CAC·LTV를 베이지안으로 추정하기 — 신규 채널, 손익분기는 언제 넘는가
신규 채널 첫 달, 가입자 60명. CAC 35,000원, LTV는 아직 모름. 손익분기 가능한 채널일까. 베이지안 hierarchical 모델로 LTV 분포를 추정해 의사결정의 분산을 같이 보고하는 법.
“신규 틱톡 캠페인 첫 달 CAC가 35,000원이야. 살릴까?” — 한 달 데이터로는 못 살려요. CAC는 분명한데 LTV가 미스터리거든요. 6개월·12개월 LTV가 얼마일지를 첫 달에 단정하면 거의 항상 틀립니다. 이 글은 베이지안으로 LTV 분포를 추정해서 “이 채널, 손익분기 가능성 73%” 같은 답을 내는 운영 워크플로우입니다.
왜 평균값으로 LTV를 보면 안 되나
LTV(Customer Lifetime Value)는 “한 명의 고객이 평생 가져다주는 매출”인데, 실무에서 가장 큰 함정은 이걸 평균 한 줄로 보고하는 거예요.
“전체 평균 LTV는 8.2만 원입니다.”
이 한 줄에 빠진 정보:
- 분산 — 어떤 고객은 1만 원에 이탈하고, 어떤 고객은 50만 원 쓴다
- 세그먼트 차이 — 채널·연령·시즌별로 LTV는 2~5배 차이 남
- 시점 효과 — 신규 채널의 첫 달 가입자 LTV가 6개월 평균보다 30% 낮은 게 흔함
- 불확실성 — 60명짜리 신규 채널 LTV는 사실상 “잘 모르겠다”
베이지안의 답: LTV를 단일 값이 아닌 분포로 추정한다. 그러면 의사결정이 “평균 8.2만 vs CAC 3.5만이니 흑자”가 아니라 “73% 확률로 흑자, 27% 확률로 적자”로 바뀝니다.
CAC는 쉬운 편 — 분자/분모만 정확하면 됨
CAC = (그 채널의 광고비) / (그 채널로 들어온 신규 고객 수)
표면은 단순한데, 실무에서 헷갈리는 게 “채널 귀속”이에요. 같은 사용자가 페이스북 광고 보고 → 나중에 검색해서 들어오면 어느 채널 CAC에 잡히나? 보통 first-touch 또는 last-touch 중 하나로 통일하면 됩니다. 정답은 없지만 일관성이 중요해요.
# 채널별 첫 달 CACimport pandas as pd
df = pd.DataFrame({ "channel": ["검색", "Meta", "유튜브", "틱톡(신규)"], "spend": [3_000_000, 2_500_000, 1_500_000, 800_000], "new_users": [180, 95, 42, 23],})df["cac"] = df["spend"] / df["new_users"]print(df)CAC 자체는 분명한데, 신규 채널 23명짜리 데이터로 “틱톡 CAC 34,782원”을 단정하기엔 표본이 너무 적어요. CAC도 사실은 신뢰구간을 같이 봐야 합니다(부트스트랩으로 간단 추정).
23명 가지고는 진짜 CAC가 25,000일 수도 53,000일 수도 있다는 의미. 이 폭이 의사결정을 흔드는 첫 번째 변수예요.
LTV는 진짜 어려움 — 시간이 안 흘렀잖아
LTV는 “평생” 가치인데, 그 평생을 다 봐야 알 수 있어요. 신규 가입자 60명 첫 달 데이터로 12개월 LTV를 추정하려면 모델이 필요합니다.
단순 방법: 첫 N일 매출 × 보정 계수
가장 흔한 빠른 방법.
문제: 보정 계수 12.4는 채널·시즌·코호트마다 다른데, 한 숫자로 통일됩니다. 신규 채널은 이게 안 맞을 수 있어요.
베이지안 방법: 채널 간 정보 빌리기 (hierarchical)
신규 채널은 데이터가 적지만, 다른 채널들의 LTV 분포 정보를 사전(prior)으로 끌어와 추정을 안정화합니다. 이게 hierarchical Bayesian의 핵심이에요.
수식으로 보면 두 단계 분포가 쌓여 있어요.
- 첫 줄: “전체 채널 평균 LTV”에 대한 매우 약한 사전
- 둘째 줄: 각 채널의 평균은 그 전체 평균 주위로 분포 (즉 “채널들이 서로 완전히 다르지는 않다”는 가정)
- 셋째 줄: 그 채널 안 사용자별 LTV는 채널 평균 주위로 분포
채널별 추정은 다음 표처럼 나옵니다.
| 채널 | 표본 N | 사후 평균 LTV | 95% HDI | 분포 폭 |
|---|---|---|---|---|
| 검색 | 180명 | 12,800 | [11,990, 13,620] | 좁음 ✅ |
| Meta | 95명 | 10,100 | [8,990, 11,210] | 적당 |
| 유튜브 | 42명 | 7,400 | [5,910, 8,890] | 약간 넓음 ⚠️ |
| 틱톡 (신규) | 23명 | 6,200 | [4,500, 7,950] | 가장 넓음 ⚠️ |
이 모델의 마법: 틱톡(데이터 23명) 추정이 다른 채널 분포 쪽으로 살짝 끌려갑니다. 23명만으로는 LTV 5,500이라고 단정할 수 없는데, 모델이 “다른 채널들 보면 이 정도가 평균이니까, 23명짜리 평균은 그쪽으로 살짝 보정해야 한다”고 알아서 해줘요. 이걸 shrinkage라고 부릅니다.
직관: 표본이 적은 채널일수록 “전체 평균 쪽으로 끌어당겨지는 힘”이 강합니다. 데이터가 충분히 모이면 그 힘이 약해져 자기 데이터 쪽으로 자연스럽게 가요. 데이터의 양이 신뢰의 강도를 자동으로 결정하는 게 hierarchical의 본질.
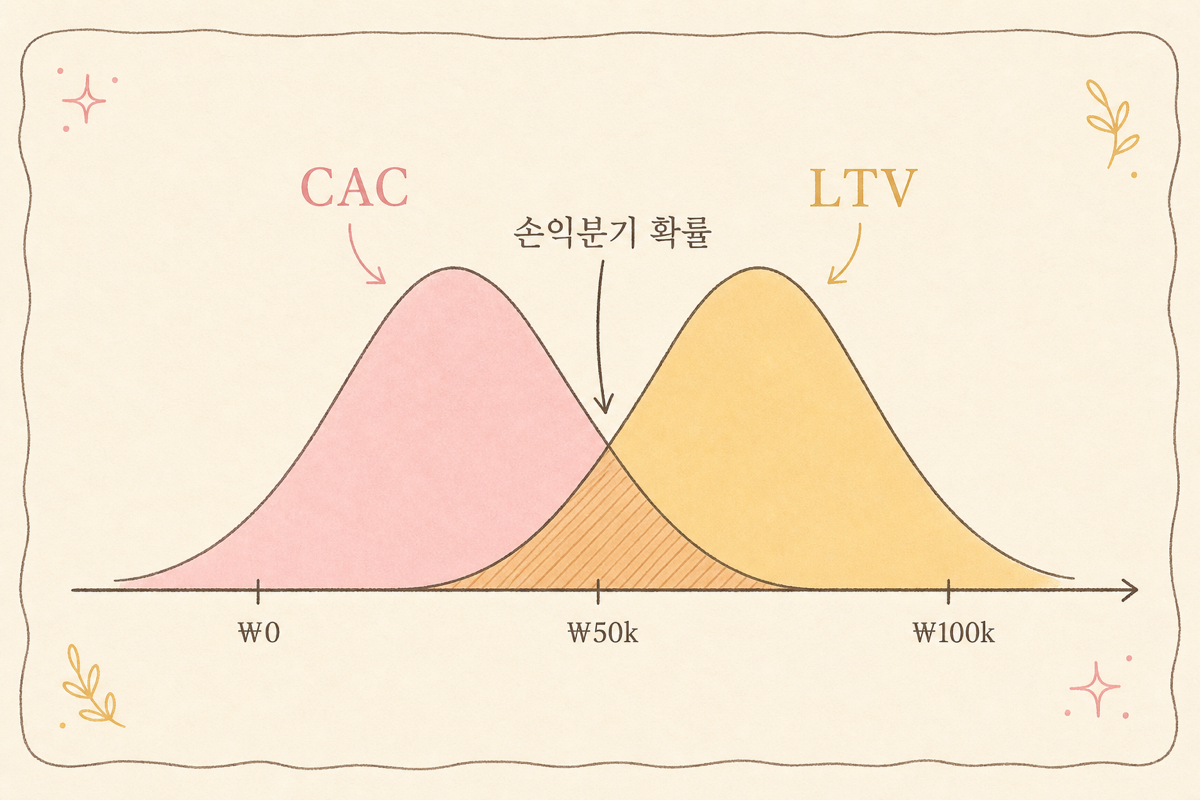
손익분기 확률 — CAC vs LTV의 정면 대결
신규 틱톡 채널: CAC 분포 95% CI [25k, 53k] vs 30일 LTV 분포 95% CI [4.5k, 7.9k]. 두 분포가 어떻게 만나는지가 손익분기 가능성의 답이에요.
수식으로는 두 분포에서 각각 샘플 개를 뽑아 비교한 비율:
(이걸 “몬테카를로 시뮬레이션”이라고 합니다. 분포끼리 직접 비교하는 베이지안의 표준 도구.)
| 시점 | 평균 LTV | 평균 CAC | P(LTV > CAC) | 의미 |
|---|---|---|---|---|
| 30일 (지금) | 6,200 | 36,540 | 0.0% | 단기엔 무조건 적자 (정상) |
| 6개월 (확장) | 16,800 | 36,540 | 7.4% | 여전히 적자 위험 큼 |
| 12개월 (코호트 만기) | 26,040 | 36,540 | 73.4% | 흑자 가능성 우세 |
해석: 틱톡 신규 채널은 12개월 시점에서 73% 확률로 흑자 채널이라는 답이 나옵니다. 평균 한 줄(“LTV 26k vs CAC 35k → 적자”)이라면 끄겠지만, 분포로 보면 더 부어볼 가치가 있는지 다시 생각하게 돼요.
Payback period 분포 — 언제 흑자 되는가
CAC를 회수하기까지 몇 개월 걸리는지를 분포로 봅니다. 누적 매출 곡선을 “포화형(saturating)” 함수로 모델링하면 직관이 단순해져요.
- = “절반 시점” 정도의 시간 상수 (보통 코호트 데이터로 7~10개월 추정)
- 이 곡선이 CAC를 처음 넘는 시점이 payback period
LTV 사후 분포에서 1,000개 샘플을 뽑아 각각 payback을 계산하면 다음 분포가 나와요.
| 통계량 | 값 |
|---|---|
| 중앙값 payback | 9개월 |
| 95% CI | [6, 17]개월 |
| 24개월 안에 회수 못 할 확률 | 18% |
해석: 평균적으로 9개월에 회수되지만, 운 나쁜 쪽은 17개월까지 걸리고, 18% 확률로는 24개월 안에도 회수 못 할 수 있다 — 이 정보가 “payback 9개월” 한 줄보다 100배 가치 있어요. 특히 “24개월 회수 실패 확률 18%“가 CFO·투자자에게 의사결정의 진짜 리스크를 보여줍니다.
운영 팁 — 마케터·CFO·투자자에게 어떻게 설명하나
1) 점추정과 분포를 같이 보고
대시보드에 “평균 LTV”만 띄우지 말고 “평균 + 신뢰구간”을 같이. 차트는 점이 아니라 얇은 점 + 굵은 막대(IQR) + 가는 막대(95% CI)로.
2) “확률”로 의사결정 임계 잡기
- “P(흑자) > 80%이면 채널 살리기”
- “P(payback < 12개월) > 70%이면 분기 예산 +20%”
이런 룰을 미리 정해두면 회의가 깔끔해져요.
3) 신규 채널엔 hierarchical, 성숙 채널엔 단순 모델
데이터 적은 신규 채널은 hierarchical로 다른 채널 정보 빌리기. 6개월 이상 운영해서 자체 코호트가 안정된 채널은 굳이 hierarchical 안 써도 됩니다.
4) 모델보다 코호트가 먼저
가장 큰 실수는 “코호트별로 LTV 곡선 안 분리하고 모델만 fancy하게”. 가입 월·채널·디바이스별 코호트를 먼저 깨끗하게 분리한 데이터가 모델보다 훨씬 중요해요.
마치며
마케터의 신규 채널 의사결정은 “이 채널 살릴까 끌까”가 아니라 “몇 % 확률로 손익분기 가능한가, 그 분산은 얼마나 큰가”가 되어야 합니다. 베이지안 hierarchical 모델은 신규 채널의 적은 데이터에 다른 채널 정보를 자연스럽게 빌려와 추정을 안정화해줍니다. 그 결과를 “73% 확률로 흑자, payback 9개월 [6~17]” 식으로 보고하면 의사결정의 차원이 한 단계 올라가요.
다음 글에서는 “쿠폰 줘도 살 사람과 줘야 사는 사람”을 가르는 uplift 모델링을 다뤄볼게요.
참고
- PyMC — Hierarchical Models 튜토리얼 — partial pooling의 표준 예제
- Customer Lifetime Value — Wharton 강의 노트 — LTV 모델링 학술적 기초
- Lifetimes (BTYD models) Python 라이브러리 — Beta-Geometric/NBD, Pareto/NBD 같은 LTV 표준 모델
- PyMC-Marketing — CLV 모듈 — 베이지안 CLV의 산업 표준
- Reforge — LTV/CAC Ratio 가이드 — 마케터 입장의 실무 해석
퍼포먼스 마케팅 카테고리의 다른 글
전체 보기 →-
2026·06·05
ROAS 보고서가 늘 거짓말하는 이유 — incrementality 3대장
Meta 대시보드 ROAS 5가 실제로는 1.x인 이유. last-click·view-through·incremental 세 가지 ROAS의 차이와, holdout·geo-lift·ghost ads·conversion lift로 진짜 증분을 측정하는 법을 마케터 시선으로 정리합니다.
-
2026·05·16
DSP·SSP·DMP 인프라 해부 — 매체 영업 미팅에서 듣는 약자들의 정체
매체 영업 미팅에서 DSP, SSP, DMP, CDP, ad exchange, 헤더비딩 같은 약자들이 쏟아집니다. 각각이 어느 회사이고, 광고비가 어디로 흘러가며, 마케터가 의사결정할 때 어떤 의미를 갖는지 한 글에 정리합니다.
-
2026·05·16
Lookback window가 ROAS를 바꾸는 법 — click 7d, view 1d, 28d, 90d의 차이
같은 캠페인도 attribution lookback window를 click 7d, view 1d, 28d, 90d 중 어느 기준으로 보느냐에 따라 ROAS가 달라집니다. 최신 공식 설정과 비교 원칙을 정리합니다.
-
2026·05·09
Brand lift study 설계 — 광고가 인지·호감도를 끌어올렸나
브랜드 광고는 ROAS로 잡히지 않고 인지·호감도·구매의향으로만 측정됩니다. 노출 그룹과 비노출 그룹을 비교하는 brand lift study의 설계, 표본 계산, 실무 함정을 마케터 시선에서 정리.