입찰가를 머신러닝으로 — bid = f(predicted value)의 모든 것
pCTR·pCVR·pLTV 예측 모델이 광고 입찰가를 어떻게 결정하는지, value-based bidding과 bid shading·pacing이 어떻게 한 파이프라인에 묶이는지를 마케터가 이해할 수 있게 정리합니다.
들어가며
Meta·Google에서 “자동 입찰”을 켜고 ROAS 목표를 입력하면, 그 뒤에서는 사람이 정한 단가가 아니라 매 광고 노출마다 다시 계산되는 입찰가가 움직입니다. 이 입찰가는 “이 광고를 이 사람에게 보여주면 얼마짜리 가치를 만들 수 있을까”라는 예측에서 나오고, 그 예측은 머신러닝 모델 여러 개를 합친 결과입니다. 이 글은 입찰 자동화를 켜고 끄는 마케터가 그 안쪽 파이프라인을 이해할 수 있도록, 한 줄을 6~7개 H2로 풀어 정리합니다.
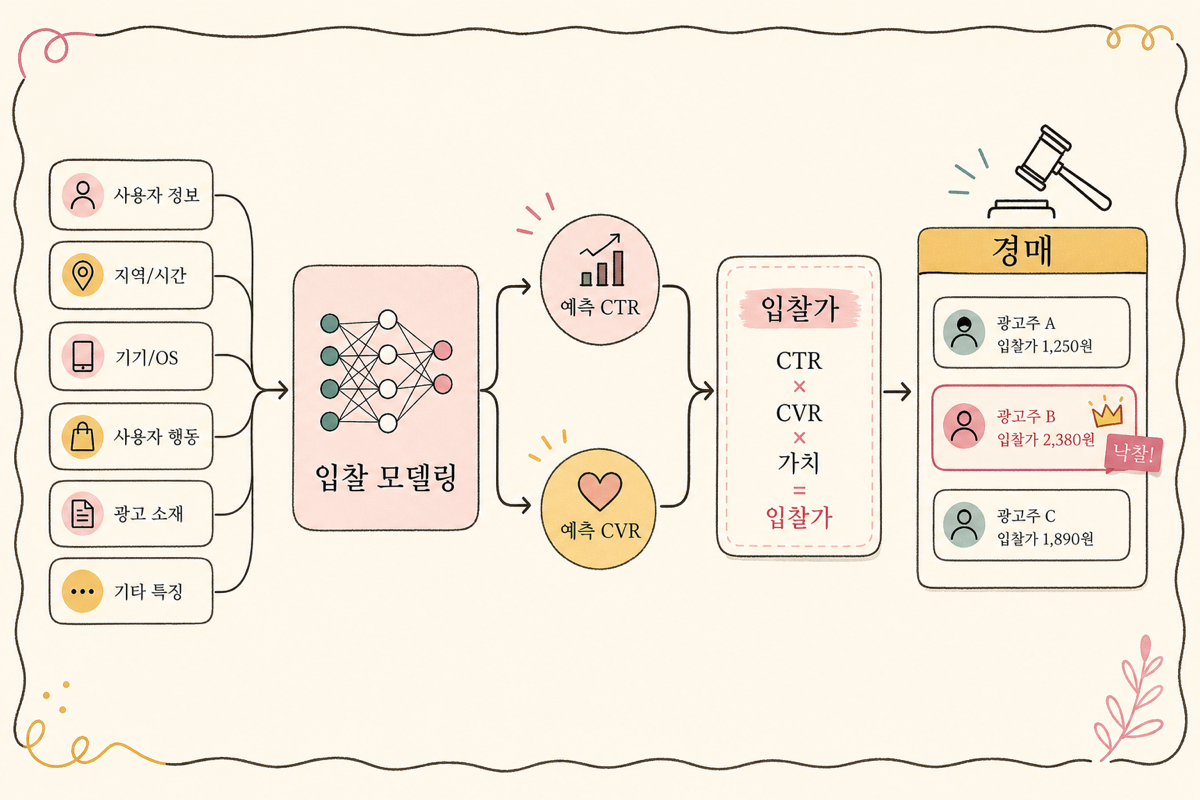
자동 입찰의 핵심 등식
광고 노출 한 번을 두고 광고주가 입찰할 가격은 그 노출이 만들 기대 가치보다 작거나 같아야 합니다. 그 기대 가치가 어디서 오는지가 머신러닝의 자리입니다.
가장 단순한 경우 — Cost per Click 입찰
CPC 입찰에서 광고주가 한 클릭에 최대 1,000원까지 지불할 수 있다면, 한 광고 노출의 기대 가치는 그 노출이 클릭으로 이어질 확률(pCTR) 곱하기 클릭당 가치입니다.
pCTR이 0.05일 때 bid = 0.05 × 1,000 = 50원입니다. 같은 광고도 클릭 가능성이 낮아 보이는 사람에게는 더 적게, 높아 보이는 사람에게는 더 많이 입찰합니다. 이 한 줄이 자동 입찰의 골격입니다.
Value-based bidding — 클릭 한 번에 다른 가치를 매김
ROAS 목표 캠페인은 클릭 가치 자체를 사람마다 다르게 봅니다. 클릭한 사람이 얼마짜리 구매를 할 확률(pCVR)과 평균 매출까지 곱해 들어갑니다.
이게 풀-퍼널 자동 입찰의 골격이고, 같은 캠페인 안에서도 사람마다 입찰가가 100배까지 차이 나는 이유입니다. ROAS 4를 목표로 한다면 분자가 4배 커야 같은 입찰을 합니다.
pCTR·pCVR — 두 예측 모델
광고 입찰의 ML은 거의 항상 두 모델로 나뉩니다.
pCTR — 클릭 확률 예측
입력 특성(features):
- 사용자 신호 — 디바이스·OS·세션 길이·과거 광고 인터랙션
- 컨텍스트 신호 — 시각·요일·페이지 카테고리·앱
- 광고 신호 — 크리에이티브 임베딩·카피 텍스트·광고주 카테고리
모델 종류는 logistic regression·factorization machines·심화한 deep learning(DLRM·Wide&Deep)까지 다양합니다. 광고 시장의 표준은 huge sparse feature(억 단위 카테고리)에 잘 맞는 logistic + embedding 조합입니다.
pCVR — 전환 확률 예측
pCVR이 더 어렵습니다. 클릭은 빈도가 15% 수준이지만 전환은 0.011% 수준이고, 라벨이 도착하는 시점이 며칠 늦습니다(delayed feedback). 그래서 pCVR은 데이터가 더 적고 노이즈가 더 큰 환경에서 학습됩니다.
가치 환산 — 클릭/전환을 돈으로
예측 확률만으로는 입찰을 못 합니다. 그 확률에 곱할 “값”이 필요합니다. 이 값을 어떻게 잡는지가 자동 입찰의 정확도를 결정합니다.
단순 평균 vs 사용자별 LTV
를 평균으로 잡으면 누구나 같은 가치를 갖습니다. 하지만 실제로는 한 번 사고 떠나는 사람과 정기 구매자가 섞여 있어, 사용자별 pLTV(predicted lifetime value)를 별도 모델로 추정하는 게 정확합니다.
pLTV 모델은 첫 며칠 행동 시그널로 30·60·90일 매출을 예측합니다. 이게 잘 잡히면 자동 입찰이 “오늘 매출이 큰 사람”이 아니라 “장기 가치가 큰 사람”에게 더 입찰합니다.
Bid Shading — first-price 경매에서 안 비싸게 이기기
광고 시장이 second-price에서 first-price로 옮겨오면서, “내가 부른 가격을 그대로 낸다”는 환경이 됐습니다. 그러면 입찰가를 그대로 쓰면 너무 비싸게 사게 됩니다. Bid shading은 입찰가에 할인 계수를 곱해 효율적인 가격을 만드는 기술입니다.
shading 모델은 과거 경매 결과를 학습해 “이 시장 상황에서 이 가치를 가진 입찰이 이기려면 얼마면 충분한가”를 추정합니다. shading이 잘 작동하면 같은 노출 수를 사면서 비용이 10~20% 줄어듭니다.
Pacing — 하루 예산을 고르게 쓰는 알고리즘
자동 입찰이 새벽에 좋은 기회를 놓치고, 저녁에 예산을 다 쓰면 안 되니까 하루 동안 예산이 고르게 쓰이도록 입찰가를 동적으로 조절합니다. 이게 pacing입니다.
Throttling — 입찰 빈도 조절
기대 입찰 횟수의 일부에만 참여합니다. 예산 잔량이 많으면 100% 입찰하고, 빠르게 줄면 50% → 30%로 낮춥니다.
Bid 조정 — 입찰가 자체 조절
매 시간마다 “남은 예산 / 남은 시간”으로 목표 소진 속도를 잡고, 실제 속도가 그보다 빠르면 입찰가를 낮추고 느리면 올립니다.
마케터가 이걸 알면 “왜 같은 캠페인이 오전엔 ROAS 5인데 저녁엔 ROAS 1.5”같은 의문을 더 잘 해석합니다 — pacing 알고리즘이 시간대별 입찰가를 다르게 잡아 결과 분포를 바꾼 신호일 수 있습니다.
자동 vs 수동 — 마케터가 만지는 다이얼
플랫폼이 ML로 입찰을 다 처리한다면 마케터가 만질 다이얼은 무엇이 남는가? 다음 4개입니다.
| 다이얼 | 설명 | 의사결정 빈도 |
|---|---|---|
| ROAS·CPA 목표 | 모델이 추구할 효율 기준 | 분기 |
| 예산 | 하루·캠페인 예산 한도 | 주 |
| 오디언스 | 모델이 학습할 사용자 풀 | 월 |
| 크리에이티브·카피 | 가치 환산의 입력 신호 | 주~월 |
이 4개가 수십 개의 ML 모델을 통제하는 출력 인터페이스입니다. 마케터의 일은 ML이 학습할 환경(데이터·목표·자원)을 잘 디자인하는 것이지, 입찰가를 직접 정하는 것이 아닙니다.
함정 모음
- cold start — 신규 캠페인은 학습 데이터가 부족해 첫 1~2주는 비효율적. exploration이 비싸다는 사실을 받아들여야 함
- label leakage — 학습 데이터에 미래 정보가 새어 들어가면 모델 평가에서는 좋아 보이지만 실전에서 실패
- survivorship — 입찰에 이긴 노출만 학습 데이터에 들어가 분포가 편향됨. 일부러 무작위 입찰 expose 할 때가 있음
- pCVR drift — 시즌·외부 충격으로 전환율 분포가 바뀌면 모델 재학습 필요
- auction dynamics 변화 — 경쟁자 입찰 전략 변화로 first-price 시장 균형이 흔들림
마치며
광고 입찰의 자동화는 한 번에 다 들어온 게 아니라 pCTR → pCVR → pLTV → bid shading → pacing 순으로 한 층씩 추가되어 왔습니다. 마케터가 이 안쪽을 들여다볼 일은 흔치 않지만, “왜 같은 캠페인의 ROAS가 그렇게 흔들리는가”를 묻는 순간에는 한 층 한 층의 동작을 알아둬야 답이 보입니다.
다음 분기에 한 번만 시도해 볼 만한 것은 자체 pLTV 시그널을 광고 플랫폼에 CAPI로 전송하는 흐름입니다. 외부 ML이 추정하는 LTV보다 내가 가진 1st-party 시그널이 더 정확할 가능성이 크고, 이걸 입찰 모델에 직접 입력으로 줄 수 있다면 자동 입찰의 정확도가 한 층 올라갑니다.
참고
- Google, “Smart Bidding overview”: https://support.google.com/google-ads/answer/7065882
- Meta, “Value optimization”: https://www.facebook.com/business/help/272081237637181
- “Bid Shading in First-Price Auctions” (Karlsson et al., 2019): https://arxiv.org/abs/1908.06605
- McMahan et al., “Ad Click Prediction: a View from the Trenches” (Google, KDD 2013): https://research.google/pubs/pub41159/
- “Delayed Feedback Model” (Chapelle, 2014): https://olivier.chapelle.cc/pub/delayed.pdf
퍼포먼스 마케팅 카테고리의 다른 글
전체 보기 →-
2026·06·05
ROAS 보고서가 늘 거짓말하는 이유 — incrementality 3대장
Meta 대시보드 ROAS 5가 실제로는 1.x인 이유. last-click·view-through·incremental 세 가지 ROAS의 차이와, holdout·geo-lift·ghost ads·conversion lift로 진짜 증분을 측정하는 법을 마케터 시선으로 정리합니다.
-
2026·05·16
DSP·SSP·DMP 인프라 해부 — 매체 영업 미팅에서 듣는 약자들의 정체
매체 영업 미팅에서 DSP, SSP, DMP, CDP, ad exchange, 헤더비딩 같은 약자들이 쏟아집니다. 각각이 어느 회사이고, 광고비가 어디로 흘러가며, 마케터가 의사결정할 때 어떤 의미를 갖는지 한 글에 정리합니다.
-
2026·05·16
Lookback window가 ROAS를 바꾸는 법 — click 7d, view 1d, 28d, 90d의 차이
같은 캠페인도 attribution lookback window를 click 7d, view 1d, 28d, 90d 중 어느 기준으로 보느냐에 따라 ROAS가 달라집니다. 최신 공식 설정과 비교 원칙을 정리합니다.
-
2026·05·09
Brand lift study 설계 — 광고가 인지·호감도를 끌어올렸나
브랜드 광고는 ROAS로 잡히지 않고 인지·호감도·구매의향으로만 측정됩니다. 노출 그룹과 비노출 그룹을 비교하는 brand lift study의 설계, 표본 계산, 실무 함정을 마케터 시선에서 정리.