PyMC-Marketing으로 채널 기여도 직접 모델링 — Bayesian MMM 실전
MMM이 비싸고 느린 분석가용 도구라는 인식은 이제 옛말입니다. PyMC-Marketing으로 마케터가 직접 adstock·saturation·prior를 조정하며 채널 기여도를 추정합니다. 모델 fit·posterior 해석·예산 시나리오까지 한 번에 정리.
들어가며
“MMM은 외부 컨설팅에 6개월 맡겨야 나오는 결과”라는 인식이 한국 마케팅 조직에 여전히 깔려 있습니다. 하지만 PyMC-Marketing·Meridian·Robyn 같은 오픈소스가 자리를 잡으면서, 마케터가 분석가와 함께 분기 단위로 직접 돌리는 MMM이 현실적인 선택지가 됐습니다. 이 글은 PyMC-Marketing을 사용해 한국 광고 시장에서 자주 마주치는 채널 셋(Meta·Google·Naver)으로 Bayesian MMM을 굴리는 흐름을 마케터 시선으로 정리합니다. 이론은 직관 위주로, 의사결정 함의는 끝까지 끌고 갑니다.
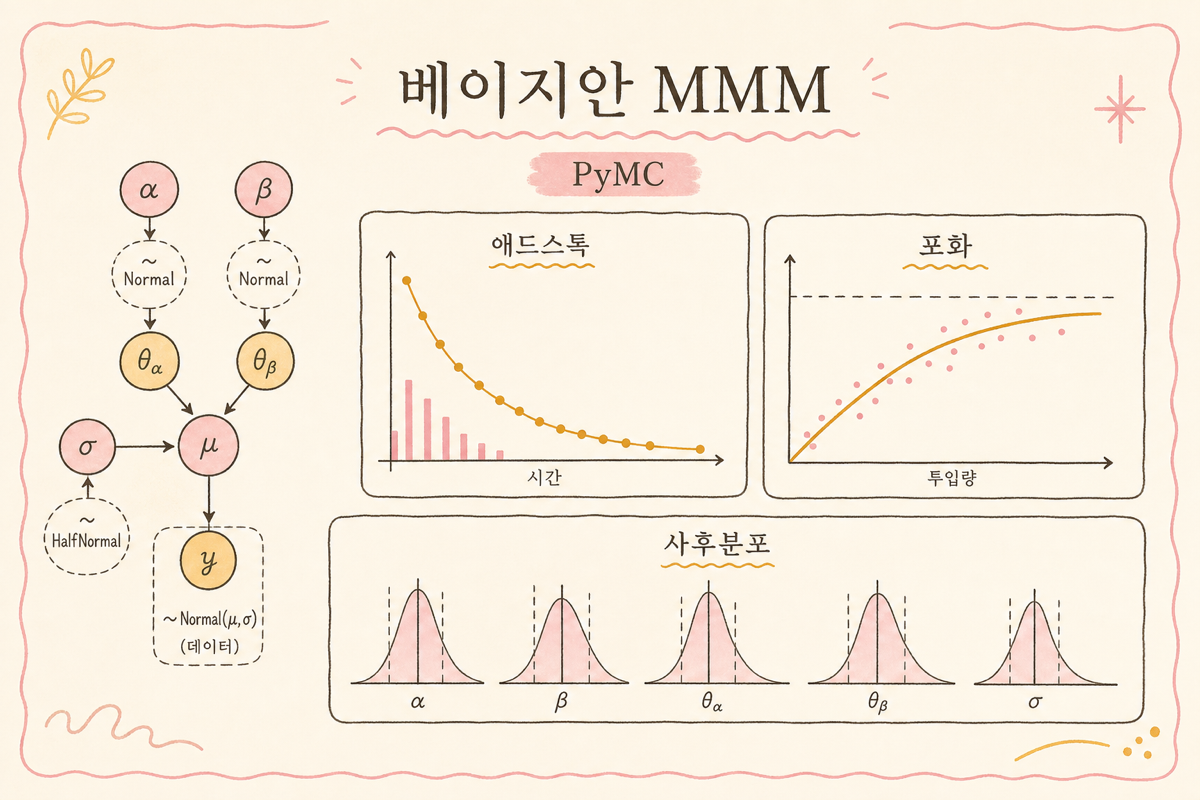
Bayesian MMM이란 무엇이 다른가
전통적인 MMM은 OLS(최소제곱) 회귀로 채널 계수를 점추정합니다. 채널 ROI가 1.4라면 그게 끝이고, 신뢰구간은 t-분포 가정에서 기계적으로 나옵니다. Bayesian MMM은 다른 그림입니다.
점추정 vs 사후분포
OLS는 “Meta ROI = 1.4”라고 답하고, Bayesian은 “Meta ROI는 평균 1.4, 90% 구간은 [0.9, 2.1]“이라고 답합니다. 후자가 의사결정에 훨씬 유용합니다.
좌변이 “데이터를 본 뒤의 ROI 분포”입니다. 우변은 “데이터 적합도”와 “사전 믿음”의 곱입니다. 데이터가 풍부하면 likelihood가 답을 압도하고, 데이터가 빈약하면 prior가 더 비중을 갖습니다 — 이 동적 균형이 작은 데이터셋(주간 데이터 2년 = 104주)에서 안정적인 답을 뽑는 비결입니다.
사전 지식을 어떻게 녹이는가
Lift 실험에서 “Meta incrementality 30%“라는 결과를 얻었다면, MMM의 Meta 채널 prior 평균을 거기에 맞춰 잡습니다. 데이터가 그 prior를 흔들면 posterior가 움직이고, 데이터가 약하면 prior 근처에 머뭅니다. 이게 lift와 MMM을 자연스럽게 연결하는 다리입니다.
Adstock — 광고 효과의 잔향
광고는 본 즉시 사라지는 게 아니라 며칠~몇 주에 걸쳐 영향을 남깁니다. 이걸 수식으로 표현하는 게 adstock입니다.
Geometric adstock — 가장 간단한 형태
는 t주 광고 지출, 는 잔향 비율(decay)입니다. 면 광고비 100을 쓰면 다음 주에도 50만큼 효과가 남고, 그 다음 주에 25, 12.5… 식으로 감쇠합니다.
마케터 직관으로 변환:
- TV·브랜드 광고 → 0.6~0.8 (오래 남음)
- 검색 광고 → 0.1~0.3 (즉시 효과)
- 디스플레이·소셜 → 0.3~0.5 (중간)
Delayed adstock — 효과가 늦게 도달
브랜드 캠페인은 본 즉시가 아니라 며칠 뒤에 검색·구매로 이어집니다. 이걸 표현하려면 peak가 0이 아닌 다른 시점에 오는 함수가 필요합니다.
는 효과의 peak 시점, 은 lag window 크기입니다. PyMC-Marketing의 WeibullAdstock·DelayedAdstock이 이런 형태를 지원합니다.
Saturation — 더 부어도 안 늘어나는 지점
같은 채널에 광고비를 두 배로 쓴다고 매출이 두 배 되지 않습니다. 일정 지점부터는 한계 ROI가 떨어지고, 결국 평평해집니다. 이걸 모델링하는 게 saturation 함수입니다.
Hill·Logistic 곡선
은 절반 포화 지점(half-saturation), 는 곡선의 가파름입니다. 일 때 , 일 때 입니다.
마케터에게 중요한 건 두 파라미터가 의사결정 단어로 번역된다는 점입니다.
| 파라미터 | 의미 | 의사결정 함의 |
|---|---|---|
| 절반 포화 지출 | 이 지출 이상부터 한계 ROI 감소 본격화 | |
| 곡선 기울기 | 클수록 임계 지점이 뚜렷, 작을수록 완만 |
근처에서 운영 중인 채널은 추가 지출이 효율적이고, 의 2~3배에 머무는 채널은 더 부어도 비효율입니다. 예산 재배분의 1번 후보입니다.
Prior 잡기 — 지식을 데이터에 어떻게 녹이나
PyMC-Marketing에서 prior는 평균과 분산(또는 stddev)으로 표현되는 분포입니다. 마케터가 prior를 잡을 때 자주 쓰는 룰:
- 과거 lift 실험 결과 → 채널 ROI prior 평균
- 매체 통념(TV adstock 0.7) → adstock decay prior 평균
- 모르는 영역 → 약한 prior(넓은 stddev)로 두고 데이터에 맡김
모델 fit·검증 — 한 페이지 체크리스트
PyMC-Marketing은 fit 후 다음을 자동으로 점검할 수 있게 해줍니다.
mmm.fit(X, y)mmm.plot_posterior_predictive() # 모델이 매출을 잘 따라가나mmm.plot_channel_contributions() # 채널별 기여도 시계열mmm.plot_direct_contribution_curves() # adstock·saturation 모양이 코드 블록 하나로 충분합니다. 마케터가 보는 건 다음 4가지:
- posterior predictive — 모델 추정선이 실제 매출선을 잘 따라가는지. 큰 캠페인·세일 시기를 놓치고 있다면 외생 변수가 빠진 신호입니다.
- 채널 기여도 시계열 — 각 주 매출에 채널들이 얼마씩 기여했는지의 stacked area. 평소 비중이 회사의 채널 운영 직관과 맞는지가 1차 검증.
- adstock·saturation 곡선 — 추정된 곡선 모양이 그 채널의 통념에 맞는지. TV가 즉시 효과 곡선으로 추정됐다면 모델 명세가 의심됩니다.
- R-hat·ESS — MCMC 수렴 진단. R-hat < 1.01, ESS > 400 정도면 일반적으로 OK.
Posterior로 의사결정 — 시나리오 비교
Bayesian MMM의 진짜 가치는 fit이 아니라 fit 이후 시나리오 비교에 나옵니다.
한계 ROAS 비교
각 채널의 saturation 곡선 위에서 현재 지출 위치의 미분(접선 기울기)이 한계 ROAS입니다. PyMC-Marketing은 이를 posterior 분포로 제공합니다.
분기 회의 슬라이드에는 채널별 mROAS의 평균과 90% 구간만 그리면 충분합니다. 어느 채널이 “더 부으면 효율이 떨어지는 영역”인지가 한 화면에 보입니다.
예산 재배분 시뮬레이션
총 예산 고정 상태에서 채널 비중을 옮기면서 기대 매출의 posterior 분포를 그립니다.
함정 모음
| 함정 | 증상 | 대응 |
|---|---|---|
| 다중공선성 | 채널들이 동시 진행돼 계수가 휘어짐 | prior 강화, 변동이 큰 시기 데이터 우선 |
| 외생 변수 누락 | posterior predictive에 큰 잔차 | 가격·재고·계절·경쟁사 캠페인 추가 |
| Adstock 명세 오류 | 채널 기여도가 통념과 어긋남 | geometric → delayed 전환 |
| Prior 과신 | posterior가 prior와 거의 동일 | prior stddev 확대 후 재학습 |
| 학습 구간 외삽 | 시뮬레이션이 비현실적 매출 예측 | 시뮬레이션 범위를 ±20% 내로 제한 |
마치며
Bayesian MMM은 더 이상 컨설팅 회사 전유물이 아닙니다. PyMC-Marketing은 마케터가 분석가와 함께 분기당 1회 정도 충분히 돌릴 수 있는 수준의 도구입니다. 핵심 가치는 단일 ROAS 숫자가 아니라 채널마다 적절한 prior를 잡고 posterior 분포를 의사결정에 직접 쓴다는 점입니다.
다음 분기에 추가해 볼 만한 것은 lift 실험 한 번을 prior에 직접 연결하는 흐름입니다 — Meta lift 30%를 prior로 넣고 fit한 MMM과 그렇지 않은 MMM의 채널 기여도 차이를 비교해보면, 두 측정의 결합이 의사결정을 어떻게 안정시키는지가 한 화면에 보입니다.
참고
- PyMC-Marketing 공식 문서: https://www.pymc-marketing.io/
- Google Meridian: https://developers.google.com/meridian
- Meta Robyn: https://github.com/facebookexperimental/Robyn
- Jin et al., “Bayesian Methods for Media Mix Modeling”: https://research.google/pubs/pub46001/
- “Carryover and Shape Effects in MMM” (Google): https://research.google/pubs/pub46001/
매체 데이터 알아보기 카테고리의 다른 글
전체 보기 →-
2026·06·18
Meta Marketing API 핸드북 — 인증부터 일자별 spend·전환·크리에이티브 추출까지
광고 매니저 화면에서 CSV를 매일 손으로 내려받고 있다면 이 글이 그 일을 끝내줍니다. Meta Marketing API로 토큰 발급, 일자별 spend·전환·크리에이티브를 안정적으로 뽑는 실전 핸드북. attribution window 함정과 async 리포트까지.
-
2026·05·16
MMP raw export 컬럼 사전 — Appsflyer, Adjust, Branch가 주는 진짜 데이터
Appsflyer·Adjust·Branch raw export에는 어떤 컬럼이 있고 각 컬럼이 진짜로 무엇을 뜻하는지. media_source·campaign·af_status·reattribution·SKAdNetwork postback 컬럼까지 마케터·데이터팀이 매일 만나는 raw export를 한 글로 정리합니다.
-
2026·05·16
Organic·Direct·Referral의 진실 — GA4, MMP, Amplitude가 organic을 부르는 4가지 방식
GA4의 organic search, MMP의 Organic, Amplitude의 Direct, GA4의 (direct)/(none). 같은 단어가 도구마다 다른 의미예요. 4가지 정의를 한 글로 정리하고 dark traffic·attribution 누락을 어떻게 분리하는지를 풉니다.
-
2026·05·16
매체 raw data 컬럼 가이드 — Meta, Google, TikTok, Naver의 진짜 컬럼들
Meta·Google·TikTok·Naver의 report field를 한 표로 매핑합니다. 비용·노출·클릭·전환과 함께 통화·시간대·attribution 설정을 보존하는 데이터 계약을 정리합니다.