Cold start 문제 — 신규 유저·신규 상품·신규 캠페인에 Thompson Sampling으로 답하는 법
신규 유저는 행동 이력이 없고, 신규 상품은 노출 이력이 없고, 신규 캠페인은 성과 이력이 없습니다. 정보 없이 추천·입찰·예산 분배를 어떻게 할까요. Thompson Sampling은 "탐색·활용 균형"의 베이지안 답을 가장 단순하게 줍니다. 마케팅 cold start 문제의 표준 도구.
“이 신규 유저에게 어떤 광고를 보여줘야 하나요?” 행동 이력이 없으면 추천 모델이 답을 못 줍니다. “이 신규 상품의 CTR을 어떻게 알죠?” 노출 이력이 없으면 입찰가 산정이 안 됩니다. “이 신규 캠페인에 예산을 얼마나?” 성과 이력이 없으면 ROAS 추정이 안 됩니다. 마케팅 운영의 cold start 문제는 매주 부딪히는 자리입니다. Thompson Sampling은 베이지안 사후 분포에서 한 번 샘플링하는 단순한 룰로 탐색·활용 균형을 잡습니다. 실무에서 가장 자주 쓰이는 cold start 도구를 정리합니다.
1. Cold start의 세 얼굴
마케팅 운영에서 cold start는 보통 다음 세 자리에 등장합니다.
- 유저 cold start — 신규 가입자. 행동·구매·노출 이력 없음. 어떤 추천·광고를 보여줄까
- 상품 cold start — 새로 들어온 SKU·소재. CTR·전환율 모름. 어디에 노출할까
- 캠페인 cold start — 새 광고 캠페인. 성과 이력 없음. 예산을 얼마나 할당할까
세 자리의 공통점은 정보 없이 의사결정해야 한다는 점입니다. 정확도가 0인 모델 출력에 의지할 수 없고, 그렇다고 방치할 수도 없습니다.
전통적 답은 두 극단입니다.
- 평균값 채우기 — 모든 신규를 평균 CTR·평균 LTV로 가정. 정보 부족 자체를 무시
- 무작위 노출 — 일부 트래픽을 무작위로 흩뿌려 데이터 모음. 비효율적
두 극단 사이에 베이지안 sequential 의사결정 도구가 있습니다. Thompson Sampling이 그 중 가장 단순하면서도 강력한 도구입니다.
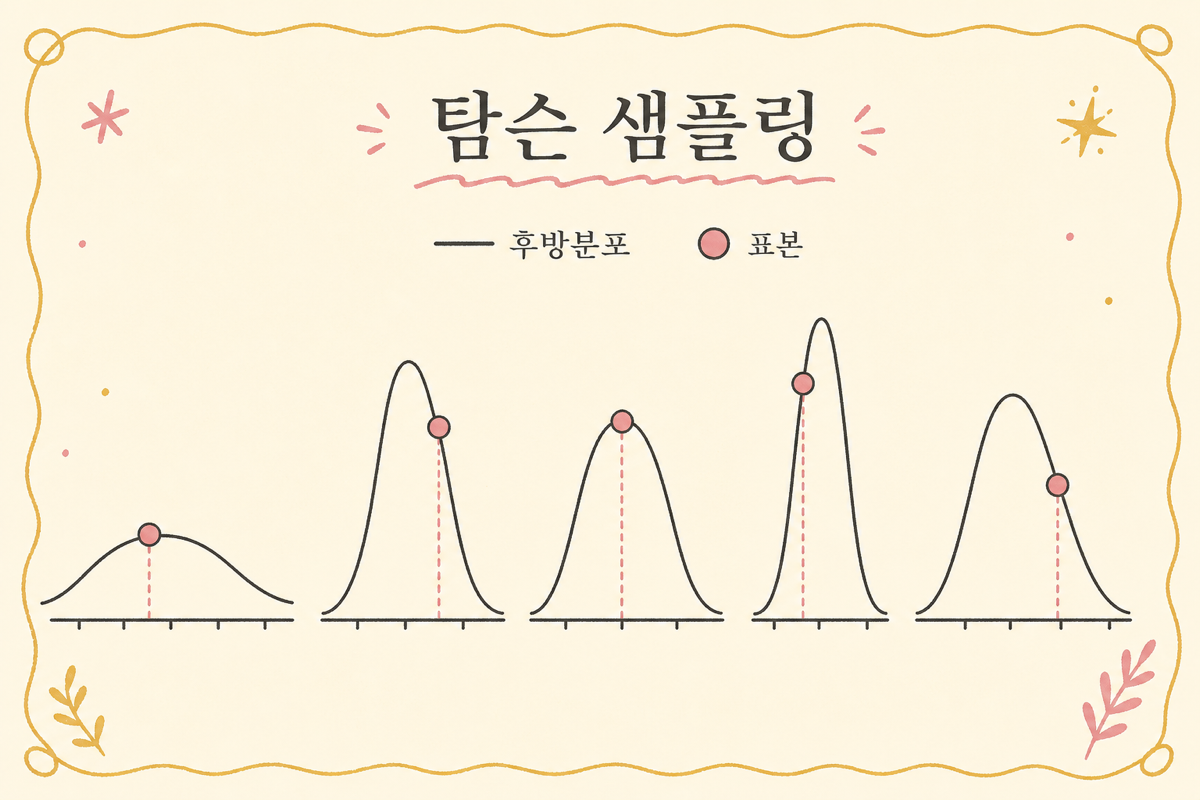
2. Thompson Sampling의 한 줄 룰
Thompson Sampling의 한 줄짜리 알고리즘은 다음입니다.
각 옵션의 사후 분포에서 한 번씩 샘플링해, 그중 가장 큰 값을 가진 옵션을 선택하라.
CTR 예측에서 옵션 의 진짜 CTR을 라고 합시다. 베이지안적으로는 위에 사전 분포를 깔고, 데이터가 들어올 때마다 사후 분포를 업데이트합니다. CTR 같은 베르누이 데이터에는 Beta 분포가 자연 사전입니다.
옵션 가 클릭 받은 횟수가 , 노출 횟수가 이면 사후는 .
매 임프레션마다 다음 절차로 옵션을 고릅니다.
- 각 옵션 에 대해 사후 분포에서 샘플 한 번씩 뽑기
- 옵션을 선택
- 결과 관측 후 그 옵션의 사후 업데이트
이 단순한 룰의 마법은 사후 분포의 폭이 자동으로 탐색을 유도한다는 점입니다.
- 데이터 적은 옵션 → 사후 폭 넓음 → 가끔 큰 값 샘플링 → 탐색
- 데이터 많은 옵션 → 사후 폭 좁음 → 점추정 근처에서 안정 → 활용
별도의 ε 같은 hyper-parameter 없이도 탐색·활용 균형이 자연스럽게 잡힙니다.
3. 코드 한 묶음 — 광고 소재 선택
광고 소재 5개 중 하나를 임프레션마다 선택하는 단순한 운영 코드.
import numpy as np
# alpha, beta — 각 소재의 Beta 사후 파라미터 (시작은 1, 1)alpha = np.ones(5); beta = np.ones(5)
def choose_creative(): samples = np.random.beta(alpha, beta) return int(np.argmax(samples))
def update(creative_id, click): alpha[creative_id] += click beta[creative_id] += 1 - click이게 본문의 유일한 코드입니다. 두 함수 — choose_creative()로 소재 선택, update()로 결과 반영. 임프레션마다 한 번씩 호출하면 cold start 환경에서 자동으로 탐색·활용을 잡습니다.
운영에서 챙길 한 가지 — 사전 분포의 선택입니다. 모든 옵션에 Beta(1,1) 균등 사전을 깔면 처음에는 옵션 모두에 균등하게 트래픽을 배분합니다. 도메인 지식이 있으면 더 정보적인 사전을 깔 수 있습니다.
- 운영 평균 CTR이 0.03이면 → Beta(3, 97) 같은 사전 (1단위 노출에 클릭 0.03)
- 신뢰도가 더 강한 사전 → Beta(30, 970) (10배 강한 사전)
4. ε-greedy·UCB와의 비교
탐색·활용 도구는 Thompson 외에 두 가지 표준이 더 있습니다.
- ε-greedy — 확률 ε로 무작위, 1-ε로 최선. 단순하지만 ε 튜닝 필요
- UCB(Upper Confidence Bound) — 점추정 + 불확실성 보너스. 결정적 룰, 분포 가정
세 도구의 비교:
| 항목 | ε-greedy | UCB | Thompson Sampling |
|---|---|---|---|
| 단순성 | 매우 단순 | 단순 | 단순 |
| 탐색 메커니즘 | 강제 무작위 | 결정적 보너스 | 사후 폭 |
| Hyper-parameter | ε | 신뢰 수준 | 사전 분포 |
| 성능 (regret) | 약함 | 우수 | 우수 |
| 운영 구현 | 매우 가벼움 | 가벼움 | 가벼움 |
산업 적용 결과는 Thompson과 UCB가 비슷한 성능, ε-greedy가 약간 뒤처지는 패턴입니다. Thompson을 많이 쓰는 이유는 hyper-parameter 튜닝 부담이 가장 작기 때문입니다.
5. Contextual Thompson — 유저 정보가 있을 때
위 단순 Thompson은 옵션별 한 사후 분포만 다룹니다. 유저별로 다른 옵션을 추천하려면 context(유저 변수)를 모델에 넣어야 합니다. 이게 contextual Thompson입니다.
가장 단순한 형태는 logistic regression Thompson — CTR을 유저 변수의 logistic 함수로 모델링하고, 회귀 계수의 사후에서 샘플링합니다.
매 임프레션마다 사후에서 샘플 뽑고, 모든 옵션의 예측 CTR을 그 샘플로 계산해 가장 큰 옵션 선택.
운영적으로 contextual Thompson이 빛나는 자리:
- 신규 유저에 채널·디바이스 정보로 cold start 보강
- 신규 상품에 카테고리·가격 정보로 시작점 추정
- 신규 캠페인에 과거 유사 캠페인의 메타 정보로 사전 강화
6. 마케팅 실무 케이스 3개
6-1. 광고 소재 자동 배분
광고 소재 5개를 한 캠페인에서 동시에 굴립니다. 처음에는 각 소재에 트래픽이 균등하게 가지만, 클릭이 모이면서 좋은 소재에 트래픽이 자동 집중됩니다. 운영자가 매일 보는 부담 없이 best 소재가 자동으로 부각되는 구조입니다.
6-2. 신규 상품 입찰가 산정
신규 SKU의 CTR은 모릅니다. Beta(3, 97) 같은 약한 사전을 깔고 임프레션마다 사후에서 샘플링한 CTR로 입찰가를 산정합니다. 첫 며칠은 다양한 슬롯에 노출되면서 데이터를 모으고, 곧 진짜 CTR로 수렴합니다.
6-3. 신규 캠페인 예산 분배
새 캠페인의 ROAS는 모릅니다. 베이지안 hierarchical 모델로 같은 채널의 과거 캠페인 평균을 사전 분포로 깔고, Thompson Sampling으로 일별 예산을 분배합니다. 첫 주는 탐색 비중이 크고, 둘째 주부터는 데이터에 따라 자동 조정됩니다.
7. Thompson이 깨질 때 — 흔한 함정 3가지
7-1. 사전 분포가 너무 강하다
Beta(300, 9700) 같은 강한 사전은 데이터가 와도 사후가 거의 안 움직입니다. 결과적으로 탐색이 죽고 새 옵션이 시도되지 않습니다. Beta(3, 97) 정도의 약한 사전이 운영 표준입니다.
7-2. Reward의 분포가 비정상
Thompson은 reward(클릭·전환)가 안정된 분포라고 가정합니다. 시즌·매크로 환경 변화로 진짜 CTR이 시간에 따라 변하면 사후가 옛 데이터에 매여 탐색이 망가집니다. 이런 자리는 sliding window Thompson이나 discount factor를 적용해야 합니다.
7-3. 옵션 간 dependency
광고 소재 A와 B가 같은 매체 슬롯을 두고 경쟁하면, A에 트래픽 몰아주는 결정이 B의 reward에도 영향을 줍니다. SUTVA 위반입니다. 이런 자리는 Switchback experiment 같은 다른 설계로 풀거나, 옵션을 슬롯 단위로 묶어 contextual Thompson을 적용해야 합니다.
8. 마치며 — 마케터의 의사결정 도구상자에 들어가는 또 한 도구
cold start 문제는 마케팅 운영의 영원한 자리입니다. 신규 유저·신규 상품·신규 캠페인은 매주 들어오고, 그 자리마다 정보 없이 의사결정해야 합니다.
Thompson Sampling이 주는 답은 단순합니다.
사후 분포에서 한 번 샘플링하고, 가장 큰 값을 가진 옵션을 골라라.
알고리즘 두 줄. Hyper-parameter 거의 없음. 광고 소재 자동 배분·신규 상품 입찰·캠페인 예산 분배에 그대로 적용 가능. 마케터의 의사결정 도구상자의 마지막 한 칸에 들어갈 만합니다.
다음 글에서는 또 다른 자리, 부분 준수(non-compliance) 환경의 인과추론을 다룹니다. “쿠폰 받았지만 안 쓴 사람”이 섞인 실험에서 진짜 효과를 어떻게 분리하느냐의 문제입니다.
참고
- Thompson (1933), On the likelihood that one unknown probability exceeds another in view of the evidence of two samples, Biometrika — Thompson 원전
- Chapelle & Li (2011), An Empirical Evaluation of Thompson Sampling, NeurIPS — 산업 적용 표준 평가
- Russo, Van Roy, Kazerouni, Osband, Wen (2018), A Tutorial on Thompson Sampling, FnT in ML — 종합 튜토리얼
- Agrawal & Goyal (2012), Analysis of Thompson Sampling for the Multi-armed Bandit Problem — regret 분석
- Vowpal Wabbit — contextual bandit — Thompson·UCB의 산업 표준 구현
- huny.log 내부 글: MAB vs A/B, Conformal Prediction, BG/NBD LTV
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.