Geo-lift 실험으로 인과추론 — 광고 안 한 도시와 비교하기
TV·OOH·오프라인 매장처럼 A/B 테스트가 안 되는 채널의 진짜 효과를 어떻게 측정할까. 도시·지역 단위 실험과 합성 대조군(Synthetic Control)으로 인과 효과를 분리하는 법.
“TV 광고비가 분기당 5억인데, 정말 효과가 있는 거 맞아요?” — 임원이 회의에서 던지는 이 질문, 사실 답하기가 진짜 어렵습니다. 디지털처럼 사용자 단위 A/B를 못 돌리거든요. 그래서 마케터가 갖고 있는 가장 강력한 카드가 geo-lift 실험이에요. 도시 단위로 광고를 ON/OFF로 갈라서 진짜 인과 효과를 본다는 발상. 이 글은 그 실험의 직관과, 짝꿍처럼 따라오는 합성 대조군(Synthetic Control)의 핵심을 마케터 언어로 풀어봅니다.
왜 인과추론이 필요한가 — 상관과 인과 사이
마케터 보고서에서 흔히 보는 그림: “TV 광고를 켠 주에 매출이 +12% 올랐어요.” 이 한 줄은 사실 상관일 뿐이에요. 같은 주에 시즌 효과가 겹쳤거나, 경쟁사가 캠페인을 줄였거나, 그냥 경기가 좋았을 수도 있어요.
인과 효과(causal effect)는 다음 질문의 답이에요. “같은 시점에, 그 광고가 없었다면 매출은 얼마였을까?” — 이걸 counterfactual(반사실)이라고 부릅니다. 이 답을 알아야 비로소 “광고 덕분에 +X억”이라고 말할 수 있어요.
문제는 한 도시에 광고를 켠 그 시점, 같은 도시에서 광고 안 켠 버전의 매출은 절대로 관측할 수 없다는 거예요(이걸 “인과추론의 근본 문제”라고 합니다). 그래서 우리는 다른 곳에서 비슷한 도시들을 끌어와 가짜 대조군을 만듭니다. 그게 geo-lift + synthetic control입니다.
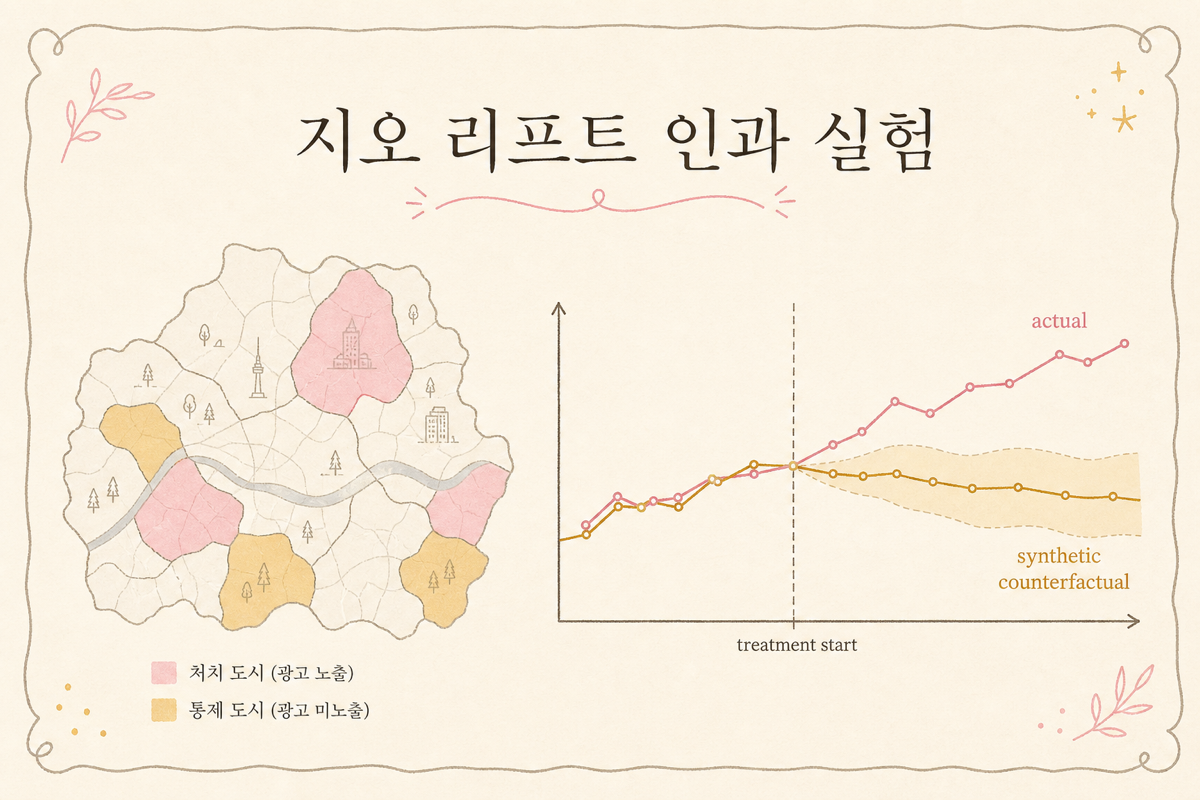
Geo-lift 실험의 기본 구조
1) 도시 그룹 짜기
전국 17개 시도, 또는 250여 개 시군구를 후보로 두고 두 그룹으로 나눕니다.
- Treatment 그룹: 실험 기간 동안 광고를 켜는 도시들 (예: 서울, 부산, 대구)
- Control 그룹: 같은 기간 광고를 안 켜는 도시들 (예: 인천, 광주, 대전)
여기서 핵심: 두 그룹이 실험 시작 전 매출 추세가 비슷해야 합니다. 그래야 “원래 같이 움직였을 텐데, 광고 켠 쪽만 더 올랐다”는 비교가 가능해요.
2) 사전 기간(pre-period) — 추세 매칭
실험 시작 전 3~6개월의 도시별 일매출을 보면서, 추세가 비슷한 도시들끼리 묶습니다. 단순 매출 절대값이 아니라 추세(상승률, 시즌 패턴)가 매칭되어야 해요.
도시 간 매출 추세 유사도는 피어슨 상관계수로 봅니다. 사전 기간 일매출의 상관계수가 1에 가까울수록 추세가 잘 맞는다는 뜻.
| 도시 | 서울과의 상관계수 |
|---|---|
| 서울 | 1.000 (본인) |
| 부산 | 0.962 |
| 대구 | 0.948 |
| 인천 | 0.941 |
| 광주 | 0.927 |
| 대전 | 0.903 |
실무 임계: 상관 0.9 이상이면 매칭이 잘 된 편. 0.8~0.9는 보정해서 쓸 만, 0.8 미만이면 합성 대조군의 기반이 흔들리니 control 후보에서 제외하세요.
3) 실험 기간(treatment period)
보통 4~8주. 너무 짧으면 노이즈에 묻히고, 너무 길면 다른 외부 변수가 끼어듭니다. 광고는 treatment 그룹 도시에만 노출하고, control은 평소대로 둠.
4) 결과 측정
실험 끝나고 두 그룹의 매출 변화를 비교 — 다만 단순 차이가 아니라 합성 대조군(다음 절)을 써서 보정합니다.
합성 대조군(Synthetic Control) — 가짜 도시 만들기
geo-lift의 백미는 여기예요. “treatment 도시 = 서울”이라고 하면, 우리는 여러 control 도시의 가중평균으로 가짜 서울을 만듭니다.
- = 도시 의 가중치 (모두 0 이상, 합 = 1)
- 가중치는 사전 기간(pre-period)에서 가짜 서울 ≈ 진짜 서울이 되도록 학습
직관: “서울이 광고 안 켰다면 어떻게 움직였을까?”의 답을 다른 도시들의 조합으로 합성한다는 발상입니다.
이걸 자동화한 도구가 Google의 CausalImpact(R 원본 + Python 포팅)예요. 사전 기간·실험 기간·치료 도시·대조 도시를 넣으면 다음 같은 결과를 뱉습니다.
| 항목 | Average | Cumulative |
|---|---|---|
| Actual (실제 서울 매출) | 143.2 | 8,592 |
| Prediction (광고 안 켰다면) | 128.4 (s.d. 4.2) | 7,704 (s.d. 252) |
| 95% CI of prediction | [120.2, 136.5] | [7,212, 8,191] |
| Absolute effect (광고 효과) | 14.8 (s.d. 4.2) | 888 (s.d. 252) |
| Relative effect | +11.5% | +11.5% |
| 95% CI of effect | [+5.2%, +17.9%] | [+5.2%, +17.9%] |
| Posterior probability | 99.9% | 99.9% |
이 표를 마케터 언어로 옮기면:
- 실험 기간 서울 매출은 88.8억 (cumulative actual 단위 가정)
- 광고 안 켰다면 모델 예측은 77억 (95% CI: 72.1 ~ 81.9억)
- 차이 = 광고의 인과 효과 약 +11.5%, 95% 신뢰구간 [+5.2%, +17.9%]
- 효과가 진짜 0보다 클 확률 99.9% → 통계적으로 유의
마케터가 자주 빠지는 함정
1) Spillover — 옆 도시로 광고가 새는 경우
서울에 광고를 켰는데, 인천에 사는 사람이 페이스북에서 그 광고를 보고 산다면? 이건 control 그룹이 오염된 거예요. 광고를 도시 단위로 정확히 끄는 게 가능한가부터 점검해야 합니다.
- TV 지역방송, OOH(옥외), 지역 프로모션은 spillover 적음 (지역 단위 노출)
- 디지털 광고는 IP/인구통계 타겟팅 정확도에 따라 spillover 큼 → 충분한 거리(예: 인접 시군구는 control에서 제외) 두기
2) Pre-trend가 안 맞을 때
합성 대조군이 사전 기간에 진짜 서울을 잘 못 따라가면, 실험 결과를 신뢰할 수 없어요. CausalImpact는 이걸 “fit”이라는 점수로 알려주는데, 사전 기간 RMSE가 큰 경우 결과 보고를 보류해야 합니다.
3) 실험 기간이 짧음
4주 미만은 위험합니다. 광고 효과가 누적되기 전이거나, 일주일짜리 노이즈가 결과를 흔들 수 있어요. 보통 6~8주 권장.
4) Power 부족
“매출 분산이 커서 효과가 있어도 못 잡는” 케이스. 실험 전에 power analysis를 해야 해요. 직관 공식:
- = 사전 기간 주간 매출의 표준편차
- = 잡고 싶은 최소 lift의 절대값
매출 변동이 크고 보고 싶은 lift가 작을수록 더 많은 주가 필요. 예시: 사전 기간 매출 표준편차가 평균의 6%이고 5% lift를 잡고 싶다면, , 약 6주 필요. 5% 미만의 작은 lift를 잡고 싶다면 8주 이상 권장입니다.
어떤 채널에 쓸까 — 실무 가이드
| 채널 | A/B 가능? | Geo-lift 적합도 | 비고 |
|---|---|---|---|
| 검색광고 (SA) | ✅ 사용자 단위 | △ 굳이 안 함 | 키워드 ON/OFF로 충분 |
| 소셜 퍼포먼스 | ✅ Lift study | ◯ 보완 가능 | Meta Lift Study 자체 도구도 있음 |
| 유튜브·디스플레이 | △ 부분적 | ◎ 권장 | view-through 측정 한계 보완 |
| TV 광고 | ❌ | ◎◎ 거의 유일한 답 | 지역방송 단위 ON/OFF |
| OOH (옥외) | ❌ | ◎◎ 거의 유일한 답 | 지하철·버스·옥외 |
| 오프라인 매장 프로모션 | ❌ | ◎◎ 거의 유일한 답 | 매장 단위 실험 |
MMM과의 관계 — 사전(prior)을 보정하는 법
지난 글에서 다룬 MMM은 채널 효과를 추정하지만, 그 추정이 진실에 얼마나 가까운지 확신할 길이 없어요. Geo-lift 결과를 MMM의 사전으로 깔면 두 방법이 서로의 약점을 보완합니다.
가령 TV의 incremental ROAS가 geo-lift 결과 95% CI [1.8, 2.6]으로 나왔다면, 이 구간을 MMM의 사전 분포로 그대로 옮길 수 있어요.
(평균은 구간 중앙, 표준편차는 구간 폭을 ±1.96으로 나눈 값.)
이렇게 하면 MMM이 TV 채널을 추정할 때 “geo-lift가 본 진실”에 가깝게 끌려갑니다. 도메인 지식보다 강한 데이터 기반 사전이라, 의사결정의 견고함이 한 단계 올라가요. 다른 채널은 약한 사전(weak prior)으로 두고 데이터가 결정하게 하면 됩니다.
마치며
A/B 테스트는 근본적으로 디지털 채널의 무기입니다. 그 외의 영역 — TV, OOH, 오프라인 — 에서 인과 효과를 보고 싶다면 결국 도시·지역을 단위로 한 실험이 답이에요. Geo-lift + synthetic control은 그 실험을 정량적으로 마무리하는 표준 도구이고, 마케터가 보고서에서 “incrementality 11.5%, 95% CI [5.2%, 17.9%]“같은 한 줄을 들고 가면 의사결정의 신뢰도가 다른 차원으로 올라갑니다.
다음 글에서는 LLM으로 광고 카피를 양산하고 임베딩으로 사전 스코어링하는 운영 워크플로우를 다뤄볼게요.
참고
- Google CausalImpact (R) — Synthetic Control의 베이지안 구현
- pycausalimpact (Python 포팅) — 파이썬에서 동일 모델
- Meta GeoLift — Meta가 공개한 R 라이브러리, geo-lift 실험 설계·분석 통합
- Synthetic Control Methods (Abadie, 2010) — 합성 대조군 원전 논문
- Incremental Sales — Why Lift Studies Matter — Meta Research
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.