데이터 클린룸 — Meta·Google과 안전하게 데이터 매칭하는 법
쿠키·IDFA가 끊긴 시대에 자사 1st-party 데이터와 광고 플랫폼 데이터를 매칭하는 표준 방식이 데이터 클린룸입니다. AWS Clean Rooms·Google Ads Data Hub·Meta Advanced Analytics의 차이와 마케터가 매칭으로 얻을 수 있는 정보를 정리합니다.
들어가며
쿠키·IDFA가 끊긴 시대에 자사 1st-party 고객 데이터와 광고 플랫폼의 노출·클릭 데이터를 안전하게 매칭하는 표준 방식이 데이터 클린룸입니다. 마케터가 자기 CRM의 고가치 고객 리스트를 광고 플랫폼에 그대로 업로드하지 않고도, 누가 어떤 광고를 봤는지·매칭률은 얼마인지·광고 노출이 LTV에 어떻게 영향을 줬는지를 분석할 수 있습니다. 이 글은 Google Ads Data Hub·AWS Clean Rooms·Meta Advanced Analytics의 차이와 클린룸이 가능하게 하는 분석 시나리오를 마케터 시선에서 정리합니다.
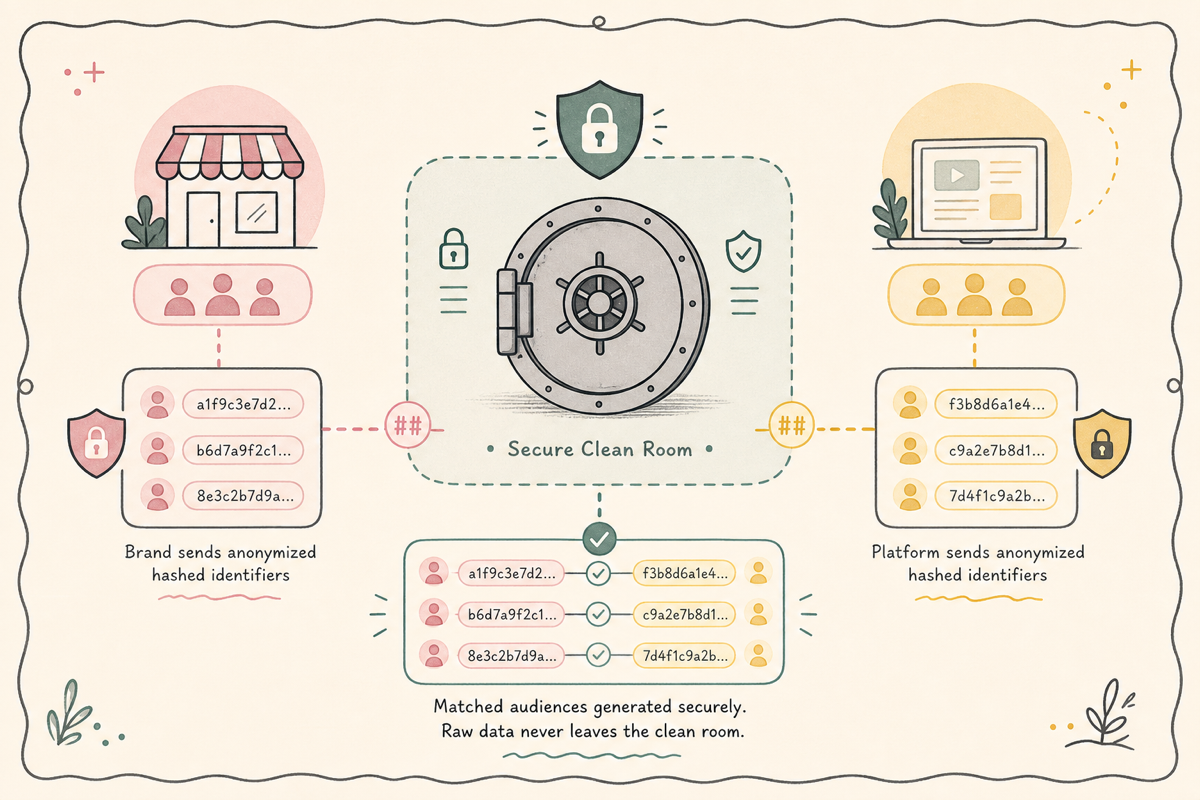
클린룸이 무엇을 가능하게 하나
표준 시나리오
마케터가 가지고 있는 데이터 — 1st-party 고객 리스트(이메일·전화·LTV·세그먼트). 광고 플랫폼이 가지고 있는 데이터 — 어떤 사용자가 어떤 광고를 봤고 클릭했는지. 두 데이터를 매칭하면 다음이 가능해집니다.
- 어느 캠페인이 우리 고가치 고객 세그먼트에 도달했나
- 광고 노출 후 LTV가 어떻게 바뀌었나
- 고가치 고객의 광고 노출 빈도·creative 분포
- 우리 비고객 풀에서 가장 우리 고객과 닮은 사람은 누구인가
클린룸이 막는 것
- 광고 플랫폼이 우리 고객 raw 리스트를 저장
- 우리 회사가 광고 플랫폼의 사용자 단위 데이터를 raw로 받음
- 둘 중 한쪽이 매칭된 사용자의 개인 식별 정보를 그대로 다운로드
- 작은 집계 그룹에서 개인 추론
이 보장이 있어야 GDPR·CCPA 같은 프라이버시 규제 안에서 운영 가능합니다.
작동 원리 — 격리된 환경에서의 join
표준 흐름
- 양측이 해싱된 매칭 키(이메일·전화)를 클린룸에 업로드
- 클린룸이 격리된 환경에서 매칭
- 분석 쿼리 실행 (집계 결과만 반환)
- 결과가 일정 임계값(보통 50명 이상) 이상의 그룹에 한해 노출
핵심 보장
- raw 데이터는 둘 다 못 봄
- 매칭된 데이터를 사용자 단위로 export 불가
- 작은 그룹 결과는 노이즈 추가 또는 차단
이 보장이 광고 플랫폼이 자체 데이터를 클린룸에 노출할 수 있는 이유입니다.
표준 클린룸 비교
Google Ads Data Hub (ADH)
- 강점: Google Ads·YouTube·DV360 데이터 풍부, BigQuery 통합
- 한계: Google 광고 플랫폼만, 학습 곡선 가파름
- 적합 회사: Google 광고 비중 큰 대형 광고주
Meta Advanced Analytics·Conversion Lift
- 강점: Meta 페이스북·인스타그램·WhatsApp 데이터, lift 실험 통합
- 한계: Meta 플랫폼만, 자유도 낮음
- 적합 회사: Meta 광고 비중 큰 회사
AWS Clean Rooms
- 강점: 멀티 광고 플랫폼·자체 파트너 데이터 매칭, AWS 인프라 통합
- 한계: 양측 모두 AWS 운영 필요, 광고 플랫폼 통합 별도 작업
- 적합 회사: 자체 데이터 인프라가 AWS인 회사
Snowflake·BigQuery 자체 데이터 공유
- 강점: 데이터 웨어하우스 그대로 사용
- 한계: 광고 플랫폼이 그쪽으로 데이터 보내야 함
- 적합 회사: 데이터 성숙도 높은 회사·파트너십 강한 광고 플랫폼
매칭률 — 클린룸 분석의 절반
매칭률을 결정하는 요소
같은 사용자의 데이터가 양측에 있어도 매칭 키 정규화가 안 되면 매칭이 안 됩니다.
- 이메일 → 소문자, 공백 제거 후 SHA-256
- 전화번호 → E.164 형식, 숫자만, 해싱
- 디바이스 ID → 그대로
매칭률 50% 이상이면 분석 가능, 70% 이상이면 안정적입니다.
매칭률 끌어올리기
- 매칭 키 여러 개 보내기 (이메일·전화·이름)
- 정규화 단계 자동화
- CRM 데이터의 결측치 줄이기
분석 시나리오 — 클린룸으로 무엇을 할 수 있나
시나리오 1 — 고가치 고객 도달 분석
SELECT campaign_id, COUNT(DISTINCT user_id) AS impressions, AVG(ltv) AS avg_ltv, COUNT(CASE WHEN ltv > 100000 THEN 1 END) AS high_valueFROM matched_dataGROUP BY campaign_idHAVING COUNT(DISTINCT user_id) > 50이 한 쿼리로 캠페인별 도달한 사용자 LTV 분포를 봅니다. 고가치 고객을 더 많이 잡은 캠페인을 분기 보고에 띄울 수 있습니다.
시나리오 2 — 광고 노출 후 LTV 변화
광고 노출 전후 30일 LTV를 비교해 노출이 가치 변화에 어떻게 기여했는지 봅니다. 단, 셀렉션 효과(원래 더 살 사람이 광고에 노출됨)를 반드시 통제해야 인과 추론으로 가까워집니다 — Lift 실험 디자인 필요.
시나리오 3 — Lookalike 시드 정교화
자사 LTV 상위 10% 고객의 클린룸 매칭 결과를 시드로 lookalike audience를 만듭니다. raw 시드 업로드보다 매칭률·시드 품질이 높아져 LAL 정확도가 올라갑니다.
시나리오 4 — 비고객 풀 분석
광고에 노출된 사람 중 우리 비고객 풀을 분석해 가장 잠재력 있는 세그먼트를 찾습니다. 신규 캠페인 타겟 디자인의 입력으로 사용.
운영 함정 — 시작하기 전에 알아둘 것
비용
클린룸은 자체 인프라(AWS·BigQuery)와 광고 플랫폼 라이선스 양쪽 비용이 듭니다. 작은 회사는 ROI가 안 나올 수 있습니다.
리소스
분석가가 SQL·BigQuery 또는 AWS 환경에 익숙해야 합니다. 학습 곡선이 가파르므로 데이터팀 1~2명의 시간이 분기당 며칠씩 들어갑니다.
결과 해석
매칭된 사용자가 전체 사용자의 일부분이라는 점을 잊으면 결과를 일반화하다 휘어집니다. 매칭률을 항상 슬라이드에 명시.
분기 KPI 후보
클린룸을 운영하기 시작했다면 분기 KPI에 다음을 넣을 만합니다.
- 매칭률 (전체·세그먼트별)
- 캠페인별 고가치 고객 도달 비율
- 광고 노출 후 LTV 변화 (인과 모델 필요)
- LAL 시드 품질 (정교화 전후 비교)
- 클린룸 분석 횟수와 분석 결과의 의사결정 활용도
함정 모음
- 매칭률 무시 — 30% 매칭에서 결과를 일반화
- raw export 시도 — 클린룸 정책 위반, 계정 정지 가능
- 인과 vs 상관 혼동 — 광고 노출 후 LTV 증가를 그대로 인과로 해석
- 비용 과소평가 — 인프라·인력 비용 분기당 적지 않음
- 광고 플랫폼별 상이성 — ADH·Meta·AWS 결과를 직접 합치기 어려움
마치며
데이터 클린룸은 쿠키·IDFA 시대 이후의 광고 측정·분석 표준 도구입니다. 자사 1st-party 데이터와 광고 플랫폼 데이터의 매칭으로 마케터가 IDFA 시절보다 더 깊은 분석으로 갈 수 있고, 동시에 GDPR·CCPA 같은 프라이버시 규제 안에서 안전하게 운영됩니다. 다만 인프라·인력 비용이 적지 않으므로 자사 데이터 성숙도와 분석 ROI를 함께 평가해 도입 결정을 합니다.
다음 분기에 한 번만 시도해 볼 만한 것은 가장 큰 광고 플랫폼 1개와 가장 큰 자사 KPI 1개로 한정한 작은 클린룸 PoC입니다. 매칭률·분석 ROI·인력 부담을 작은 스케일에서 검증한 뒤 본격 운영 결정.
참고
- Google, “Ads Data Hub”: https://developers.google.com/ads-data-hub
- AWS Clean Rooms: https://aws.amazon.com/clean-rooms/
- Meta, “Advanced Analytics·Conversion Lift”: https://www.facebook.com/business/help/1693381447650068
- Snowflake, “Data Clean Rooms”: https://www.snowflake.com/data-clean-rooms/
- IAB, “Data Clean Room Standards”: https://www.iab.com/insights/data-clean-rooms/
프라이버시·컴플라이언스 카테고리의 다른 글
전체 보기 →-
2026·06·05
Data Clean Room 입문 — Meta Advanced Analytics, Google ADH, AWS Clean Rooms 비교
쿠키 없는 시대의 attribution·오디언스 매칭 표준, Data Clean Room. privacy-preserving join의 본질부터 Meta Advanced Analytics·Google ADH·Amazon AMC·AWS Clean Rooms·Snowflake를 비교하고, k-익명성 제약과 실무 use case를 정리합니다.
-
2026·05·16
iOS ATT·GDPR·국내 PIPA — 마케터가 알아야 할 3대 프라이버시 규제
iOS App Tracking Transparency, EU GDPR, 한국 개인정보보호법(PIPA). 3가지 규제가 마케터의 measurement·targeting·동의 흐름에 미치는 영향을 한 글로 정리합니다.
-
2026·05·09
EU DMA가 walled garden을 어떻게 흔드나 — 마케터 영향 정리
EU의 Digital Markets Act(DMA)가 Meta·Google·Apple의 walled garden을 강제 개방시키고 있습니다. 광고주 데이터·측정·광고 제품 관점에서 마케터가 알아야 할 변화 정리.
-
2026·05·07
Privacy Sandbox — 쿠키 종료 이후 브라우저단 광고 타깃팅, 마케터가 알아야 할 5가지
서드파티 쿠키 종료 이후, 광고 타깃팅은 어디로 가나. Privacy Sandbox는 광고 식별을 광고주 서버에서 브라우저 안으로 옮기는 구글의 답입니다. Topics·Protected Audience·Attribution Reporting 3축이 무엇이고, 마케터가 캠페인·KPI를 어떻게 다시 설계해야 하는지.