MMM 결과로 예산 재배분 — 파레토 프론티어와 한계 ROAS
MMM이 끝났다고 일이 끝나지 않습니다. 채널별 한계 ROAS를 균등하게 만드는 재배분 알고리즘, 시뮬레이션 범위 제약, 회의에서 의사결정으로 끌고 가는 슬라이드 디자인까지 정리합니다.
들어가며 — 마케터가 이 글을 읽어야 하는 이유
MMM 모델이 fit되어 채널별 saturation 곡선과 한계 ROAS posterior를 얻었다면, 절반 작업이 끝난 것입니다. 나머지 절반은 그 결과를 다음 분기 예산 시트에 어떻게 옮기느냐입니다.
“어느 채널에 얼마를 써야 하나”라는 질문은 표면상 단순하지만, 답에 도달하려면 세 가지를 동시에 다뤄야 합니다. 첫째, 총 예산이 고정일 때 매출을 최대화하는 수학적 최적점 찾기. 둘째, 그 최적점의 불확실성을 posterior 분포로 표현하기. 셋째, 계약·인력·크리에이티브 등 운영 제약 안에서 현실적으로 옮기기. 이 세 가지를 묶는 것이 예산 재배분 사이클입니다.
이 글은 한계 ROAS 균등화 룰, scipy로 짜는 최적화 코드, 파레토 프론티어 시각화, PyMC posterior에서 추천 배분 샘플링까지 마케터 시선에서 정리합니다. mmm-saturation-curves에서 saturation 곡선과 한계 ROAS를 이해했다면 이 글이 그 다음 단계입니다.
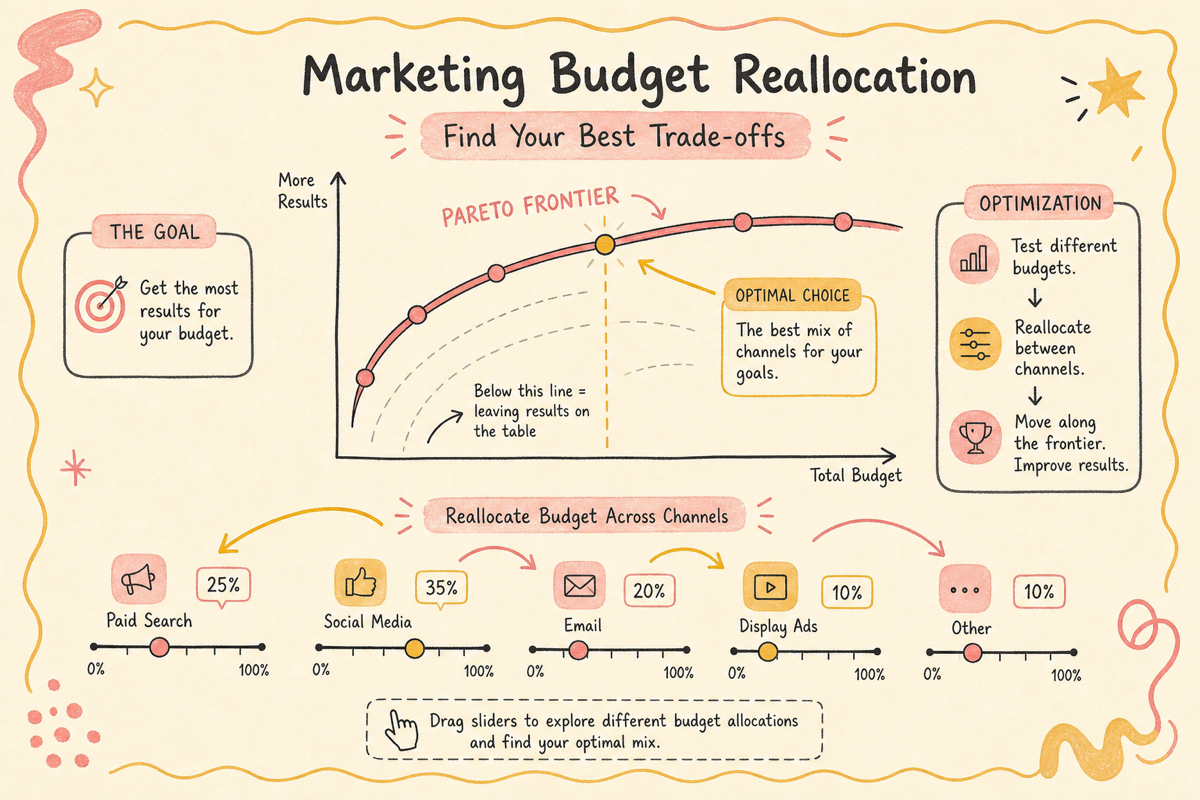
최적 배분의 경제학 — 한계 ROAS 균등화
총 예산이 고정되어 있을 때 매출을 최대화하는 배분은 모든 채널의 한계 ROAS가 같은 지점입니다. 이건 라그랑주 승수법(제약 최적화)의 결과이고, 마케팅에서는 “채널 간 1원의 한계 가치가 같아야 더 옮길 이유가 없다”는 직관으로 받아들이면 됩니다.
이 한 줄이 예산 재배분의 골격입니다. saturation 곡선 위에서 모든 채널의 접선 기울기를 같게 만드는 작업과 동일합니다.
평균 ROAS가 가장 높은 채널에 다 부으면 그 채널은 바로 saturation 영역으로 들어가 한계 ROAS가 떨어집니다. 예를 들어 Meta의 평균 ROAS가 4x이고 Naver의 평균 ROAS가 2x라 해도, Meta가 이미 saturation 영역 깊이 들어가 있고 한계 ROAS가 1.2x라면 Naver 한계 ROAS 3x인 쪽으로 예산을 옮기는 게 맞습니다. 채널 간 평균 ROAS 비교는 의사결정에 거의 쓰이지 않고, 한계 ROAS 비교가 정답에 가깝습니다.
세 가지 최적화 도구 — scipy·파레토·PyMC
scipy로 짜는 예산 최적화
import numpy as npfrom scipy.optimize import minimize
# Hill saturation 함수def hill(x, L, k): return x**k / (x**k + L**k)
# Hill 함수 미분 = 한계 ROAS의 saturation 부분def hill_deriv(x, L, k): return k * L**k * x**(k - 1) / (x**k + L**k)**2
# 채널별 파라미터 (posterior 평균값 사용)# 순서: Meta, Naver, TVbeta = np.array([2.5, 1.8, 3.2]) # 회귀 계수L_val = np.array([80e6, 40e6, 150e6]) # 절반 포화 지출 (원)k_val = np.array([1.5, 1.2, 2.0]) # 곡선 가파름
def neg_total_revenue(budget_vec): """총 매출 음수 반환 (minimize는 최소화를 하므로)""" return -np.sum(beta * hill(budget_vec, L_val, k_val))
total_budget = 200e6 # 2억 원 총 예산n = len(beta)x0 = np.full(n, total_budget / n) # 균등 분배로 시작
constraints = {'type': 'eq', 'fun': lambda x: np.sum(x) - total_budget}bounds = [(5e6, 120e6)] * n # 채널별 최소·최대 예산 제약
result = minimize( neg_total_revenue, x0, method='SLSQP', bounds=bounds, constraints=constraints, options={'ftol': 1e-9, 'maxiter': 1000})
optimal = result.xmroas_optimal = beta * hill_deriv(optimal, L_val, k_val)
print("최적 배분 (억 원):", np.round(optimal / 1e8, 3))print("채널별 한계 ROAS:", np.round(mroas_optimal, 3))# → 최적점에서 모든 채널의 한계 ROAS가 같아짐 (균등화 확인)출력 결과 해석: mroas_optimal의 세 값이 거의 같아야 합니다. 차이가 5% 이내면 균등화 성공입니다. 만약 어느 채널 한계 ROAS가 혼자 높으면 bounds 제약 때문에 그쪽으로 더 못 옮기는 것이고, 이게 바로 운영 제약이 수학적 최적을 가로막는 지점입니다.
파레토 프론티어 시각화 — 매출 vs 위험
한 점 추정 vs 분포
MMM 결과는 점추정이 아니라 posterior 분포입니다. 각 배분 시나리오에 대해 기대 매출의 분포가 나옵니다. 평균과 변동성이 함께 움직입니다.
| 시나리오 | 기대 매출(평균) | 변동성(stddev) |
|---|---|---|
| 현재 배분 | 100 | 10 |
| MMM 최적 (한계 균등) | 108 | 12 |
| 50:50 (단순 균등) | 95 | 14 |
| 한 채널 집중 | 105 | 25 |
평균만 보면 MMM 최적이 정답이지만, 변동성을 함께 보면 위험 선호도에 따라 다른 답이 나옵니다.
파레토 프론티어 시뮬레이션 코드
import matplotlib.pyplot as plt
# 1,000개 랜덤 배분 시나리오 시뮬레이션np.random.seed(42)n_sim = 1000results = []
for _ in range(n_sim): # 디리클레 분포로 랜덤 비중 생성 weights = np.random.dirichlet(np.ones(n)) budget_vec = weights * total_budget # bounds 적용 budget_vec = np.clip(budget_vec, 5e6, 120e6) budget_vec = budget_vec / budget_vec.sum() * total_budget
rev_mean = np.sum(beta * hill(budget_vec, L_val, k_val)) # posterior 불확실성 추가 (stddev = 회귀 잔차 기준) rev_std = rev_mean * 0.12 results.append((rev_std, rev_mean))
stds, means = zip(*results)
plt.figure(figsize=(8, 5))plt.scatter(stds, means, alpha=0.3, s=10, color='steelblue')plt.axvline(np.std([r[1] for r in results[:1]]), color='red', ls='--', label='현재 배분')plt.xlabel('변동성 (stddev)'); plt.ylabel('기대 매출')plt.title('파레토 프론티어 — 매출 vs 위험')plt.legend(); plt.tight_layout(); plt.show()# → 좌상단에 몰린 점들이 효율적 프론티어x축에 변동성, y축에 기대 매출을 두면 파레토 프론티어가 그려집니다. 같은 위험 수준에서 가장 높은 매출을 주는 배분이 효율적 배분이고, 회사의 위험 선호에 따라 이 곡선 위 한 점을 선택합니다.
PyMC posterior에서 추천 배분 샘플링
불확실성을 배분에 반영하기
점추정 최적화는 posterior 평균 파라미터 한 세트로 최적화합니다. 더 정직한 방법은 posterior 샘플 각각에 대해 최적화를 돌려 추천 배분의 분포를 얻는 것입니다.
import pymc as pmimport arviz as az
# idata: PyMC-Marketing fit 결과 (InferenceData)# idata.posterior['beta_channel'] shape: (chains, draws, n_channels)# idata.posterior['L_channel'] shape: 동일# idata.posterior['k_channel'] shape: 동일
posterior = idata.posteriorn_samples = 200 # posterior 샘플 수optimal_allocations = []
for i in range(n_samples): # 랜덤 체인·draw 선택 chain_idx = np.random.randint(posterior.dims['chain']) draw_idx = np.random.randint(posterior.dims['draw'])
b = posterior['beta_channel'].values[chain_idx, draw_idx] L = posterior['L_channel'].values[chain_idx, draw_idx] k = posterior['k_channel'].values[chain_idx, draw_idx]
def neg_rev(x): return -np.sum(b * hill(x, L, k))
res = minimize(neg_rev, x0, method='SLSQP', bounds=bounds, constraints=constraints) if res.success: optimal_allocations.append(res.x)
alloc_arr = np.array(optimal_allocations) # (n_samples, n_channels)print("추천 배분 중앙값 (억 원):", np.median(alloc_arr, axis=0) / 1e8)print("90% 신뢰구간:")for i, ch in enumerate(['Meta', 'Naver', 'TV']): lo, hi = np.percentile(alloc_arr[:, i], [5, 95]) / 1e8 print(f" {ch}: {lo:.2f}억 ~ {hi:.2f}억")# → "Meta +15%~+25%" 형태로 보고할 수 있음이 출력이 회의 슬라이드에 들어가야 하는 숫자입니다. “Meta +20%로 이동”이 아니라 “Meta +15~+25% 사이가 90% 신뢰구간” 형태로 제시하면 의사결정이 훨씬 정직해집니다.
의사결정으로 옮기기 — 슬라이드·범위·단계
분기 예산 회의 슬라이드 핵심 5개 요소
- 현재 배분 vs 추천 배분 — 채널별 비중 비교 막대그래프 (중앙값 + 90% CI)
- 채널별 한계 ROAS — posterior 평균과 90% 구간
- 기대 매출 변화 — 추천 배분 적용 시 예상 매출과 변동성
- 파레토 곡선 위 위치 — 위험 vs 매출 산점도
- 운영 제약 메모 — 추천대로 못 옮기는 채널과 이유
이 다섯 요소가 한 슬라이드에 들어가면 회의 의사결정의 80%가 그 한 장에서 정리됩니다. 특히 “왜 수학적 최적으로 못 옮기는가”를 운영 제약 메모로 명시해야 다음 분기까지 추적이 가능합니다.
시뮬레이션 범위 제한 — 외삽의 함정
학습 구간 밖 위험
MMM 모델은 학습 데이터로 본 광고비 범위 안에서만 신뢰할 수 있습니다. 어느 채널을 평소의 5배로 부으면 모델은 외삽을 하고, 그 외삽이 현실과 어긋날 가능성이 큽니다.
운영 제약 반영수학적 최적이 운영적으로 불가능한 경우가 흔합니다.
- 매체 계약 — 작년에 계약한 미디어 비용은 분기 안에 줄일 수 없음
- 인적 리소스 — Naver 운영 인력이 정해져 있어 갑자기 두 배 못 함
- 크리에이티브 풀 — TV CF 한 편 만들어 놨는데 안 쓸 순 없음
- 학습 단계 채널 — 신규 채널은 데이터 만들기 위해 일정 예산 유지 필요
이 제약을 scipy bounds와 constraints에 직접 반영해 “현실적으로 가능한 배분 안에서 최적”을 찾습니다.
단계적 재배분과 검증 루프
위험 분산 룰수학적 최적 배분으로 한 번에 옮기는 것보다, 분기마다 1/3~1/2씩 단계적으로 옮기는 게 안전합니다.
- 모델이 틀렸을 가능성에 대한 안전 마진
- 채널의 saturation 곡선이 시간에 따라 변할 수 있음
- 운영팀이 새 비중에 적응할 시간 필요
- 다음 분기 데이터로 모델을 재검증할 기회
| 분기 | 현재 → 목표 | 이동량 | 비고 |
|---|---|---|---|
| Q2 | 30% → 35% | +5% | 절반만 이동 |
| Q3 | 35% → 40% | +5% | 모델 재검증 후 추가 이동 |
| Q4 | 40% 유지 | 0 | lift 실험으로 효과 측정 |
이 흐름이 깔리면 매 분기 결정이 작은 step으로 쌓이고, 나중에 결과 회수가 깔끔해집니다. 재배분 전 모델 검증은 mmm-validation-holdout에 정리한 5단계 절차를 따르고, 결과를 mta-mmm-lift-comparison에서 다루는 triangulation으로 교차 검증합니다.
함정 모음
- 점추정 의존 — posterior 분포 대신 평균만 보면 위험을 무시합니다. scipy 코드를 posterior 평균으로 한 번만 돌리고 끝내면 이 함정에 빠집니다.
- 외삽 — 학습 구간 밖 시뮬레이션 결과를 액면 그대로 받으면 안 됩니다.
- 운영 제약 무시 — 수학적 최적을 운영팀에 그대로 던지면 거부됩니다. bounds로 제약을 미리 반영해야 합니다.
- 한 번에 점프 — 큰 이동을 한 분기에 하면 모델 검증 기회 상실.
- 학습 예산 부족 — 신규 채널을 단기 ROAS로 평가해 조기에 죽이면 saturation 곡선을 영원히 모릅니다.
마치며
MMM의 가장 큰 가치는 fit이 아니라 그 결과로 만든 예산 재배분 슬라이드입니다. 한계 ROAS 균등화를 경제학 직관으로 이해하고, scipy로 수치 최적화하고, PyMC posterior 샘플링으로 불확실성을 분포로 표현하면 회의실 슬라이드가 훨씬 정직해집니다.
다음 분기에 한 번만 시도해 볼 것은 추천 배분과 실제 적용 배분의 차이를 분기말에 회수하는 슬라이드입니다. 모델이 추천한 대로 못 갔다면 그 이유(운영 제약·위험 회피)를 정리해 다음 분기 시뮬레이션에 반영합니다.
다음에 읽을 글- MMM saturation 곡선 — 한계 ROAS의 원천
- MMM 모델 검증과 holdout — 예산 재배분 전에 반드시
- MTA·MMM·Lift 비교 — 한계 ROAS를 triangulation으로 교차 검증
참고
- Jin et al., “Bayesian Methods for Media Mix Modeling”: https://research.google/pubs/pub46001/
- Robyn, “Budget allocator”: https://facebookexperimental.github.io/Robyn/docs/allocator/
- PyMC-Marketing, “Budget optimization”: https://www.pymc-marketing.io/
- Recast, “How to use MMM for budget allocation”: https://getrecast.com/budget-allocation/
- “Marketing Mix Optimization” (Tellis 2006): https://www.tellis.usc.edu/research
퍼포먼스 마케팅 카테고리의 다른 글
전체 보기 →-
2026·06·05
ROAS 보고서가 늘 거짓말하는 이유 — incrementality 3대장
Meta 대시보드 ROAS 5가 실제로는 1.x인 이유. last-click·view-through·incremental 세 가지 ROAS의 차이와, holdout·geo-lift·ghost ads·conversion lift로 진짜 증분을 측정하는 법을 마케터 시선으로 정리합니다.
-
2026·05·16
DSP·SSP·DMP 인프라 해부 — 매체 영업 미팅에서 듣는 약자들의 정체
매체 영업 미팅에서 DSP, SSP, DMP, CDP, ad exchange, 헤더비딩 같은 약자들이 쏟아집니다. 각각이 어느 회사이고, 광고비가 어디로 흘러가며, 마케터가 의사결정할 때 어떤 의미를 갖는지 한 글에 정리합니다.
-
2026·05·16
Lookback window가 ROAS를 바꾸는 법 — click 7d, view 1d, 28d, 90d의 차이
같은 캠페인도 attribution lookback window를 click 7d, view 1d, 28d, 90d 중 어느 기준으로 보느냐에 따라 ROAS가 달라집니다. 최신 공식 설정과 비교 원칙을 정리합니다.
-
2026·05·09
Brand lift study 설계 — 광고가 인지·호감도를 끌어올렸나
브랜드 광고는 ROAS로 잡히지 않고 인지·호감도·구매의향으로만 측정됩니다. 노출 그룹과 비노출 그룹을 비교하는 brand lift study의 설계, 표본 계산, 실무 함정을 마케터 시선에서 정리.