Regression Discontinuity — 정책 cutoff 주변에서 인과 효과 잡기
쿠폰을 일정 점수 이상에게만 발급하면 그 cutoff 바로 위·아래 사용자들은 비슷한데 처리만 다릅니다. RDD가 그 자연 실험을 활용해 인과 효과를 추정합니다. 마케팅 자리의 적용과 함정.
“VIP 등급 이상에게만 쿠폰 발급” 같은 룰이 사실 자연 실험입니다. cutoff 바로 위 사용자(VIP)는 쿠폰을 받고, 바로 아래 사용자(일반)는 안 받습니다. 두 그룹은 자격 점수가 거의 같으니 다른 모든 면에서 비슷합니다 — 단 한 가지 다른 것이 쿠폰 처리 여부. RDD(Regression Discontinuity Design)는 이 자연 실험을 활용해 인과 효과를 추정합니다.
마케터가 이 글을 읽어야 하는 이유: 마케팅 운영의 많은 룰이 cutoff 기반(VIP 등급, 쿠폰 자격, 광고 배정 점수). 이 룰 자체가 자연 실험이라 RDD를 적용하면 별도 lift study 없이 인과 효과를 추정 가능. 무작위 배정 못 하는 자리의 강력한 우회로.
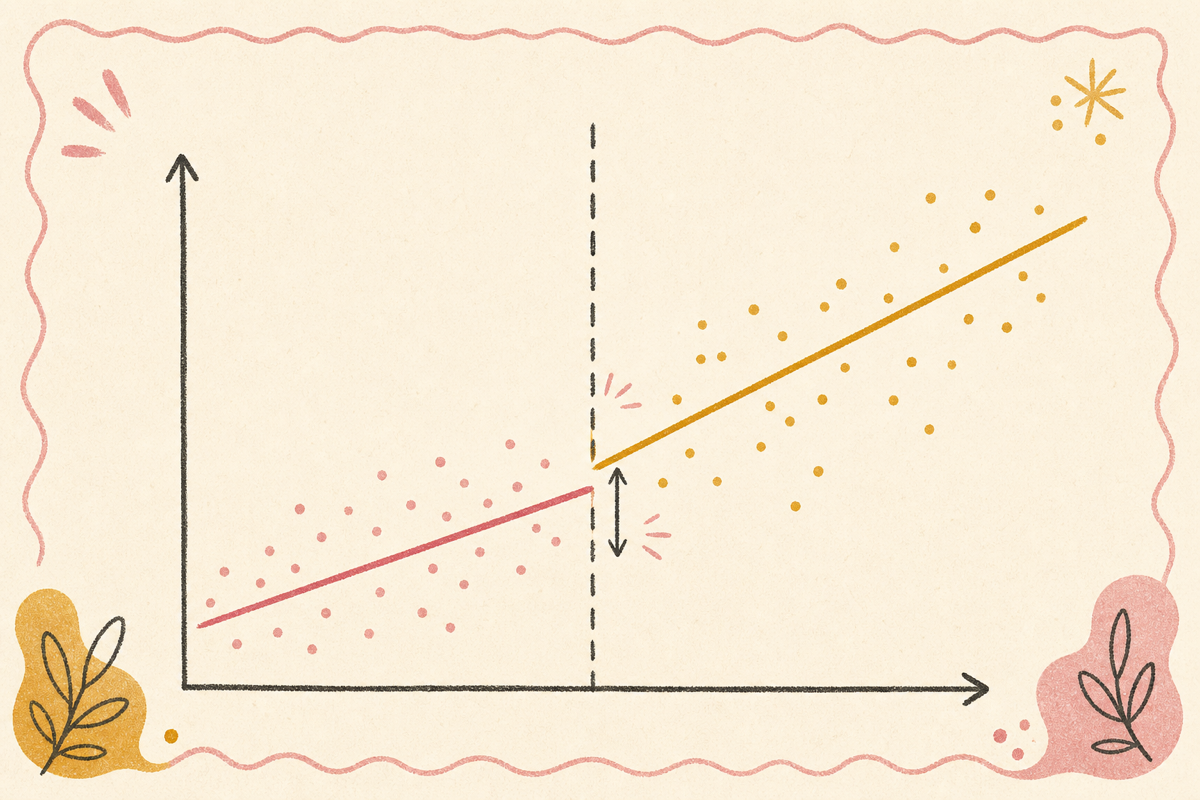
1. RDD의 한 줄 직관
자격 점수가 cutoff 바로 위·아래인 사람들은 거의 같은데, 한 그룹만 처리(쿠폰·할인)를 받는다. 두 그룹의 결과 차이가 처리 효과.
핵심: cutoff 근처에서는 자격 점수의 차이가 매우 작습니다. 점수 79.5 vs 80.5 사용자는 거의 비슷한 사람들입니다. 그런데 cutoff 80.0이 둘을 다른 처리 그룹에 배정합니다. 이게 사실상 무작위 배정과 같은 효과.
수식 직관:
는 자격 점수, 는 cutoff. cutoff 바로 위 평균과 바로 아래 평균의 차이.
2. Sharp RDD vs Fuzzy RDD
2-1. Sharp RDD
cutoff 위는 100% 처리, 아래는 100% 비처리. 룰이 정확히 지켜지는 자리.
예: “VIP 등급 이상에게만 쿠폰 자동 발급” → cutoff 정확히 일치.
2-2. Fuzzy RDD
cutoff 위라도 처리 받지 않는 사람·아래라도 처리 받는 사람이 섞여 있는 자리. 처리 확률이 cutoff에서 점프하지만 0/1이 아닌 자리.
예: “VIP 등급 이상에게 쿠폰 안내, 본인이 사용 결정” → 자격은 있지만 안 받는 사람 존재.
| 자리 | 처리 비율 | 추정 |
|---|---|---|
| Sharp | cutoff 위 100%, 아래 0% | 직접 차이 |
| Fuzzy | cutoff 위 60%, 아래 5% | IV·도구변수 활용 |
3. RDD가 적용되는 마케팅 자리 5가지
3-1. VIP·로열티 등급 기반 혜택
자격 점수 이상에게만 쿠폰·할인 자동 발급. 가장 흔한 RDD 자리.
3-2. 광고 배정 score cutoff
DSP·자동입찰의 사용자 score가 일정 수준 이상에서 광고 노출. cutoff가 명확하면 RDD 가능.
3-3. 신용 한도 결정
마케팅과 별개지만 fintech 자리. 신용 점수 cutoff가 한도 결정.
3-4. 신규 vs 기존 사용자 구분
가입 일자 기준 90일 이내 신규로 분류해 다른 캠페인 노출. 가입 후 89일·91일 사용자가 사실상 비슷.
3-5. 지역 배송 기준
매장 반경 5km 내 사용자에게 배송 무료. 4.9km vs 5.1km 사용자 비교.
| 자리 | cutoff 변수 | RDD 적용 |
|---|---|---|
| VIP 쿠폰 | 등급 점수 | Sharp |
| DSP score | 광고 점수 | Sharp |
| 가입 후 일자 | 일수 | Sharp |
| 거리 기반 배송 | km | Sharp |
| 자격 안내 | 점수 | Fuzzy |
4. RDD의 핵심 가정
4-1. Cutoff 주변의 연속성
cutoff에서 자격 점수 외 변수들이 매끄럽게 이어진다는 가정. cutoff에서 다른 변수(예: 가입 채널)도 동시에 점프하면 RDD 무너짐.
4-2. Manipulation 없음
사용자가 cutoff를 의도적으로 넘기 위해 점수를 조작하지 않아야 함. 예: 쿠폰 받으려고 인위적으로 구매 늘리기. McCrary density test로 점검.
4-3. Bandwidth 선택
cutoff 근처 어느 범위까지 데이터를 사용할지의 결정. 좁으면 정밀도 부족, 넓으면 cutoff 멀리 떨어진 사용자가 비교에 들어가 편향.
5. 코드 한 묶음 — Python RDD
이게 글에 박는 유일한 코드입니다. VIP 점수 cutoff 80에서 쿠폰 발급의 인과 효과 추정.
import numpy as npimport pandas as pdimport statsmodels.formula.api as smf
# df: vip_score, treated, outcome (cutoff 80)cutoff = 80.0bandwidth = 10 # cutoff ± 10 범위만 사용
# 1. cutoff 근처 데이터만 추출mask = (df["vip_score"] >= cutoff - bandwidth) & \ (df["vip_score"] <= cutoff + bandwidth)df_window = df[mask].copy()df_window["centered"] = df_window["vip_score"] - cutoffdf_window["above"] = (df_window["vip_score"] >= cutoff).astype(int)
# 2. local linear regression — cutoff 위·아래 다른 기울기 허용model = smf.ols("outcome ~ centered + above + centered:above", data=df_window).fit()print(model.summary().tables[1])
# 3. 인과 효과 = above 계수tau = model.params["above"]ci = model.conf_int().loc["above"]print(f"RDD 효과 (cutoff 위 vs 아래) = {tau:.4f}")print(f"95% CI: ({ci[0]:.4f}, {ci[1]:.4f})")
# 4. McCrary density test (간이 — 분포 점검)above_count = (df_window["vip_score"] >= cutoff).sum()below_count = (df_window["vip_score"] < cutoff).sum()print(f"cutoff 위·아래 표본 비율: {above_count}/{below_count}")# 비슷해야 manipulation 없음 (점수 조작 의심 신호)above 계수가 cutoff에서의 점프 = 인과 효과. 95% CI가 0을 포함하지 않으면 통계적으로 유의.
6. Bandwidth 선택의 트레이드오프
| Bandwidth | 표본 | 편향 | 분산 |
|---|---|---|---|
| 좁음 (±5) | 작음 | 적음 | 큼 |
| 중간 (±10) | 중간 | 중간 | 중간 |
| 넓음 (±20) | 큼 | 큼 | 작음 |
표준 룰: Imbens-Kalyanaraman optimal bandwidth 또는 cross-validation으로 자동 선택. R rdrobust, Python rdrobust 패키지가 표준.
7. RDD가 깨지는 흔한 자리
7-1. Manipulation
사용자가 cutoff를 넘기 위해 점수를 조작. 예: 쿠폰 받으려고 마지막 날 구매 폭주. cutoff 위·아래 표본 분포가 비대칭이면 의심.
7-2. 다른 룰의 동시 점프
cutoff 80에서 쿠폰 + 가격 등급 + 멤버십 혜택이 동시에 변경. 효과 추정이 한 가지로 분리 안 됨. cutoff에 한 가지 처리만 깔린 자리만 RDD 적용 가능.
7-3. Bandwidth 선택의 임의성
분석가가 결과 보고 bandwidth 조정하면 결과 부풀어짐. 사전 등록(preregister)이 표준 안전판.
7-4. 외부 타당성 한계
RDD는 cutoff 근처의 효과만 추정. 그 외 사용자(점수 50, 점수 95)에게 적용했을 때 효과가 같다고 보장 못 함.
8. 마케팅 보고에 가져갈 표 양식
| 항목 | 값 |
|---|---|
| 자격 변수 | VIP 점수 |
| Cutoff | 80.0 |
| Bandwidth | ±10 (Imbens-Kalyanaraman) |
| Cutoff 위 표본 | 4,200 |
| Cutoff 아래 표본 | 4,500 |
| 추정 효과 (구매율) | +3.2%p |
| 95% CI | (+1.8%p, +4.6%p) |
| McCrary density p-value | 0.42 (manipulation 없음) |
이 한 표가 회의에서 “쿠폰의 인과 효과 +3.2%p”를 정직하게 보고하는 표준 양식.
9. 마치며 — 자연 실험을 알아보는 눈
마케팅 운영의 룰이 사실 자연 실험인 자리가 의외로 많습니다. RDD는 그 자연 실험을 인과 효과 추정으로 변환하는 강력한 도구이고, 무작위 lift study가 어려운 자리에 우회로가 됩니다. 다만 핵심 가정(연속성, no manipulation, bandwidth 선택)을 매번 점검해야 결과의 정직성이 유지됩니다.
다음 분기에 한 번만 시도해 볼 만한 것은 운영 중인 cutoff 기반 룰 한 자리에 RDD를 적용해 효과를 추정하는 흐름입니다. 의외로 룰의 효과가 직관과 다를 때가 자주 있습니다.
다음에 읽을 글
- DiD 인과추론 — 시계열 자연실험
- Propensity score matching — 무작위 배정 안 되는 자리의 표준 도구
- Doubly robust estimation — 인과 추정의 안전 마진
참고
- Imbens & Lemieux (2008), “Regression discontinuity designs: A guide to practice”: https://www.sciencedirect.com/science/article/pii/S0304407607001091
- Lee & Lemieux (2010), “Regression discontinuity designs in economics”: https://www.aeaweb.org/articles?id=10.1257/jel.48.2.281
- McCrary (2008), “Manipulation of the running variable”: https://www.sciencedirect.com/science/article/abs/pii/S0304407607001133
- rdrobust (R, Python, Stata): https://rdpackages.github.io/rdrobust/
- Cattaneo, Idrobo & Titiunik (2019), “A practical introduction to RDD”: https://rdpackages.github.io/replication/
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.