CDP 시대의 ID 그래프 — 쿠키 없이 유저를 어떻게 잇나
3rd party cookie 종말과 iOS 14.5 이후 유저 식별이 어떻게 바뀌었는지, ID 그래프가 deterministic·probabilistic 매칭으로 어떻게 동작하는지 마케터 시각으로 정리.
“이 사람은 어제 모바일 앱에서 장바구니에 담았고, 오늘 데스크톱 웹에서 다시 들어왔어요.” 이 한 문장이 자연스럽게 들리려면 뒤에 많은 일이 일어나야 합니다. 모바일 앱의 광고 ID와 데스크톱 브라우저의 쿠키, 둘이 같은 사람이라는 사실을 어떻게 알 수 있나요? 3rd party cookie가 사라지는 시대에 이 질문의 답이 점점 어려워지고 있습니다. 이 글은 CDP 안에서 일어나는 ID 그래프의 동작을 마케터 시각으로 풀어봅니다.
1. 왜 이게 갑자기 어려워졌나 — 두 변곡점
2010년대 디지털 마케팅은 사실상 3rd party cookie가 모든 식별의 중심이었습니다. 한 사용자가 여러 사이트를 이동해도 쿠키 한 가닥으로 따라다닐 수 있었어요. 그런데 두 번의 큰 변화가 있었습니다.
- 2021년 4월 — iOS 14.5 / ATT(App Tracking Transparency): iOS 앱이 기기 광고 ID(IDFA)에 접근하려면 사용자에게 명시적 동의를 받아야 함. 동의율이 낮아 IDFA 가용성이 사실상 30% 안팎으로 떨어짐.
- 2024-2025년 — Chrome 3rd party cookie 단계적 폐기: 발표 후 여러 차례 일정이 바뀌었지만, 마케터 입장에선 “쿠키 의존을 줄여야 한다”는 방향성 자체는 명확.
이 두 변화의 결과로 크로스 사이트·크로스 디바이스 식별의 정확도가 급격히 떨어졌습니다. 같은 사람이 앱과 웹을 오가도, 광고 노출과 전환을 잇기가 어려워졌어요.
대안으로 등장한 게 1st party 데이터를 중심으로 한 ID 그래프입니다. 자기 회사가 직접 가지고 있는 식별자(이메일, 로그인 ID, 멤버십 번호)를 축으로, 가능한 모든 보조 식별자를 연결해 한 사람의 모습을 복원하는 방식이에요.
2. ID 그래프란 무엇인가 — 한 사용자 = 노드, 식별자 = 엣지
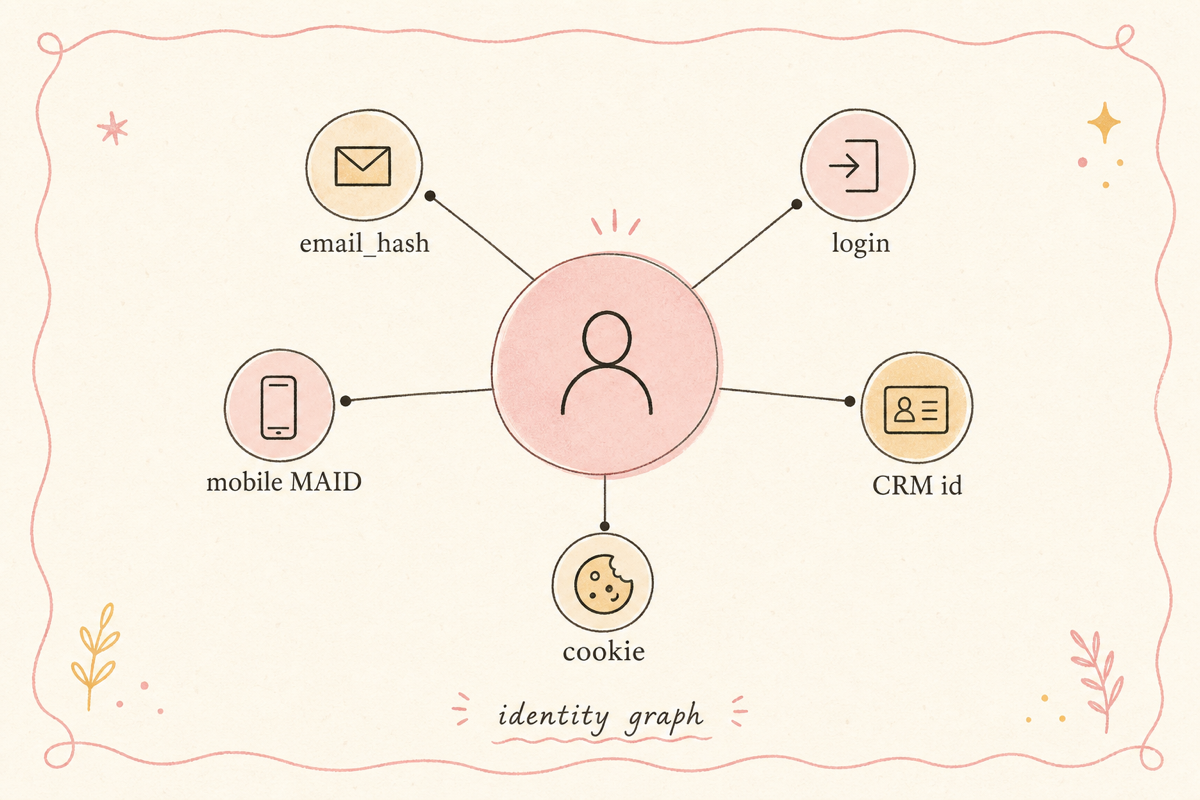
ID 그래프(Identity Graph)는 한 사용자를 가운데 두고, 그 사용자에게 연결된 모든 식별자를 노드로 잇는 자료구조입니다.
┌── email_hash: a1b2c3... │ ├── login_id: huny_42사용자 #18472 ──┤ ├── mobile_maid: ABC-123 │ ├── web_cookie: xyz-789 │ └── crm_member_id: M00018472각 식별자가 어떻게 같은 사용자라고 결론 내리는지가 매칭의 본질입니다. 두 가지 방식이 있어요.
2.1 Deterministic matching (확정 매칭)
같은 사용자가 명시적으로 사용한 식별자끼리 잇습니다. 예를 들어 한 사람이 모바일 앱과 웹사이트에서 같은 이메일로 로그인하면, 그 두 세션의 모든 신호는 같은 사용자에게 묶입니다.
- 이메일·전화번호·로그인 ID·CRM 회원번호처럼 사용자가 직접 입력한 식별자로 잇기
- 정확도 매우 높음(거의 100%)
- 단점: 로그인 안 한 사용자, 게스트 결제 사용자는 매칭 못 함
2.2 Probabilistic matching (확률적 매칭)
직접 잇는 정보가 없을 때 보조 신호로 추정합니다. 예를 들어 같은 IP, 같은 디바이스 fingerprint, 비슷한 시간대 활동 패턴이 보이면 같은 사용자일 확률이 높다고 판단해요.
- IP·user-agent·디바이스 fingerprint·세션 시간 패턴
- 정확도 60-80%(데이터 품질에 따라 큰 차이)
- 사용자 입력 없이도 매칭 가능, but 실수가 섞임
| 매칭 방식 | 입력 신호 | 정확도 | 커버리지 | 프라이버시 영향 |
|---|---|---|---|---|
| Deterministic | 이메일·로그인·CRM ID | 거의 100% | 로그인 사용자만 | 낮음(동의 기반) |
| Probabilistic | IP·디바이스·시간 패턴 | 60~80% | 거의 모든 사용자 | 높음(규제 영향 큼) |
| Hybrid | 둘 다 결합 | 90%+ | 두 영역 모두 | 중간 |
실무에선 deterministic을 축으로 두고, 못 잡힌 부분만 probabilistic으로 보완하는 hybrid가 표준입니다.
3. 식별자 종류별 가용성 — 무엇이 살아남았나
마케터가 다루는 주요 식별자별로 현재 가용성이 어떻게 되는지 표로 정리하면 다음과 같습니다.
| 식별자 | 종류 | 영역 | 현재 가용성 | 향후 |
|---|---|---|---|---|
| 이메일(해시) | deterministic | 1st/2nd/3rd party | 높음 | 안정 — 표준 매칭 키 |
| 전화번호(해시) | deterministic | 1st party | 한국 표준 | 안정 |
| 로그인 ID | deterministic | 1st party | 높음 | 안정 |
| CRM 멤버 ID | deterministic | 1st party | 높음 | 안정 |
| IDFA(iOS) | probabilistic-ish | 모바일 앱 | 30% 안팎(ATT 동의율) | 계속 낮음 |
| GAID(Android) | probabilistic-ish | 모바일 앱 | 60% 안팎 | 점진적 하락 |
| 1st party cookie | semi-deterministic | 자사 웹 | 높음 | 안정 |
| 3rd party cookie | probabilistic | 광고 트래킹 | 하락 중 | 단계적 폐기 |
| 디바이스 fingerprint | probabilistic | 웹·앱 | 중간 | 규제 압박 ↑ |
| IP 주소 | probabilistic | 웹·앱 | 중간 | 규제 압박 ↑ |
핵심 변화는 두 가지입니다.
- 모바일 앱 식별자(IDFA·GAID) 가용성이 떨어짐 → 앱 캠페인 측정 정확도 하락
- 3rd party cookie 단계적 폐기 → 광고 retargeting·conversion attribution 정확도 하락
대신 1st party 식별자(이메일·로그인·CRM)의 상대적 가치가 커졌어요. 자기 데이터를 갖고 있는 회사가 광고 효율에서 우위를 가집니다.
4. CDP가 ID 그래프를 만드는 절차 — 4단계
Customer Data Platform(CDP)이 실제로 ID 그래프를 만드는 과정은 보통 다음 4단계입니다.
Step 1 — Identity ingestion
여러 소스에서 식별자가 함께 들어오는 이벤트를 수집합니다.
- 웹사이트 —
cookie_id,login_email_hash - 모바일 앱 —
maid,login_id - CRM —
member_id,email,phone - 이메일 마케팅 —
email,email_send_id
Step 2 — Identity stitching (식별자 잇기)
같은 식별자가 함께 등장한 이벤트를 통해 식별자 쌍을 연결합니다. 한 이벤트에 cookie_id = X와 login_email = Y가 동시에 있으면, 둘은 같은 사용자라고 판단해 그래프에 엣지를 그어요.
이 과정을 모든 이벤트에 대해 반복하면 하나의 사용자가 여러 식별자로 둘러싸인 구조가 만들어집니다.
Step 3 — Resolution (사용자 ID 부여)
각 식별자 클러스터에 통합 사용자 ID를 부여합니다. 이걸 보통 persistent user ID 또는 profile ID라고 부르고, 그 후의 모든 분석은 이 ID를 키로 합니다.
Step 4 — Activation (광고 플랫폼으로 송출)
생성된 프로필 ID와 그에 연결된 식별자(이메일 해시 등)를 광고 플랫폼·이메일·푸시 채널로 내보냅니다. Meta Custom Audience, Google Customer Match, LinkedIn Matched Audience가 이 단계의 대표적 사용처예요.
전체 흐름은 다음 한 줄로 요약됩니다.
웹/앱/CRM 이벤트 → identity ingestion → identity stitching(식별자 잇기) → resolution(persistent user ID 부여) → activation(Meta CAPI · Google CM · 이메일 · 푸시)
5. 매칭률 — 마케터가 봐야 할 새 KPI
CDP 도입 후 가장 중요한 운영 KPI 중 하나가 매칭률(match rate)입니다. 우리 회사 1st party 데이터의 사용자를 광고 플랫폼이 얼마나 식별해주는가를 의미해요.
Meta Custom Audience 매칭률 예시
- 우리 회사 회원 100만 명의 이메일 해시를 Meta에 업로드
- Meta가 자기 사용자 중 같은 해시를 찾아 매칭
- 일반적으로 50~70% 매칭이면 좋은 편(이메일이 Meta 가입 이메일과 다른 경우 매칭 안 됨)
| 채널 | 표준 매칭률 | 권장 임계 |
|---|---|---|
| Meta(Facebook/Instagram) | 50~70% | 60% 미만이면 데이터 품질 점검 |
| Google Customer Match | 40~60% | 50% 미만이면 점검 |
| LinkedIn Matched Audience | 30~50% | 40% 미만이면 점검 |
| 이메일 마케팅 (자체) | 95~99% | 본인 시스템이라 거의 100% |
매칭률을 끌어올리는 운영 포인트는 다음과 같습니다.
- 사용자 가입 시 이메일·전화번호 정확도 검증(타이핑 오류 차단)
- 이메일 추가 외에 전화번호도 함께 보내서 매칭 신호 다중화
- 정기적으로 inactive 회원을 정제해 매칭에 노이즈가 안 가게 관리
6. Clean room — 매칭은 하되 데이터는 안 주는 시대
최근 등장한 키워드가 data clean room입니다. 광고주가 자기 데이터를 직접 광고 플랫폼에 주지 않고, 중립 환경에서 매칭만 한 결과를 받는 구조예요.
- Google Ads Data Hub
- Meta Advanced Analytics
- Amazon Marketing Cloud
- AWS Clean Rooms
마케터 입장에선 “데이터를 통째로 넘기지 않고도 측정·매칭·세그멘테이션이 가능하다”는 게 매력입니다. 다만 분석 환경에 제약이 많고, 결과를 export하기 어려운 경우가 많아요.
7. 마케터 체크리스트 — 1st party 데이터 주도 운영
ID 그래프 시대에 마케터가 챙겨야 할 운영 항목입니다.
| 영역 | 체크 항목 |
|---|---|
| 식별자 수집 | 회원가입 시 이메일·전화번호 모두 받고, 결제 시 게스트도 이메일 필수 |
| 데이터 품질 | 이메일 typo·중복 제거, 정기 cleanup, hard bounce 회원 분리 |
| 매칭률 모니터링 | Meta·Google·LinkedIn별 매칭률을 분기 KPI로 추적 |
| 동의 관리 | ATT·CMP 동의 상태별로 식별자 사용 정책 명확화 |
| Conversion API | Meta/Google CAPI로 서버사이드 전환 신호 송출 |
| Clean room | 내부 데이터 가져가지 못하는 경우 clean room으로 분석 |
| 모델링 | 매칭 안 된 사용자도 cohort로 모델링해 인사이트 보완 |
핵심은 “쿠키가 사라져도 우리 회사가 직접 가진 식별자가 우리의 자산”이라는 인식입니다. 회원가입·로그인·CRM이 마케팅의 인프라가 됐어요.
8. 마치며 — 한 장으로 요약
- 3rd party cookie 폐기 + iOS ATT로 식별 정확도가 급격히 떨어짐
- 대안은 1st party 데이터 중심의 ID 그래프
- ID 그래프 = 사용자 노드 + 식별자 엣지로 구성된 그래프
- 매칭은 deterministic(정확) + probabilistic(커버리지)의 hybrid가 표준
- 이메일 해시가 사실상 디지털 광고의 새 표준 매칭 키
- 매칭률(match rate)이 마케터의 새 KPI — Meta 60%, Google 50% 임계
- Clean room·composable CDP가 데이터 거버넌스의 새 표준 패턴
다음 글은 시리즈 마지막으로, LLM 에이전트로 마케팅 리포트를 자동화할 때의 실패 사례와 진짜 쓸만해진 지점을 정리하겠습니다.
참고
- Apple — App Tracking Transparency
- Google — Privacy Sandbox — 3rd party cookie 대안 표준
- Meta — Conversions API — 서버사이드 전환 신호
- LiveRamp — Identity Resolution Whitepaper — 산업 표준 ID 그래프 구조 설명
- Snowflake — Composable CDP architecture — 데이터 웨어하우스 기반 CDP 패턴
Analytics Ops (GA4·GTM) 카테고리의 다른 글
전체 보기 →-
2026·06·18
GA4 컨설팅 체크리스트 30 — 설치·권한·이벤트·전환·attribution을 한 번에 점검하기
새 GA4 계정을 넘겨받았거나 컨설팅을 시작할 때, 무엇부터 확인해야 하나. 설치 정합성부터 권한, 이벤트 택소노미, 전환, attribution 설정까지 30개 점검 항목을 영역별로 정리했습니다. 나가서 바로 쓰는 체크리스트.
-
2026·05·16
광고 SQL·BI 안티패턴 7가지 — ROAS 보고서를 거짓말로 만드는 SQL 함정
광고 데이터를 SQL로 집계할 때 반복적으로 깨지는 7가지 패턴 — 중복 조인·attribution window 누락·시간대 미스·conversion lag·환율·채널 매핑·dedup. 마케터·BI팀이 실무에서 만나는 함정을 실제 SQL 반례와 함께 정리합니다.
-
2026·05·09
Marketing analytics maturity model — last-click부터 triangulation까지 5단계
마케팅 측정의 성숙도는 5단계로 나뉩니다. last-click → multi-touch → MMM → lift study → triangulation. 우리 팀이 어디 있는지 진단하고 다음 단계 로드맵을 잡는 한 가지 모델.
-
2026·05·08
Server-side Tagging과 Conversion API — 1st-party 데이터를 직접 운영하는 법
브라우저에서 보내는 픽셀이 30~50% 차단되는 시대에, 서버에서 광고 플랫폼으로 직접 이벤트를 보내는 server-side tagging과 Meta CAPI·GA4 Measurement Protocol·TikTok Events API의 핵심을 마케터 시선에서 정리합니다.