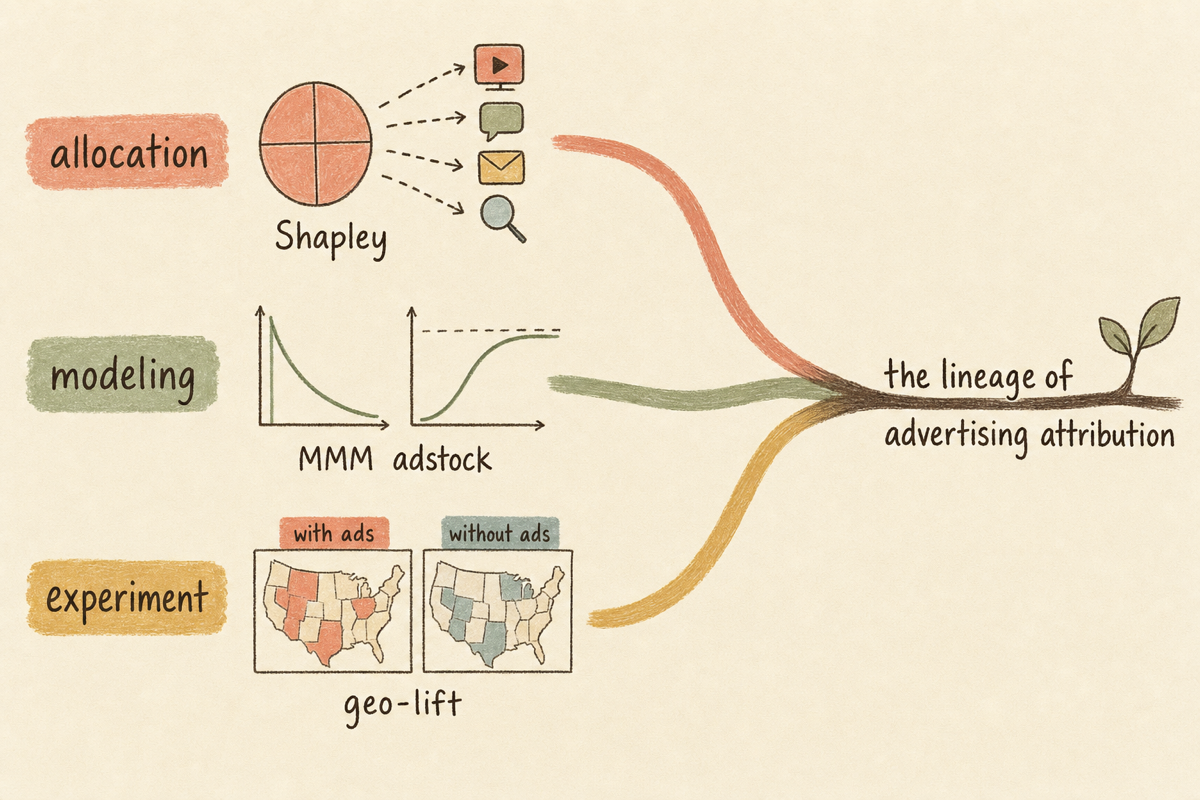
배분의 계보: 기여도를 어떻게 공정하게 나누나
1) Shapley (1953), 협력 게임의 공정 배분
attribution의 수학적 뿌리는 마케팅이 아니라 게임 이론입니다. Lloyd Shapley는 여러 참여자가 협력해 만든 성과를, 각자의 기여에 비례해 유일하고 공정하게 나누는 방법을 제시했습니다. 핵심 아이디어는 “이 참여자가 들어왔을 때 성과가 얼마나 늘었는가”를 모든 가능한 순서에 대해 평균 내는 것입니다.
마케팅 채널에 옮기면 이렇게 읽힙니다. 한 전환 경로에 검색, 디스플레이, 소셜이 모두 등장했을 때, 각 채널을 빼면 전환 확률이 얼마나 떨어지는지를 모든 조합에서 따져 평균합니다.
복잡해 보이지만 뜻은 단순합니다. 채널 의 기여도 는, 그 채널이 빠진 모든 채널 조합 에 대해 “를 더했을 때의 성과 증가분”을 가중 평균한 값입니다. last-click이 마지막 채널에 100%를 몰아주는 것과 달리, Shapley는 모든 채널에 기여한 만큼을 나눠줍니다.
2) Shao & Li (2011), data-driven attribution의 출발
Shapley가 이론이라면, Shao와 Li의 연구는 그것을 광고 로그 데이터에 적용한 초기 다중 터치 어트리뷰션의 기틀입니다. 이들은 전환한 경로와 전환하지 않은 경로를 비교해, 각 채널의 등장이 전환 확률을 얼마나 끌어올리는지를 데이터에서 추정하는 틀을 제안했습니다.
이 접근이 오늘날 플랫폼들이 말하는 data-driven attribution의 직계 조상입니다. 규칙으로 정한 배분(last-click, 선형)이 아니라, 실제 경로 데이터에서 패턴을 학습해 기여도를 나눕니다. 마케터가 알아둘 한계도 여기서 나옵니다. 이 방법은 관측된 경로의 상관에 기반하므로, 진짜 인과 효과와는 다를 수 있습니다. 그래서 다음 계보가 필요합니다.
모델링의 계보: 채널 효과를 거시적으로 추정하기
3) MMM의 고전, 마케팅 믹스와 매출 회귀
개별 유저의 경로를 추적하는 대신, 주간 또는 일간 단위의 채널별 지출과 매출을 회귀로 잇는 전통이 따로 있습니다. Marketing Mix Modeling입니다. 쿠키와 개별 추적이 가능해지기 한참 전부터, 마케팅 과학은 집계 데이터로 채널 기여도를 추정해 왔습니다.
MMM의 매력은 개별 추적에 의존하지 않는다는 점입니다. 프라이버시 규제로 유저 단위 추적이 어려워지면서, 이 오래된 방법이 다시 주목받고 있습니다. 한계는 집계 데이터의 한계 그대로입니다. 데이터 포인트가 적고, 채널 지출이 서로 움직여 효과를 분리하기 어렵습니다.
4) Adstock (Broadbid, 1979), 광고 효과는 지연되고 누적된다
MMM을 진지하게 만들려면 광고 효과의 두 가지 비선형성을 모델에 넣어야 합니다. 첫째가 adstock, 즉 carryover입니다. 오늘 본 광고는 오늘만이 아니라 며칠 뒤 구매에도 영향을 줍니다. 광고를 멈춰도 효과가 서서히 빠지는 잔향이 있습니다.
여기서 는 시점의 누적 광고 효과, 는 그 시점의 지출, 는 효과가 다음 기간으로 얼마나 넘어가는지를 정하는 감쇠율입니다. 가 클수록 광고의 잔향이 길게 남습니다. 이 한 줄이 “지난주 캠페인 효과를 이번주 매출에서 어떻게 잡느냐”는 마케터의 오랜 질문에 답합니다.
5) Saturation, 광고는 쓸수록 효율이 떨어진다
둘째 비선형성은 saturation, 수확체감입니다. 광고비를 두 배로 늘려도 매출이 두 배로 늘지 않습니다. 어느 지점을 넘으면 추가 지출의 효과가 급격히 줄어듭니다. 이걸 모델에 넣지 않으면, MMM은 “돈을 무한히 부으면 매출도 무한히 는다”는 비현실적 결론을 냅니다.
saturation 곡선은 마케터에게 가장 실용적인 산출물 중 하나입니다. 각 채널이 어느 지출 구간에서 효율이 꺾이는지를 보여주므로, 예산을 채널 간에 어떻게 재분배할지에 직접 쓸 수 있습니다. adstock과 saturation을 함께 넣은 MMM이 오늘날 PyMC-Marketing이나 Robyn 같은 도구의 핵심 구조입니다.
실험의 계보: 추정을 인과로 검증하기
6) Lewis & Rao (2015), 광고 효과 측정은 생각보다 훨씬 어렵다
앞의 다섯 논문이 기여도를 추정하는 방법이라면, 이 논문은 그 추정들에 찬물을 끼얹습니다. Lewis와 Rao는 대규모 온라인 광고 실험들을 분석해, 광고의 진짜 인과 효과를 통계적으로 잡아내는 일이 얼마나 어려운지를 보였습니다. 매출의 자연스러운 변동이 광고 효과보다 훨씬 커서, 어지간한 표본으로는 효과가 0인지 아닌지조차 구분하기 어렵다는 것입니다.
이 발견이 마케터에게 주는 교훈은 무겁습니다. 어트리뷰션 도구가 내놓는 정밀해 보이는 숫자가, 실제로는 통계적으로 구분 불가능한 노이즈 위에 서 있을 수 있다는 것. 그래서 관측 기반 추정만으로는 부족하고, 실험으로 검증하는 단계가 필요합니다.
7) Geo experiment (Vaver & Koehler, 2011), 도시를 나눠 인과를 본다
인과 검증의 가장 실용적인 형태가 geo experiment입니다. Google의 Vaver와 Koehler는 지역을 광고 노출군과 비노출군으로 나누고, 두 집단의 매출 차이로 광고의 증분 효과를 추정하는 방법을 정식화했습니다. 개별 유저를 추적하지 않고도, 지역이라는 단위로 무작위 실험에 가까운 구조를 만드는 것입니다.
이 방법이 오늘날 incrementality 측정과 geo-lift 실험의 토대입니다. 쿠키가 사라지는 환경에서 특히 가치가 큽니다. 유저 추적 없이도, 광고를 켠 지역과 끈 지역을 비교해 “이 광고가 진짜로 더 만든 매출”을 잴 수 있기 때문입니다. attribution이 추정한 기여도를 이 실험이 검증하는 구조가, 성숙한 측정 조직의 표준입니다.
세 흐름을 하나의 측정 체계로
이 7편을 따로 읽으면 일곱 개의 방법이지만, 묶어 읽으면 하나의 측정 철학이 됩니다. 배분은 채널 간에 공을 나누고, 모델링은 거시적으로 효과를 추정하며, 실험은 그 추정이 진짜인지 검증합니다. 어느 하나만으로는 부족합니다. 배분은 인과를 보장하지 못하고, 모델링은 데이터가 적으면 흔들리며, 실험은 모든 캠페인에 매번 돌릴 수 없습니다.
성숙한 조직은 이 셋을 역할 분담시킵니다. 일상 운영은 attribution과 MMM으로 보고, 중요한 의사결정 앞에서는 실험으로 검증합니다. 한 숫자를 맹신하지 않고, 세 방법이 비슷한 방향을 가리키는지를 봅니다. 방향이 어긋나면, 그 어긋남 자체가 무언가를 말해줍니다.
마치며
어트리뷰션 도구의 숫자를 읽는 일은 결국 그 숫자가 어떤 계보 위에 있는지를 아는 일입니다. last-click인지 Shapley 배분인지, 관측 상관인지 실험 인과인지. 이 7편을 한 번 훑어두면, 벤더가 파는 정밀해 보이는 숫자 앞에서 “이건 어떤 가정 위에 있나”를 물을 수 있게 됩니다.
그리고 그 질문이 어트리뷰션 리터러시의 출발점입니다. 숫자를 믿거나 안 믿는 게 아니라, 그 숫자가 답하는 질문이 무엇인지를 아는 것입니다.
참고
마케팅 리서치·논문 카테고리의 다른 글
전체 보기 →-
2026·06·21
SEO·GEO 학계 자료 6편 — GEO 논문부터 LLM 인용 연구·E-E-A-T 근거까지
GEO(Generative Engine Optimization)의 뿌리가 된 논문과 LLM 인용 패턴 연구, E-E-A-T 근거 자료 6편을 마케터 시선으로 해부합니다. ChatGPT·Perplexity가 무엇을 인용하는지, 무엇이 통하고 무엇이 안 통하는지 실측 숫자로 정리.
-
2026·06·10
실험·인과추론 논문 5편 — 마케팅 실험의 뿌리가 된 원전 가이드
Card&Krueger의 DiD부터 Synthetic Control, CUPED, peeking 문제, Switchback까지. 실험 도구 뒤에 있는 원논문 5편의 문제의식과 핵심 아이디어를 마케터 언어로 풀고, 어떤 순서로 읽을지 안내합니다.