Diff-in-Diff 인과추론 — 가격 인상·프로모션 종료의 진짜 효과를 분리하는 법
A/B 못 돌리는 마케팅 개입(가격 인상·프로모션 종료·UI 변경)의 진짜 효과를 어떻게 측정할까. 이중차분법(DiD)이 처리·대조군과 사전·사후 두 축을 동시에 빼주는 원리, 그리고 평행 추세 가정이 깨지면 무엇이 망가지는지.
“지난달 가격을 5% 올렸는데 매출이 빠졌어요. 가격 때문일까요, 시즌 때문일까요?” 이 질문에 A/B 테스트로는 답할 수 없습니다. 가격은 모든 유저에게 동시에 바뀌었고, 한 번 올린 가격은 되돌릴 수 없습니다. 이중차분법(DiD)은 “안 올렸으면 어땠을까”의 가짜 대조군을 시간축에서 만들어, 시즌 추세와 가격 효과를 분리해 줍니다. 마케팅 의사결정에서 가장 자주 써먹게 될 인과추론 도구를, 마케터 시각으로 풀어봅니다.
1. 마케터가 매일 부딪히는 문제 — “안 했으면 어땠을까”
A/B 테스트가 안 되는 마케팅 개입은 의외로 많습니다. 다음 세 가지는 누구나 한 번쯤 부딪힙니다.
- 가격을 5% 올렸다 — 카테고리 전체에 동시 적용. A/B로 절반은 올리고 절반은 안 올릴 수 없음
- 무료배송 임계값을 30,000원 → 50,000원으로 올렸다 — 운영상 두 정책을 동시에 굴릴 수 없음
- 앱 메인 화면을 리뉴얼했다 — 단계적 롤아웃이 가능하긴 하지만 코호트가 달라짐
이런 개입은 한 번 일어나면 되돌릴 수 없습니다. “올리기 전 4주 vs 올린 후 4주”를 비교하면 깔끔할 것 같지만, 그 사이에 시즌이 바뀌고 광고 예산이 바뀌고 경쟁사 프로모션이 떠 있을 수 있습니다. 단순한 사전·사후 비교로는 “가격 효과”와 “시간 효과”가 뒤섞입니다.
DiD는 이 뒤섞임을 떼어내는 가장 단순한 인과추론 도구입니다. 처리군과 대조군을 한 쌍 잡고, 두 그룹의 사전·사후 차이의 차이를 본다는 한 줄짜리 아이디어로 시간 추세를 자동으로 빼냅니다.
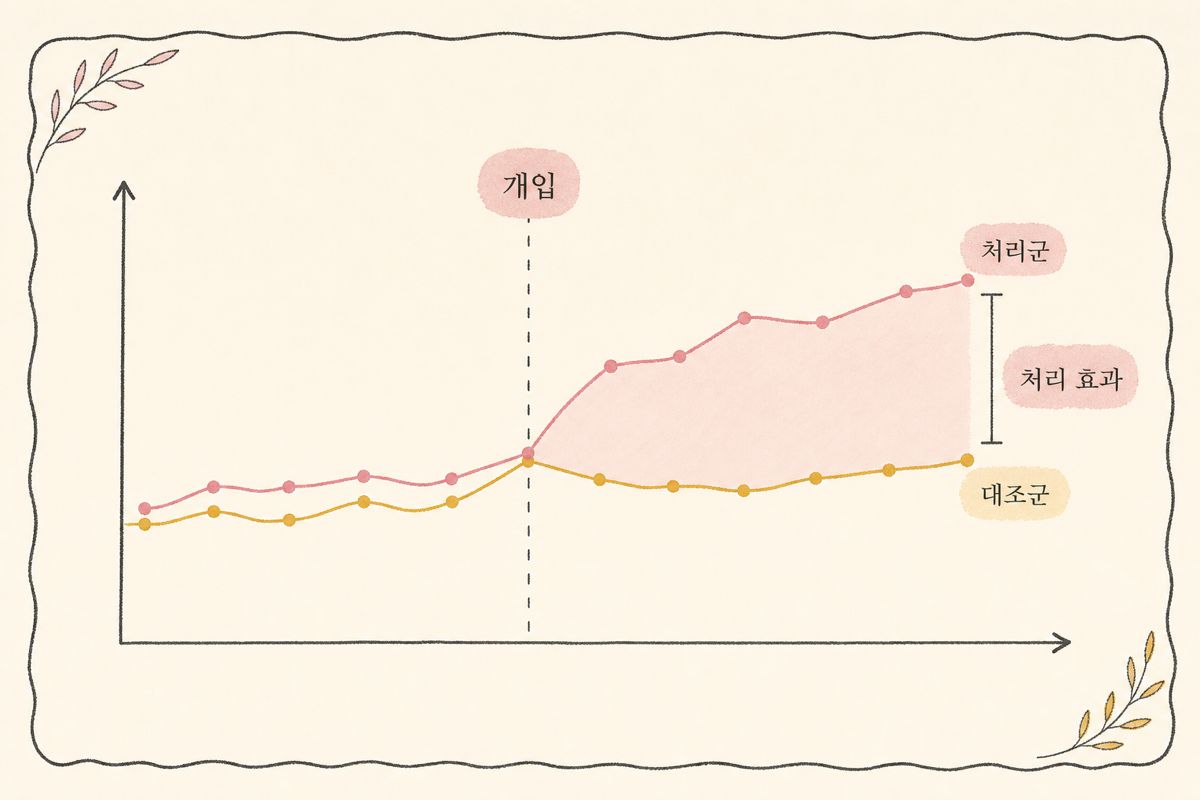
2. DiD의 직관 — 두 번 빼는 이유
DiD의 핵심 식은 한 줄입니다.
여기서 는 처리군(treated), 는 대조군(control), pre·post는 개입 전·후 평균입니다. 표로 보면 직관이 더 분명합니다.
| 그룹 \ 시점 | 사전(pre) | 사후(post) | 사전→사후 변화 |
|---|---|---|---|
| 처리군 (가격 5% 올린 카테고리) | 100 | 92 | -8 |
| 대조군 (가격 동결한 카테고리) | 100 | 95 | -5 |
| 차이의 차이 | — | — | -3 |
처리군은 8 만큼 빠졌고, 대조군은 5 만큼 빠졌습니다. 단순히 처리군의 -8을 가격 효과라고 보고하면 안 됩니다. 대조군도 5만큼 빠진 걸 보면 시즌·매크로 환경이 -5는 가져갔다는 신호이기 때문입니다. 그 5를 빼면 가격 인상이 만든 추가 손실은 -3으로 추정됩니다.
이게 DiD의 전부입니다. 처리군의 사전·사후 차분에서 “같은 기간 동안 대조군이 자연스럽게 움직인 만큼”을 한 번 더 빼는 것. 두 번 빼기 때문에 “이중(double)” 차분(diff-in-diff)입니다.
3. 평행 추세 가정 — DiD의 심장
DiD가 작동하려면 단 하나의 가정이 성립해야 합니다.
처리가 일어나지 않았다면, 처리군과 대조군은 사전 시점부터 사후 시점까지 평행하게 움직였을 것이다.
이걸 평행 추세 가정(parallel trends assumption)이라고 부릅니다. 두 그룹의 절댓값이 같을 필요는 없습니다. 처리군 매출 1,000만 원, 대조군 매출 200만 원이어도 됩니다. 둘이 같은 기울기로 움직였을 거라는 가정이면 충분합니다.
문제는 이 가정이 본질적으로 검증 불가능하다는 점입니다. “처리가 안 일어났을 때의 처리군 추세”는 실제로는 관측되지 않습니다. 그래서 평행 추세는 데이터로 증명하는 게 아니라, 데이터로 의심해보고 의심이 들지 않을 때까지 가정으로 받아들이는 것에 가깝습니다.
평행 추세가 깨지는 시나리오는 크게 세 가지입니다.
3-1. Ashenfelter dip — 처리 직전에만 처리군이 푹 꺼진다
Ashenfelter(1978)가 직업 훈련 프로그램에서 발견한 현상으로, 처리 직전에 처리군이 일시적으로 나빠진 뒤 처리 시점에 다시 회복합니다. 마케팅으로 옮기면 “프로모션을 끝내기 직전 1~2주 매출이 푹 꺼진다”가 비슷한 패턴입니다. 종료를 알린 시점부터 사재기·관망이 일어나기 때문입니다. 이 dip을 못 보면 종료 효과를 과장합니다.
3-2. 선택 편의 — 처리·대조군이 애초에 다른 길을 가고 있었다
가격을 올린 카테고리는 “올려도 버틸 만한” 카테고리였을 가능성이 큽니다. 대조군으로 잡은 카테고리는 “민감해서 못 올린” 카테고리일 수 있습니다. 두 그룹은 사전부터 다른 추세를 가졌을 수 있고, DiD는 그 차이까지 효과로 잡아냅니다.
3-3. 외부 충격 — 처리 시점에 다른 일이 동시에 벌어졌다
가격을 올린 그 주에 경쟁사가 신규 광고를 쏘기 시작했다거나, 같은 카테고리에 대형 신상품이 출시됐다면 DiD는 그 효과까지 가격 탓으로 돌립니다. 이건 사전 추세를 아무리 봐도 잡히지 않습니다. 사후 외부 이벤트 로그를 따로 모아 같이 봐야 합니다.
4. 회귀식으로 푸는 DiD — 표준오차까지 한 묶음
직관은 단순한 차분이지만, 실무에서는 회귀로 푸는 게 표준입니다. 표준오차·신뢰구간·공변량 보정을 한 번에 처리할 수 있기 때문입니다.
각 변수의 의미는 단순합니다.
- — 처리군이면 1, 대조군이면 0 (그룹 더미)
- — 사후 시점이면 1, 사전 시점이면 0 (시점 더미)
- — 처리군 × 사후 시점 교차항. 처리군에만, 사후에만 1이 됨
- — 우리가 보고 싶은 처리 효과. 교차항의 계수
마법은 마지막 줄에 있습니다. 가 정확히 §2에서 손으로 계산한 차이의 차이와 같습니다. 은 그룹 간 평균 차이, 는 시점 간 평균 차이를 흡수해 가고, 남은 처리 효과만 에 떨어집니다.
import statsmodels.formula.api as smf
# df: ['unit', 'time', 'y', 'treated', 'post'] 컬럼을 가진 패널 데이터model = smf.ols('y ~ treated + post + treated:post', data=df).fit( cov_type='cluster', cov_kwds={'groups': df['unit']})print(model.params['treated:post'], model.bse['treated:post'])이게 본문에 박는 유일한 코드입니다. 회귀 한 줄로 점추정과 표준오차가 같이 나옵니다. 마지막 한 가지만 챙기면 됩니다 — 클러스터드 표준오차(cov_type='cluster')입니다. 같은 유닛(같은 카테고리, 같은 도시, 같은 유저)의 시점 간 관측치는 독립이 아닌데, 이걸 무시하면 표준오차가 인위적으로 작아져 p-value가 거짓으로 작아집니다. Bertrand·Duflo·Mullainathan(2004)이 정리한 고전적 함정입니다.
5. 평행 추세가 깨질 때 — 사전 추세 검정·사건 시간 그래프
§3에서 가정을 의심하라고 했는데, 의심은 어떻게 하나요. 가장 단순한 도구는 사건 시간(event-time) 그래프입니다. 처리 시점을 0으로 두고, 음수 시점(사전)·양수 시점(사후)별로 처리군·대조군의 평균을 그립니다.
좋은 그래프가 보여줘야 할 것은 두 가지입니다.
- 음수 시점에서 두 선이 평행하게 움직인다 — 평행 추세 방증
- 양수 시점에서 처리군 선만 위(또는 아래)로 벌어진다 — 처리 효과의 시각적 증거
조금 더 형식을 갖추고 싶다면 사건 시간 회귀(event-study regression)를 씁니다. 처리 시점 기준 상대 시간 별로 더미를 두고 그룹 더미와 교차합니다.
여기서 는 유닛 고정효과, 는 시점 고정효과, 는 처리 시점 대비 상대시간 의 효과입니다. 보통 을 기준선으로 두고 정규화합니다. 음수 의 가 0 근처에 머물면 평행 추세 방증, 양수 에서 0과 멀어지면 처리 효과의 동학(dynamics)을 보여줍니다.
6. 마케팅 실무 케이스 3개 — 어떻게 처리·대조를 잡는가
DiD를 실무에 적용할 때 가장 어려운 건 수식이 아니라 처리·대조군을 어떻게 정의하느냐입니다. 같은 회사 안에서 자연 실험에 가까운 분리를 만들 수 있는지가 핵심입니다.
6-1. 가격 5% 인상 → 매출 변화
- 처리군: 가격을 올린 카테고리 (예: 가공식품)
- 대조군: 같은 시즌 영향을 받지만 가격을 그대로 둔 인접 카테고리 (예: 신선식품)
- 사전: 인상 전 8주의 일별 매출
- 사후: 인상 후 8주의 일별 매출
- 주의: 두 카테고리가 대체재 관계라면 가격 인상이 대조군 매출을 끌어올려 효과가 과장됩니다(spillover). 이런 경우 동일 카테고리의 다른 지역·다른 채널을 대조로 잡는 게 더 안전합니다.
6-2. 무료배송 임계값 30,000원 → 50,000원
- 처리군: 정책이 바뀐 지역의 유저
- 대조군: 동시기 정책이 그대로인 지역의 유저
- 사전·사후: 변경 전후 4~6주
- 메트릭: 평균 객단가, 주문당 GMV, 첫 주문 도달율
- 주의: 지역별 유저 구성이 다르면 단순 DiD가 어렵습니다. 사전 추세부터 그려서 평행한지 확인하고, 평행하지 않다면 propensity score 매칭으로 비슷한 유저 풀을 먼저 추리는 단계가 들어갑니다.
6-3. 앱 UI 리뉴얼 → 7일 리텐션
- 처리군: 단계적 롤아웃에서 새 UI를 받은 코호트
- 대조군: 같은 시점에 새 UI를 아직 못 받은 코호트
- 사전·사후: 사전은 양 코호트 모두 구 UI일 때 4주, 사후는 처리 코호트만 신 UI인 4주
- 주의: 단계적 롤아웃은 보통 무작위가 아닙니다. 베타 테스트군은 능동 유저일 수 있고, 새 OS만 받은 유저일 수도 있습니다. 코호트 간 사전 리텐션이 평행하지 않으면 DiD 추정치가 망가집니다.
7. DiD vs Geo-lift vs Synthetic Control vs A/B — 언제 무엇을 쓰나
마케팅에서 인과 효과를 측정하는 도구는 한 종류가 아닙니다. 비교표로 정리합니다.
| 도구 | 처리 단위 | 핵심 가정 | 데이터 요건 | 마케팅 케이스 |
|---|---|---|---|---|
| A/B 테스트 | 유저·세션 | 무작위 배정 | 동시 두 군 운영 가능 | 광고 소재, UI 카피 |
| DiD | 유닛(카테고리·지역·코호트) | 평행 추세 | 처리·대조군 사전·사후 패널 | 가격 변경, 정책 변경, UI 리뉴얼 |
| Geo-lift | 도시·지역 | 합성 대조 가능 | 다수 지역의 시계열 | TV·OOH·오프라인 매장 |
| Synthetic Control | 단일 처리 유닛 | 가짜 대조군 합성 가능 | 후보 대조 풀 충분 | 단일 도시 캠페인, 경쟁사 사례 |
같은 질문에 두 도구가 모두 적용 가능한 경우도 많습니다. 그럴 때는 가정의 부담이 작은 쪽을 선호합니다. A/B를 돌릴 수 있으면 A/B가 1순위, 그게 안 되면 DiD, DiD가 안 되면 Geo-lift나 Synthetic Control 순입니다. 다만 단일 처리 유닛(예: 서울에서만 캠페인 했다)이면 DiD보다는 Synthetic Control이 자연스럽습니다.
geo-lift 글에서 더 자세히 다룬 합성 대조군 이야기는 Geo-lift 실험으로 인과추론을 함께 읽으면 좋습니다. 5편 시리즈의 마지막 글에서 두 축(시간·공간)을 결합한 Synthetic DiD를 다시 다룰 예정입니다.
8. 마치며 — DiD를 의사결정에 도입할 때 한 가지 원칙
DiD를 마케팅 의사결정에 처음 도입할 때 가장 자주 부딪히는 함정은 회귀가 아니라 대조군 정의입니다. 처리군은 명확한데, 대조군이 너무 비슷해서 spillover가 일어나거나 너무 달라서 평행 추세가 안 맞는 경우가 대부분입니다. 회귀를 돌리기 전 사건 시간 그래프부터 그리고, 평행이 의심되면 회귀 결과를 보고서에서 빼는 결단도 필요합니다.
또 하나 — DiD의 추정치는 점추정 + 표준오차 + 평행 추세 검증 그래프가 한 묶음으로 가야 합니다. 셋 중 하나라도 빠진 보고서는 의심받아야 합니다. 마케터가 인과추론 보고서를 받을 때 가장 먼저 물을 질문은 “이 추정치의 클러스터드 표준오차는 얼마인가요?”가 아니라 “사전 추세 그래프를 보여주세요”가 되어야 합니다.
다음 글에서는 같은 마케팅 데이터에 분포 가정 없이 신뢰구간을 붙이는 도구, Conformal Prediction을 다룹니다. DiD가 “효과의 평균”을 다룬다면, Conformal은 “다음 한 건의 예측에 보증을 붙이기”의 도구입니다.
참고
- Card & Krueger (1994), Minimum Wages and Employment, AER — DiD를 마케팅·노동경제 양쪽의 표준 도구로 자리잡게 한 자연실험
- Bertrand, Duflo & Mullainathan (2004), How Much Should We Trust Differences-in-Differences Estimates?, QJE — 클러스터드 표준오차의 중요성
- Goodman-Bacon (2021), Difference-in-differences with variation in treatment timing — staggered DiD에서 TWFE의 한계
- Roth, Sant’Anna, Bilinski & Poe (2023), What’s trending in difference-in-differences? — 2020년대 DiD 논쟁의 종합 리뷰
- Arkhangelsky et al. (2021), Synthetic Difference-in-Differences, AER — DiD와 Synthetic Control의 결합
- Brodersen et al. (2015), Inferring causal impact using Bayesian structural time-series models — 구글의 CausalImpact 라이브러리, DiD의 베이지안 친구
- huny.log 내부 글: Geo-lift 실험으로 인과추론 — 광고 안 한 도시와 비교하기
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.