Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.
A/B 결과 “B안이 평균 +5%p 효과”라는 한 줄은 사실 평균값입니다. 어떤 사용자에게는 +20%p, 어떤 사용자에게는 -3%p일 수 있습니다. 평균만으로 결정하면 효과 큰 사용자에 못 집중하고, 효과 음수인 사용자도 똑같이 처리합니다. CATE(Conditional Average Treatment Effect)·uplift forest는 이 이질성을 추정해 정밀한 타겟팅을 가능하게 합니다.
마케터가 이 글을 읽어야 하는 이유: 같은 캠페인을 모든 사용자에게 동일하게 노출하는 시대는 지나갑니다. 효과가 큰 세그먼트에 집중하고 효과 없는 세그먼트는 제외하는 정밀 타겟팅이 ROAS의 다음 도약 자리. CATE 추정은 그 결정의 데이터 기반.
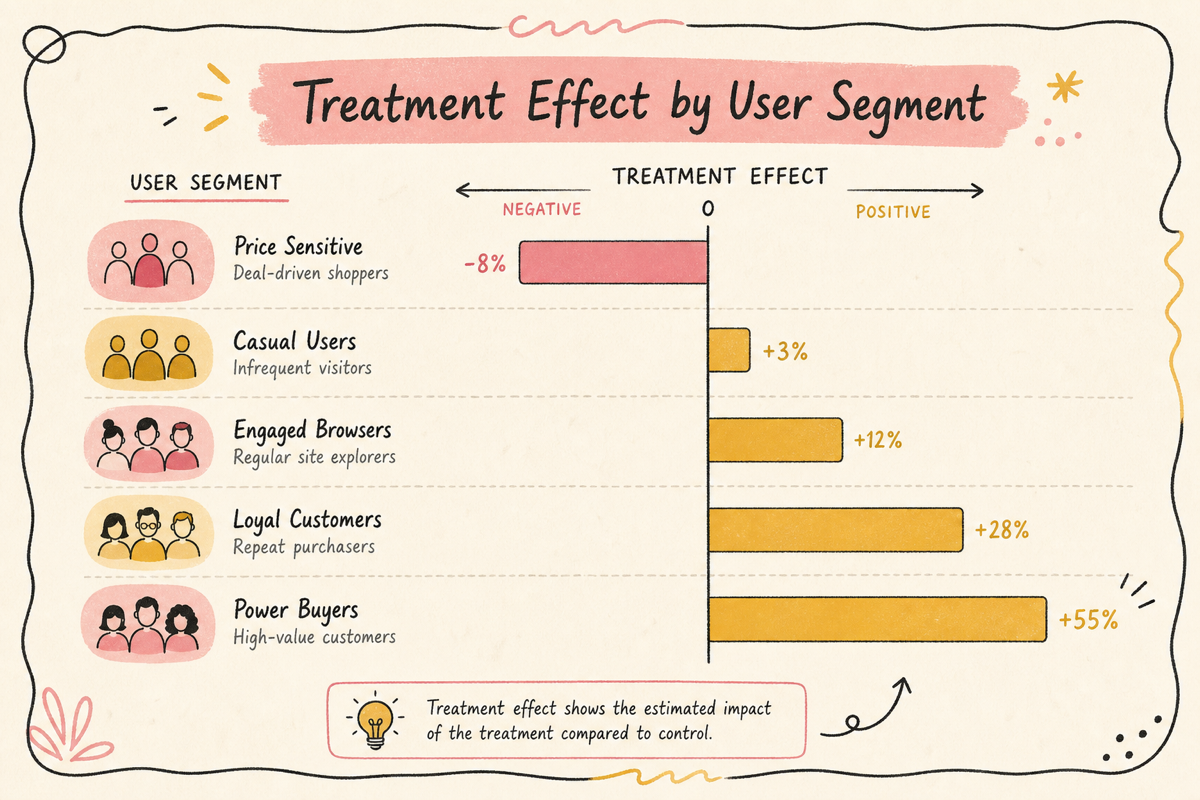
1. ATE에서 CATE로
평균 처리 효과(ATE):
전체 사용자에 평균한 효과. A/B 결과 “+5%p”가 이 값.
조건부 평균 처리 효과(CATE):
특정 특성 를 가진 사용자에게의 효과. 사용자별·세그먼트별로 다른 값.
| 사용자 X | CATE |
|---|---|
| 신규, 모바일, 20대 | +20%p |
| 기존, 데스크톱, 40대 | +2%p |
| VIP, 카테고리 A 선호 | +12%p |
| 비활성, 마지막 구매 90일+ | -3%p |
ATE 평균 +5%p는 이 분포의 평균에 불과. 분포를 보면 타겟팅 결정이 완전히 달라집니다.
2. Uplift modeling — CATE의 마케팅 언어
마케팅 자리에서 CATE를 부르는 더 흔한 단어가 uplift입니다.
처리 받았을 때의 결과 - 처리 안 받았을 때의 결과 = uplift
| 사용자 유형 | uplift | 마케팅 의미 |
|---|---|---|
| Persuadables | + | 광고로 설득 가능 — 타겟 1순위 |
| Sure things | 0 | 어차피 살 사람 — 광고 낭비 |
| Lost causes | 0 | 어차피 안 살 사람 — 광고 낭비 |
| Sleeping dogs | - | 광고가 오히려 역효과 — 광고 제외 |
마케팅 ROI의 핵심은 Persuadables를 찾고 Sleeping dogs를 제외하는 것. 평균 효과만 보면 둘이 섞여 결과가 흐려집니다.
3. CATE 추정 방법 3가지
3-1. Meta-learners (S/T/X-learner)
처리·비처리 별도 모델 학습 후 조합.
- S-learner: 처리 인디케이터를 feature로 단일 모델
- T-learner: 처리·비처리 두 모델 별도 학습
- X-learner: T-learner + 매칭으로 보정
가장 단순. sklearn 모델로 직접 구현 가능.
3-2. Causal Forest
Random Forest의 인과 추론 버전. 트리 분할 기준이 “효과가 가장 다른 자리”가 되도록 학습. CATE를 노드 단위로 추정.
3-3. Uplift Tree (Klassifier)
Two-step: (1) outcome 예측 (2) 그 예측 차이로 uplift 정렬. 단순하고 해석 가능.
| 방법 | 강점 | 약점 |
|---|---|---|
| Meta-learner | 단순, sklearn 호환 | 큰 모델 비용 |
| Causal Forest | 비선형 자동 잡음 | 학습 느림 |
| Uplift Tree | 해석 쉬움 | 정밀도 낮음 |
4. 코드 한 묶음 — EconML CausalForest
이게 글에 박는 유일한 코드입니다.
import numpy as npimport pandas as pdfrom econml.dml import CausalForestDMLfrom sklearn.ensemble import RandomForestRegressor, RandomForestClassifier
# df: T(처리), X(특성), Y(결과)features = ["age", "past_purchases", "visits_30d", "is_mobile", "segment"]X = df[features].valuesT = df["treated"].valuesY = df["outcome"].values
# Causal Forest 학습est = CausalForestDML( model_t=RandomForestClassifier(), model_y=RandomForestRegressor(), n_estimators=200, random_state=42,)est.fit(Y=Y, T=T, X=X)
# 사용자별 CATE 추정cate = est.effect(X)df["cate"] = cate
# 분포 확인print(f"평균 CATE: {cate.mean():.4f}")print(f"중앙값: {np.median(cate):.4f}")print(f"하위 25%: {np.percentile(cate, 25):.4f}")print(f"상위 25%: {np.percentile(cate, 75):.4f}")
# 효과 큰 사용자 추출 (Persuadables)persuadables = df[df["cate"] > df["cate"].quantile(0.7)]print(f"Persuadables 비중: {len(persuadables) / len(df) * 100:.1f}%")print(f"Persuadables 평균 CATE: {persuadables['cate'].mean():.4f}")
# Sleeping dogs (역효과)sleeping = df[df["cate"] < 0]print(f"Sleeping dogs 비중: {len(sleeping) / len(df) * 100:.1f}%")EconML의 CausalForestDML이 cross-fitting까지 자동. 사용자별 CATE 추정 후 상위 30%만 타겟팅하는 게 마케팅 ROI 개선의 표준 패턴.
5. CATE 활용의 마케팅 자리
5-1. 쿠폰 발급 결정
전체에 발급 vs CATE 상위 30%에만 발급. 후자가 ROAS 더 높음 (이미 살 사람에 쿠폰 안 줘서).
5-2. 광고 노출 우선순위
광고 예산 한도 안에서 CATE 상위 사용자에게 우선 노출. lift study 정밀화.
5-3. CRM 캠페인 발송 대상
이메일·푸시 발송 비용이 사용자당 작더라도 CATE 음수인 사용자 제외하면 unsubscribe 비율 감소.
5-4. Personalization 의사결정
CATE 분포가 넓으면 personalization 가치 큼. 좁으면 일률 처리가 효율적.
| 자리 | CATE 활용 |
|---|---|
| 쿠폰·할인 | 상위 30% 타겟팅 |
| 광고 노출 | 우선순위 정렬 |
| CRM 발송 | 음수 사용자 제외 |
| 콘텐츠 personalization | 분포 폭으로 가치 판단 |
6. CATE의 가장 큰 함정
6-1. Noise vs signal
CATE 추정은 분산이 큽니다. 작은 표본에서 추정하면 무작위 노이즈를 효과로 잘못 해석. 골든셋·holdout 검증 필수.
6-2. 추정 모델의 정직성
CATE 추정 모델 자체가 unmeasured confounder에 약함. 무작위 lift study 데이터로 추정하면 정직.
6-3. 일반화 한계
학습 데이터에서 추정한 CATE가 새 사용자에게 그대로 적용되지 않을 수 있음. 정기 재학습 필수.
7. CATE 검증 — Qini curve
CATE 모델의 품질을 측정하는 표준 지표. 사용자를 CATE 순으로 정렬한 뒤 상위 N%에게만 처리했을 때 누적 효과의 곡선.
Qini curve:- X축: 처리 비율 (0% → 100%)- Y축: 누적 효과- 무작위 처리: 직선- CATE 모델: 곡선이 위로 휘어짐 (좋음)곡선 아래 면적(AUUC) - 무작위 직선의 면적 = Qini coefficient. 클수록 CATE 추정이 정확.
from causalml.metrics import qini_score
qini = qini_score(df, treatment_col="treated", outcome_col="outcome", treatment_effect_col="cate")print(f"Qini score: {qini:.4f}")8. 분기 보고에 박을 표 양식
| 항목 | 값 |
|---|---|
| 평균 효과 (ATE) | +5.2%p |
| CATE 분포 | -2%p ~ +20%p |
| Persuadables 비중 (CATE 상위 30%) | 30% |
| Persuadables 평균 CATE | +14%p |
| Sleeping dogs 비중 (CATE < 0) | 8% |
| Qini score | 0.18 |
| 권장 타겟팅 룰 | 상위 30% + Sleeping dogs 제외 |
이 표가 회의에서 “전체 처리 vs 타겟 처리”의 ROI 비교를 데이터로 보여주는 표준 양식.
9. 마치며 — 평균 너머의 의사결정
마케팅의 다음 도약은 평균 효과 보고에서 개인별·세그먼트별 효과로 옮겨가는 자리에 있습니다. CATE·uplift forest로 효과의 이질성을 추정하면 Persuadables에 집중하고 Sleeping dogs를 제외해 ROAS의 한 단계 개선이 가능합니다. 다만 CATE 추정의 noise·일반화 한계를 점검하지 않으면 운영 사고로 이어집니다.
다음 분기에 한 번만 시도해 볼 만한 것은 가장 큰 캠페인 한 자리에 CATE 추정을 돌려 상위 30% vs 전체의 효과 차이를 holdout으로 비교하는 흐름입니다.
다음에 읽을 글
- Uplift modeling — CATE의 실무 활용
- Doubly robust estimation — CATE 추정의 안전 마진
- Propensity score matching — 처리 그룹 비교의 출발점
참고
- Wager & Athey (2018), “Estimation and inference of heterogeneous treatment effects”: https://www.tandfonline.com/doi/abs/10.1080/01621459.2017.1319839
- Künzel et al. (2019), “Metalearners for estimating heterogeneous treatment effects”: https://www.pnas.org/doi/10.1073/pnas.1804597116
- EconML: https://econml.azurewebsites.net/
- CausalML: https://causalml.readthedocs.io/
- “Uplift modeling in marketing” (Radcliffe & Surry, 2011): https://stochasticsolutions.com/pdf/sig-based-up-trees.pdf
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Power analysis와 MDE — 실험 시작 전에 표본·기간을 정직하게 잡는 법
A/B 시작 전 "표본 얼마나 모아야?"의 답이 power analysis. 검출력 80%로 검출 가능한 최소 효과(MDE)를 미리 계산해 실험 기간·해석 한도를 명확히 잡는 흐름.