퍼널 드롭오프를 베이지안으로 — "전환율 2.1%인데 진짜?"에 답하기
신규 캠페인 첫 주, 방문 1,200명 중 구매 25명. 전환율 2.08%라고 보고하면 다음 주에 다시 흔들립니다. Beta-Binomial로 신뢰구간을 함께 보고하는 베이지안 퍼널 분석.
“신규 광고 캠페인 첫 주 전환율 2.1%입니다.” — 회의에서 이런 한 줄을 자주 듣지만, 둘째 주에는 1.4%, 셋째 주에는 2.7%로 흔들리는 게 현실이에요. 작은 표본의 점추정은 거의 항상 거짓말을 합니다. 이 글은 베이지안의 가장 친숙한 입구인 Beta-Binomial 모델로 퍼널 전환율의 신뢰구간을 함께 보고하는 법을 다룹니다.
점추정 한 개의 거짓말
마케터·운영자 보고서에 가장 흔한 한 줄: “이번 주 전환율 2.1%입니다.”
이 한 줄에는 두 가지 정보가 빠져 있어요.
- 표본 크기: 25/1,200인지 2/95인지 250/12,000인지에 따라 의미가 천지차이
- 분산: “다음 주에도 비슷할까”의 답
같은 2.1%라도 표본이 적을수록 다음 주에는 1%로 떨어질 수도, 4%로 튈 수도 있어요. 점추정 한 개는 의사결정의 분산을 가립니다.
베이지안의 답은 단순합니다. 전환율을 숫자 1개가 아니라 분포로 본다. 표본이 적으면 분포가 넓고(불확실), 많으면 좁아집니다(확신). 이 분포를 보고서에 같이 가져가면 회의실에서 “2.1%인데 진짜?”라는 질문이 사라져요.
Beta-Binomial — 가장 쉬운 베이지안 모델
전환은 베르누이 시행입니다. 한 명이 사거나(1) 안 사거나(0). N명 중 k명이 샀을 때, “진짜 전환율 “의 분포를 베이지안으로 추정하는 표준 방법이 Beta-Binomial이에요.
사전 — Beta(1, 1) = 무지의 균등분포
전환율에 대해 아무것도 모르는 상태를 표현하려면 Beta(1, 1)로 시작합니다. 이건 0~1 사이의 균등분포예요.
직관: “전환율이 0.1%일 수도, 50%일 수도, 99%일 수도 있다고 일단 생각하자”
데이터 — N명 중 k명 전환
사후 — Beta는 켤레 사전이라 계산이 한 줄
Beta는 Binomial의 켤레 사전이라, 데이터를 보고 사후 분포가 그대로 또 Beta가 됩니다.
직관: “성공 카운터에 k를 더하고, 실패 카운터에 N-k를 더한다.” 끝.
신규 캠페인 첫 주에 1,200명이 방문해 25명이 구매했다면, 사후 분포는 . 이 분포의 통계량:
from scipy.stats import betapost = beta(26, 1176)post.mean() # 0.0216 → 평균 전환율 2.16%post.interval(0.95) # (0.0143, 0.0307) → 95% 신뢰구간마케터 보고서로 옮기면:
“신규 캠페인 첫 주 전환율 2.16% (95% CI: 1.4% - 3.1%)”
이 한 줄이 “2.1%입니다”보다 백 배 가치 있는 보고예요. 익원이 “다음 주는 어떻게 될 것 같아?”라고 물으면 “신뢰구간 안에서 움직일 가능성이 높습니다”라고 답할 수 있습니다.
표본이 적을수록 구간이 넓다
같은 “전환율 약 2%“라도 표본 크기에 따라 신뢰구간이 극적으로 다릅니다.
| 표본 N | 전환 k | 평균 추정 | 95% CI | 의미 |
|---|---|---|---|---|
| 50 | 1 | 3.8% | [0.5%, 11.9%] | 사실상 “모름” |
| 200 | 4 | 2.5% | [0.8%, 5.4%] | 폭이 평균 두 배 — 더 봐야 함 |
| 1,200 | 25 | 2.2% | [1.4%, 3.1%] | 의사결정 가능 |
| 12,000 | 250 | 2.1% | [1.8%, 2.3%] | 매우 신뢰 가능 |
CI 폭이 평균에 비해 얼마나 넓은지가 “이 숫자를 얼마나 믿을 수 있나”를 직접 알려줍니다.
약한 사전(weak informative prior) — 도메인 지식 살짝 끼얹기
Beta(1,1)은 “전혀 모름”이지만, 보통 마케터는 이 정도 캠페인은 전환율 1-3%일 거다 정도의 감은 있어요. 그 감을 사전에 반영하면 표본이 적을 때 추정이 훨씬 안정됩니다.
수학적으로는 사전의 를 “본 적 없는 가상 표본”처럼 생각하면 됩니다. Beta(2, 98)은 “평균 2%로 100명 정도 본 적 있다”는 약한 확신이고, Beta(50, 2450)은 “평균 2%로 2,500명 본 적 있다”는 강한 확신.
같은 데이터(N=50, k=1)에 사전을 바꿔 끼우면 결과가 달라집니다.
| 사전 | 사후 평균 | 사후 95% CI |
|---|---|---|
| 무지 Beta(1, 1) | 3.8% | [0.5%, 11.9%] |
| 약한 Beta(2, 98) | 2.0% | [0.4%, 4.9%] |
| 강한 Beta(50, 2450) | 2.0% | [1.5%, 2.6%] |
표본 50명, 전환 1명일 때 무지 사전은 “3.8% [0.5%, 11.9%]“라는 광기 어린 답을 주지만, 약한 사전은 “2.0% [0.4%, 4.9%]“로 차분해집니다. 도메인 지식을 사전으로 깐다 = 노이즈를 자연스럽게 흡수한다는 게 베이지안의 핵심.
두 광고 비교 — A가 진짜 B보다 나은가
A 광고와 B 광고를 똑같이 노출하고, 1주일 결과:
- A: 800 노출, 24 클릭 (CTR 3.0%)
- B: 850 노출, 22 클릭 (CTR 2.6%)
A가 더 좋아 보이지만, 분산을 모르고는 결정 못 합니다. 베이지안의 답은 사후 분포끼리 직접 비교.
A의 사후는 , B의 사후는 . 각각에서 샘플 5만 개씩 뽑아 비교하면(몬테카를로 시뮬레이션) 다음과 같은 답이 나옵니다.
| 지표 | 값 | 의미 |
|---|---|---|
| 68.3% | A가 더 좋을 확률 | |
| 평균 차이 | +0.44%p | 미미한 차이 |
| 차이 95% CI | [-1.24%p, +2.11%p] | 0을 가로지름 |
해석:
- A가 B보다 더 좋을 확률은 68.3% (절대 확신 아님)
- 차이의 95% 신뢰구간이 0을 가로지름 → 두 광고가 통계적으로 동일할 가능성 무시 못 함
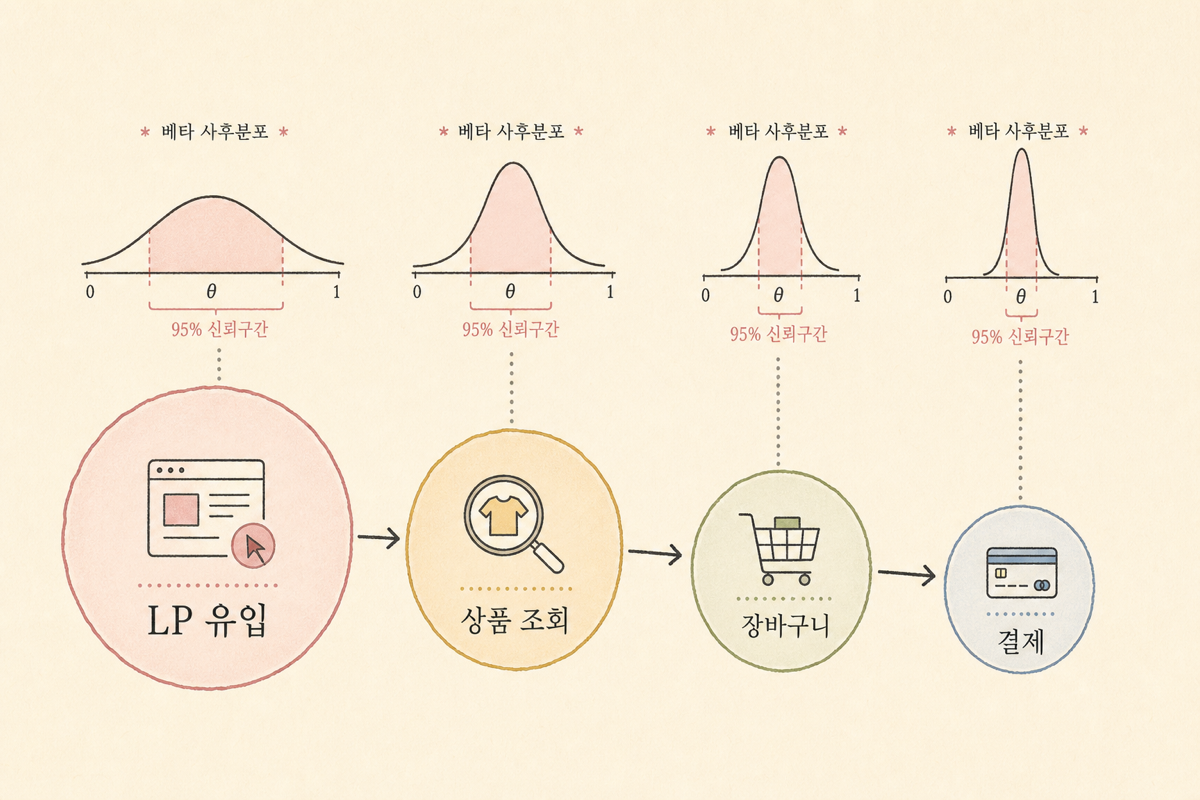
단계별 퍼널 — 어디서 가장 손실이 큰가
전환 퍼널: 광고 클릭 → 랜딩 페이지 → 상품 조회 → 장바구니 → 결제
각 단계의 통과율을 베이지안으로 보면, 표본 크기 차이까지 고려해서 “어디서 손실이 통계적으로 가장 크다”고 말할 수 있어요. 각 단계마다 Beta-Binomial을 따로 적용한 예시:
| 단계 | 진입 → 통과 | 통과율 (사후 평균) | 95% CI |
|---|---|---|---|
| LP 도달 | 10,000 → 5,800 | 58.0% | [57.0%, 59.0%] |
| 상품 조회 | 5,800 → 1,900 | 32.8% | [31.6%, 34.0%] |
| 장바구니 | 1,900 → 420 | 22.1% | [20.3%, 24.1%] |
| 결제 | 420 → 180 | 42.9% | [38.5%, 47.5%] |
해석:
- 가장 큰 손실은 상품 조회 → 장바구니 (78%가 빠짐, CI 폭 좁음 → 확신)
- 결제 단계 통과율은 평균 43%, CI 폭 [38%, 48%]가 다른 단계보다 넓음 → 표본 적어 더 봐야 함
마케터는 보통 “제일 빠지는 단계 1개 = 개선 우선순위 1순위”인데, 베이지안 신뢰구간을 같이 보면 “확신 가능한 손실 구간 vs 더 측정해야 할 구간”을 구분할 수 있어요.
운영 팁 — 마케터가 자주 묻는 것들
1) 매일 신뢰구간을 다시 그려도 되나?
네, 베이지안의 매력 중 하나입니다. A/B 테스트의 “peeking 함정”과 달리, 베이지안 사후 분포는 데이터가 들어올 때마다 자연스럽게 업데이트됩니다(P-value 같은 “정해진 검정 기간” 개념이 없음). 단, 의사결정 임계는 미리 정해두세요(“P(A > B) > 95% 도달 시 결정”).
2) 사전을 강하게 깔면 신규 캠페인 효과가 안 보일 텐데
맞아요. 그래서 신규 채널·신규 크리에이티브에는 약한 사전(Beta(2, 98) 정도)로 시작하고, 충분히 데이터가 쌓이면 사전 강도를 높이는 식으로 운영합니다. “새로 시작할 땐 의심을, 익숙해지면 확신을”
3) 클릭율, 전환율 외에도 이 방법이 통하나?
예/아니오로 떨어지는 모든 비율(이메일 오픈율, 회원가입율, 구독 유지율, 환불율)에 동일하게 적용 가능. 응답 변수가 비율이면 Beta-Binomial이 답.
4) PyMC로 더 복잡하게 할 수도 있나?
가능합니다. 캠페인별·세그먼트별 hierarchical 모델로 확장하면 “신규 채널 첫 주에 다른 채널 평균을 사전으로” 같은 더 강력한 보정을 자동화할 수 있어요. 다만 코드 복잡도가 올라가니, 첫 출발은 scipy.stats.beta로 충분.
자주 묻는 질문
Q1. Beta(1,1)이 정말 “전혀 모름”인가?
엄밀히는 균등분포(uniform)예요. 평균 0.5, 모든 전환율을 동등하게 가능하다고 봄. 마케팅 실무에서 평균 50% 전환율은 비현실적이니 “진짜 무지”보다는 “매우 약한 사전 + 균등” 정도. 데이터가 N=200 이상 모이면 사후 분포는 사전 영향이 거의 없어요.
Q2. P-value 검정과 비교해서 베이지안이 항상 좋나?
장단점이 있어요. 베이지안은 “매일 데이터 들어올 때마다 결정해도 됨”이 큰 장점(peeking 함정 없음). 다만 사전 선택에 책임이 따르고, 수학적으로 익숙하지 않은 팀에게 처음 도입하기 힘들 수 있어요. 빈도주의 + 미리 정한 검정 기간이 익숙하다면 그것도 충분히 합리적.
Q3. 신뢰구간 폭이 좁은데 결과가 직관과 다르면?
데이터를 의심하기 전에 “어떤 그룹/세그먼트가 섞여 있나”부터 점검하세요. Simpson’s Paradox(다음 글)가 그 답을 자주 줍니다. 전체 평균은 좁은 CI에 잘 잡히지만, 세그먼트별로 분리하면 정반대 결론이 나오는 케이스가 흔해요.
마치며
베이지안은 “고급 통계”가 아니에요. 점추정 한 개의 거짓말을 막는 가장 가벼운 도구입니다. Beta-Binomial 5줄 코드만 추가해도 다음 회의에서 “이 숫자 진짜?”라는 질문이 사라지고, 의사결정의 신뢰도가 한 단계 올라갑니다.
다음 글에서는 ROAS 보고서가 거짓말하는 이유 — incrementality test로 진짜 효과를 분리하는 법을 다뤄볼게요.
참고
- scipy.stats.beta 공식 문서 — 5줄짜리 베이지안의 출발점
- Bayesian Methods for Hackers — Cameron Davidson-Pilon — 무료 책, 1장이 정확히 이 주제
- Beta-Binomial Wikipedia — 수식 정리
- VWO Bayesian A/B Testing 백서 — 실무 비교
- Evan Miller — A/B Testing tools — 빈도주의 vs 베이지안 직접 계산기
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.