Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
“B안이 A보다 좋을 확률 92%“라는 한 줄이 회의를 한 번에 정리합니다. 베이지안 A/B의 매력입니다. 그런데 그 92%라는 숫자가 정직하려면 prior를 어떻게 잡았는지, HDI를 어떻게 해석했는지가 함께 따라와야 합니다. 이 글은 마케터 시선에서 베이지안 A/B의 prior 설계, posterior 해석, HDI의 함정을 정리합니다.
마케터가 이 글을 읽어야 하는 이유: 빈도주의 A/B의 “p-value < 0.05”는 실무에서 늘 어색합니다. “그래서 B가 더 좋다는 거야 아니야?” 베이지안은 그 질문에 직접 답합니다. 다만 prior를 무심코 잡으면 답이 흔들리고, HDI를 단순 신뢰구간처럼 읽으면 의미가 깨집니다. 두 가지만 잘 잡으면 회의에서 의사결정 속도가 한 단계 올라갑니다.
1. 빈도주의 A/B와 베이지안 A/B의 한 줄 차이
| 항목 | 빈도주의 | 베이지안 |
|---|---|---|
| 답하는 질문 | ”이 차이가 우연일 확률은?" | "B가 A보다 좋을 확률은?” |
| 출력 | p-value, 신뢰구간 | posterior 분포, HDI |
| 해석 | ”기각/채택” 이분법 | ”어느 정도 더 좋은가” 연속적 |
| 표본 부족 자리 | 검출력 부족 | prior가 정보 보강 |
| 회의 친화도 | 낮음 (해석 어려움) | 높음 (확률로 직접 답) |
베이지안의 직관: 사전 믿음(prior)을 데이터로 갱신해 사후 믿음(posterior)을 만든다. posterior가 의사결정의 입력이 됩니다.
2. Prior 잡는 법 — 세 가지 표준 패턴
prior는 “데이터를 보기 전에 우리가 알고 있던 것”입니다. 마케팅 자리에 자주 등장하는 세 패턴을 보겠습니다.
2-1. 무정보 prior — 정보 없을 때
Beta(1, 1) (= 균등분포)는 “0과 1 사이 어디든 가능성 동일”을 의미합니다. 정보가 전혀 없을 때 안전한 출발점.
장점: 사전 편향 없음. 단점: 표본 작을 때 posterior가 흔들리기 쉬움.
2-2. 약한 정보 prior — 일반 상식 반영
Beta(2, 8)은 “전환율이 낮은 자리(평균 약 20%)에 약한 사전 정보”. 마케터가 “이 캠페인은 전환율이 보통 15-25% 사이”라는 상식이 있을 때 그 상식을 prior에 반영.
이런 prior는 데이터가 적을 때도 합리적인 posterior를 만들고, 데이터가 많아지면 prior 영향이 사라져 데이터가 답을 결정합니다.
2-3. 강한 정보 prior — 과거 데이터 활용
같은 캠페인의 작년 분기 데이터가 있으면, 그 데이터를 prior로 사용. 작년 분기에 1000명 중 250명 전환이라면 Beta(250, 750)을 prior로 잡습니다. 이게 베이지안 A/B의 가장 강력한 자리 — 과거 데이터가 사전 정보로 그대로 들어옵니다.
이번 분기 작은 표본만으로도 posterior가 안정적으로 추정됩니다.
| Prior 종류 | 표현 | |
|---|---|---|
| 무정보 | 1, 1 | ”아는 게 없음” |
| 약한 정보 | 2, 8 | ”전환율 약 20% 가정” |
| 강한 정보 | 250, 750 | ”작년 데이터로 신뢰” |
3. Posterior — 데이터로 갱신된 사후 분포
prior에 데이터가 들어가 posterior가 됩니다. Beta-Binomial 결합의 표준 결과:
는 성공 수(전환), 는 실패 수(비전환). 1000명 노출 250명 전환이라면 . prior가 Beta(2, 8)이라면 posterior는 Beta(252, 758). 마케터 직관: 사전에 가정한 알파·베타에 실제 관측치를 더한다. 데이터가 많을수록 prior 영향은 사라지고 posterior가 데이터에 수렴.
A/B 두 변형 모두에 같은 절차를 적용해 두 posterior , 를 얻습니다. 비교는 두 분포의 비교입니다.
4. “B가 A보다 좋을 확률” 계산
두 posterior에서 직접 샘플링해 비교합니다.
P(B > A) = posterior 샘플 중 B 샘플이 A 샘플보다 큰 비율
10000개 샘플을 두 분포에서 각각 뽑아 짝지어 비교한 비율이 그 확률. 92%면 “B가 A보다 좋을 확률 92%“라고 회의에서 한 줄로 답할 수 있음.
이게 빈도주의 p-value가 못 답하는 자리입니다. p-value는 “차이가 우연일 확률”이지 “B가 A보다 좋을 확률”이 아닙니다. 둘은 다른 질문입니다.
5. 코드 한 묶음 — Beta-Binomial Bayesian A/B
이게 글에 박는 유일한 코드입니다.
import numpy as npfrom scipy import stats
# 약한 정보 prior — 전환율 평균 약 20% 가정prior_a, prior_b = 2, 8
# 관측 데이터visitors_A, conversions_A = 1000, 240visitors_B, conversions_B = 1000, 280
# Posterior (Beta-Binomial 결합)posterior_A = stats.beta(prior_a + conversions_A, prior_b + visitors_A - conversions_A)posterior_B = stats.beta(prior_a + conversions_B, prior_b + visitors_B - conversions_B)
# 10000개 샘플로 P(B > A) 계산n = 10000samples_A = posterior_A.rvs(n)samples_B = posterior_B.rvs(n)prob_B_better = (samples_B > samples_A).mean()print(f"P(B > A) = {prob_B_better:.3f}") # 예: 0.927
# B의 95% HDIhdi_lo, hdi_hi = posterior_B.ppf(0.025), posterior_B.ppf(0.975)print(f"B의 95% HDI: ({hdi_lo:.3f}, {hdi_hi:.3f})") # 예: (0.253, 0.305)
# 상승 효과 lift = (B - A) / Alift_samples = (samples_B - samples_A) / samples_Aprint(f"기대 상승률: {lift_samples.mean()*100:.1f}%") # 예: 16.5%print(f"상승률 95% HDI: ({np.percentile(lift_samples, 2.5)*100:.1f}%, " f"{np.percentile(lift_samples, 97.5)*100:.1f}%)")회의 한 줄 결론: “B가 A보다 좋을 확률 92.7%, 기대 상승률 16.5% (95% HDI 5.2%-29.1%)“.
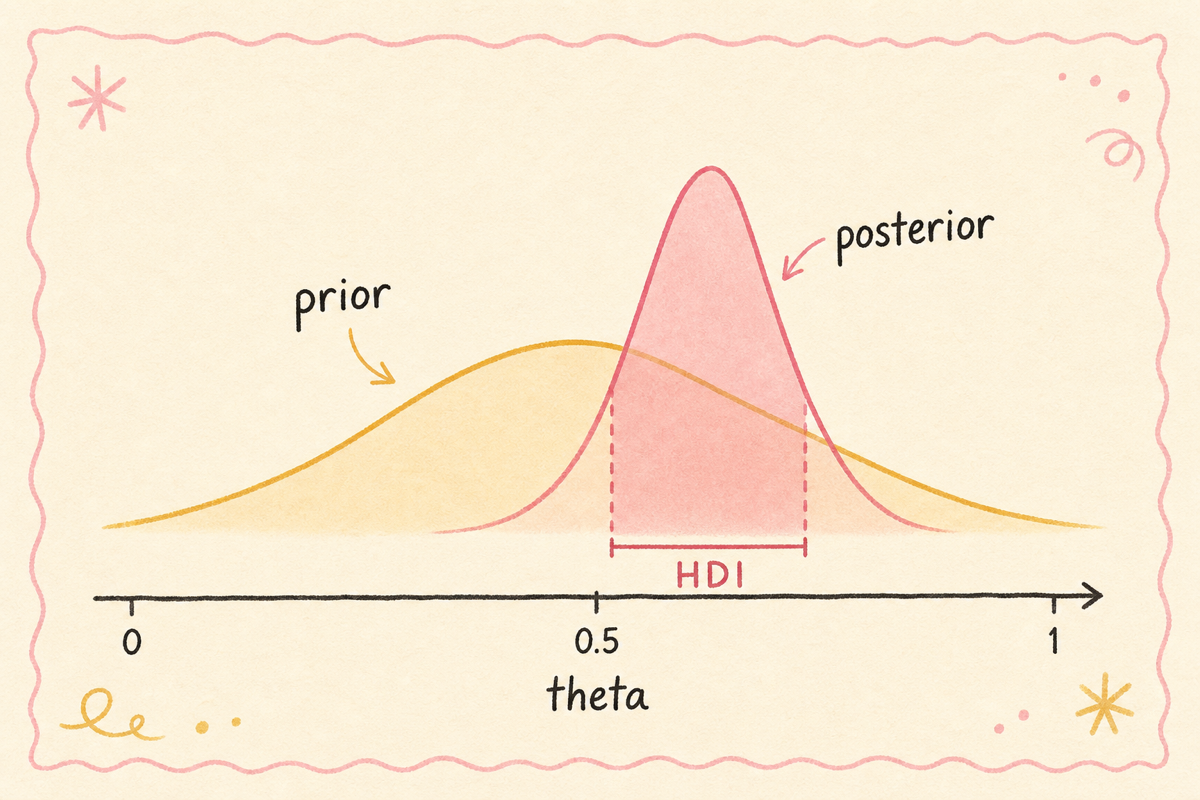
6. HDI(Highest Density Interval)의 정확한 의미
HDI는 빈도주의의 신뢰구간(CI)과 비슷하게 보이지만 의미가 다릅니다.
6-1. HDI의 정의
95% HDI: posterior 분포에서 확률 밀도가 가장 높은 영역, 누적 95% 차지하는 구간.
직관: posterior가 가장 두꺼운 부분 중심으로 95%를 잡는다. 그 결과 좁고 정확한 구간.
6-2. 빈도주의 신뢰구간과의 차이
| 항목 | 95% HDI | 95% 신뢰구간 |
|---|---|---|
| 해석 | ”참값이 이 구간에 있을 확률 95%" | "여러 번 표본 추출 시 구간이 참값 포함하는 비율 95%“ |
| 회의 친화도 | 직관적 | 비직관적 |
| 분포 비대칭 시 | 두꺼운 영역으로 이동 | 양쪽 꼬리 균등 |
마케팅 회의에서 직관적으로 받아들이기 좋은 건 HDI. 빈도주의 신뢰구간을 “참값이 이 구간에 있을 확률 95%“로 해석하면 통계학적으로는 틀린 해석이지만, HDI는 그렇게 해석해도 맞음.
6-3. HDI가 0을 포함하는가
A/B 비교에서 가장 중요한 질문: B-A의 95% HDI가 0을 포함하는가.
- 포함 안 함 (양수만) → B가 A보다 분명히 좋음
- 포함 (양·음 양쪽) → 차이가 불확실
- 음수만 → A가 더 좋음
이게 빈도주의의 “p < 0.05” 대체 룰. 단순하고 회의에서 바로 통하는 기준.
7. ROPE — 실무 의사결정의 또 한 줄
HDI만으로는 한 가지 함정이 있습니다. 큰 표본에서 “통계적 의미는 있지만 실무적 의미는 없는” 차이가 검출됩니다. 예: B가 A보다 0.1%p 높은데 표본이 매우 커서 P(B>A)가 99%.
ROPE(Region of Practical Equivalence)는 그 함정을 막는 도구.
ROPE: 실무적으로 무시할 만한 차이의 범위 (예: ±0.5%p). HDI 전체가 ROPE 안에 있으면 → “차이 없음” 결론 HDI 전체가 ROPE 밖에 있으면 → “유의미한 차이” HDI가 ROPE를 걸치면 → “결론 보류, 더 모음”
마케팅 자리: 전환율 차이의 ROPE를 ±1%p로 잡고, HDI가 그 범위 밖에 있어야 의미 있는 차이로 판단. 표본 폭증으로 작은 차이가 의미 있어 보이는 함정 방지.
| 결과 | HDI vs ROPE | 결론 |
|---|---|---|
| HDI 전체 ROPE 안 | ±0.3%p ⊂ ±1%p | 차이 없음 |
| HDI 전체 ROPE 밖 | +5%p ~ +12%p > +1%p | 의미 있는 개선 |
| HDI가 ROPE 걸침 | -0.5%p ~ +2%p | 결론 보류 |
8. 흔한 함정과 피하는 법
8-1. Prior 한 번도 점검 안 하기
기본 무정보 prior로 모든 실험을 돌리면 작은 표본에서 posterior가 이상한 자리에 갑니다. 분기에 한 번이라도 prior를 점검하고 약한 정보 prior로 업데이트.
8-2. P(B>A)만 보고 lift 안 봄
확률만 보면 차이의 크기를 모릅니다. P(B>A)=99%라도 기대 상승률이 0.1%면 운영적으로 의미 없음. 항상 함께 보고.
8-3. ROPE 없이 결론
큰 표본에서는 통계적·실무적 의미를 분리해야 합니다. ROPE 없이 결론 내면 표본 폭증으로 의미 없는 차이를 도입하게 됨.
8-4. 강한 prior로 데이터 누르기
작년 데이터를 너무 강하게 prior에 박으면 올해 데이터가 그 prior에 잘 못 박힙니다. prior에 들어가는 정보 양을 표본의 10-30% 수준으로 제한하는 게 일반 룰.
9. 마치며 — 회의 한 줄로 답하는 통계
베이지안 A/B의 가장 큰 가치는 회의에서 의사결정자가 듣고 싶은 형태로 답한다는 것입니다. “B가 A보다 좋을 확률 92.7%, 기대 상승률 16.5%, 95% HDI 5.2%-29.1%”. 이 한 줄이면 그 자리에서 결정할 수 있습니다. 다만 그 정직성이 prior와 HDI·ROPE 해석에 달려 있고, 이 두 가지를 분기에 한 번씩 점검하면 베이지안 A/B의 전 운영 사이클이 안정됩니다.
다음 분기에 한 번만 시도해 볼 만한 것은 가장 자주 돌리는 A/B 실험 자리에 약한 정보 prior와 ROPE를 도입해 빈도주의 결과와 베이지안 결과를 비교하는 흐름입니다. 같은 데이터에서 두 결과가 어떻게 다른지 직접 보면 다음 결정이 자연스러워집니다.
다음에 읽을 글
- 베이지안 어트리뷰션 — A/B에서 어트리뷰션으로 베이지안 직관 확장
- Sequential testing — 실험 도중 결과를 보면서 결정하는 베이지안 흐름
- CUPED 분산 축소 — 표본을 절반으로 줄이는 사전 데이터 활용법
참고
- Kruschke (2014), “Doing Bayesian Data Analysis”: https://sites.google.com/site/doingbayesiandataanalysis/
- Stan 문서, “Bayesian inference”: https://mc-stan.org/docs/
- “Bayesian A/B testing at VWO”: https://vwo.com/downloads/VWO_SmartStats_technical_whitepaper.pdf
- Gelman et al. (2013), “Bayesian Data Analysis (3rd ed.)”: http://www.stat.columbia.edu/~gelman/book/
- “ROPE for Bayesian decision making” (Kruschke 2018): https://link.springer.com/article/10.3758/s13423-016-1221-4
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.
-
2026·05·09
Power analysis와 MDE — 실험 시작 전에 표본·기간을 정직하게 잡는 법
A/B 시작 전 "표본 얼마나 모아야?"의 답이 power analysis. 검출력 80%로 검출 가능한 최소 효과(MDE)를 미리 계산해 실험 기간·해석 한도를 명확히 잡는 흐름.