Creative testing scaling — 광고 소재 100개 평가의 운영 룰
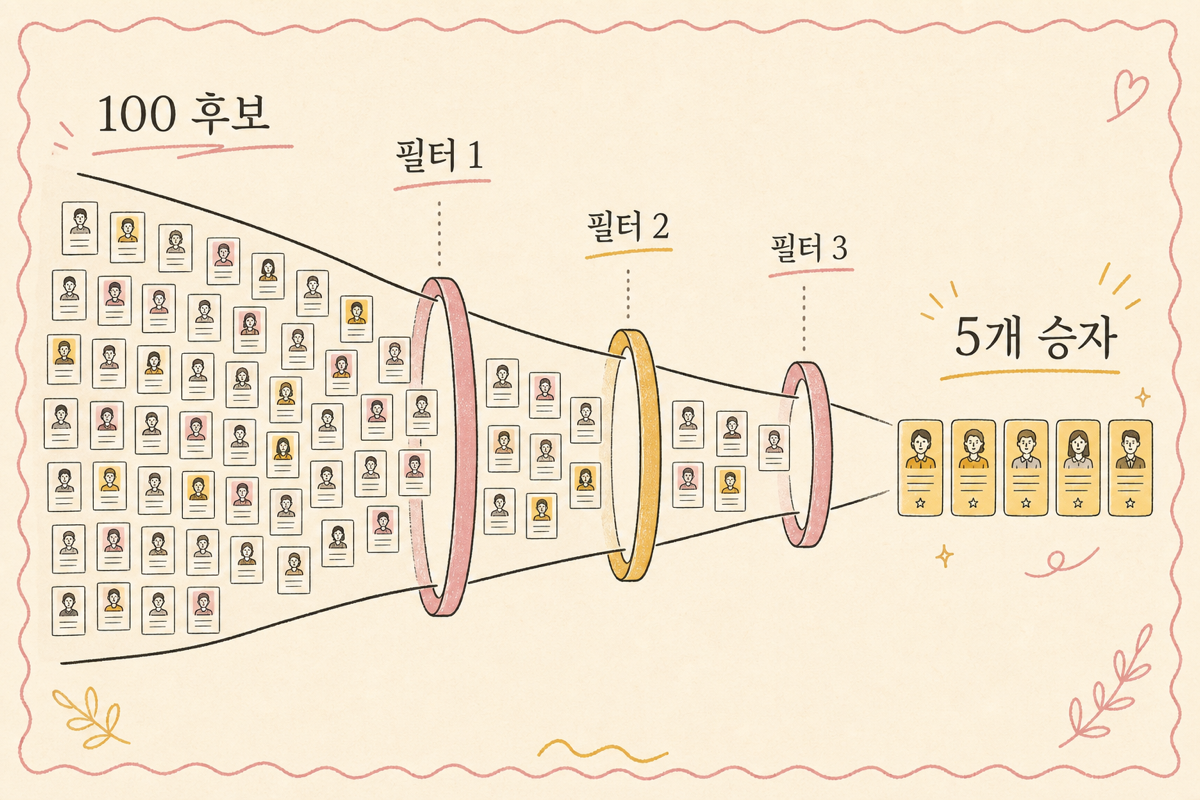
LLM이 광고 소재를 100개 만드는 시대에 운영자는 100개를 다 임프레션 태울 수 없습니다. 사전 필터·예산 분배·중도 cut의 3단계 룰로 100개를 5개로 추리는 자리. Multi-armed bandit·Thompson Sampling을 운영 캘린더에 박는 표준 패턴.
LLM이 광고 카피·이미지 변형을 한 번에 100개씩 뽑아 줍니다. 운영자는 100개에 다 예산을 태울 수 없습니다 — 표본 분산 폭증, 예산 비효율, 운영 부담. 100개를 5~10개로 추리는 운영 룰이 필요합니다. 사전 필터(LLM-as-judge) + 예산 분배(Thompson Sampling) + 중도 cut(sequential 룰)의 3단계 표준 패턴을 정리합니다.
1. 100개 소재 풀이 만드는 3가지 부담
LLM 기반 카피·이미지 자동 생성으로 소재 풀이 한 자리당 100개 수준이 됐습니다. 운영의 3가지 부담:
- 표본 분산 — 100개에 예산 균등하면 각 소재의 데이터가 너무 적어 신뢰 못 함
- 예산 비효율 — 명백히 나쁜 소재에도 예산 일부 태우면 손실
- 운영 부담 — 매주 100개 분석은 사람이 못 함
운영 룰의 한 줄 답:
100개를 5~10개로 빠르게 추리고, 그 안에서만 진짜 시장 검증.
이 추리기가 3단계로 이루어집니다.
- 사전 필터 — 시장에 노출 전 LLM·임베딩으로 필터링 (100 → 30)
- 예산 분배 — Thompson Sampling으로 소재별 예산 자동 (30 → 10)
- 중도 cut — sequential 룰로 명백히 나쁜 소재 조기 종료 (10 → 5)
각 단계의 도구를 정리합니다.
2. 1단계 — 사전 필터 (100 → 30)
시장 노출 전 단계. 임프레션 비용 없이 풀을 추립니다.
2-1. 임베딩 중복 제거
100개 중 임베딩 cosine 0.95 이상은 같은 메시지의 변형. 클러스터링으로 다양성 보장. 임베딩 운영 글 참조.
- 100개 → 클러스터 30개 → 각 클러스터의 대표 1개씩
2-2. LLM-as-judge 1차 필터
LLM-as-judge 글 참조. 평가 기준:
- 톤 적합성 (브랜드 가이드라인 준수)
- 길이·정보량 적정
- 명백한 실수(오타·이상한 단어) 없음
LLM-as-judge로 명백히 나쁜 30~50% 자동 제거. 남는 게 30개 정도.
2-3. 과거 데이터 사전 스코어링
과거 캠페인 데이터로 학습된 CTR·CVR 예측 모델로 소재 사전 평가. 예측 점수 하위 30%는 시장 노출 전에 빼냄.
# 사전 필터링 한 묶음filtered = []for c in candidates: if not similar_to_existing(c, threshold=0.95): # 중복 제거 if llm_judge_score(c) > 4.0: # LLM 1차 필터 if predicted_ctr(c) > 0.02: # 사전 예측 filtered.append(c)이게 본문에 박는 유일한 코드입니다. 3가지 필터의 결합 — 비용 거의 없이 100 → 30 추리기.
3. 2단계 — 예산 분배 (30 → 10)
30개 소재에 어떻게 예산을 분배할까. 균등 분배는 표본 부족, 직관 분배는 편향.
답은 Cold start Thompson Sampling. 각 소재의 CTR 사후 분포(Beta)에서 임프레션마다 샘플링해 가장 큰 값 선택. 자동으로:
- 데이터 적은 소재 → 사후 폭 넓음 → 가끔 큰 값 → 탐색
- 데이터 많고 좋은 소재 → 좁은 사후 → 안정적 활용
- 데이터 많고 나쁜 소재 → 좁은 사후, 낮은 평균 → 자동 제외
운영 결과:
- 첫 1주 — 모든 소재에 균등에 가까운 노출 (탐색)
- 둘째 주 — 좋은 소재에 트래픽 집중 (활용)
- 둘째 주 끝 — 상위 10개에 90% 트래픽
운영자가 매일 분석하지 않아도 자동으로 best 10이 떠오릅니다.
3-1. 콜드 스타트 사전
LLM 사전 점수·임베딩 거리를 Beta 사전의 시작점으로. 디폴트 Beta(1, 1) 대신 사전 점수 반영.
| 사전 점수 | Beta 사전 | 의미 |
|---|---|---|
| 4.5/5 | Beta(5, 95) | 보통 CTR 5% 기대 |
| 3.5/5 | Beta(3, 97) | 보통 CTR 3% 기대 |
| 2.5/5 | Beta(1, 99) | 보통 CTR 1% 기대 |
LLM·임베딩 정보가 사전 분포에 들어가면 첫 1주의 탐색 비용이 줄어듭니다.
4. 3단계 — 중도 cut (10 → 5)
Thompson Sampling이 자동으로 좋은 소재에 트래픽을 몰지만, 명백히 나쁜 소재를 더 빨리 끊고 싶은 자리. Sequential testing이 그 자리.
각 소재에 always-valid 95% 신뢰구간을 매일 계산. 상한이 baseline 평균보다 낮으면 — 즉, “이 소재가 평균보다 좋을 가능성이 사실상 0”이면 — 자동 cut.
| 시점 | 소재 | always-valid 95% CI | 판정 |
|---|---|---|---|
| Day 5 | A | [0.02, 0.08] | 유지 |
| Day 5 | B | [0.005, 0.025] | cut (상한 < baseline 0.03) |
| Day 5 | C | [0.04, 0.12] | 유지 |
이 룰이 깔리면 명백히 나쁜 소재는 5~7일 안에 자동 종료. 트래픽이 좋은 소재로 더 빨리 집중됩니다.
5. 마케팅 실무 케이스 3개
5-1. 광고 카피 자동 생성·평가 파이프라인
LLM이 매주 100개 카피 생성. 사전 필터로 30개, Thompson 1주 운영으로 10개, sequential cut으로 5개 finals. 운영자 매주 30분으로 진짜 시장 검증된 best 5를 손에 받음.
5-2. 이미지 소재 testing
이미지 30개 변형. 사전 필터에 image embedding 거리를 추가해 다양성 보장. Thompson으로 노출 자동 분배. 시각 소재의 시장 반응을 사람 직관 없이 데이터로 결정.
5-3. 이메일 subject line testing
같은 메일 발송 전 50개 subject 변형. 사전 LLM 필터 + 5,000명에 Thompson 분배 + 1일 후 cut. best 3 subject로 95,000명 본 발송. open rate 평균 15~25% 향상이 일반적.
6. 운영이 깨질 때 — 흔한 함정 3가지
6-1. 사전 필터가 진짜 시장과 다름
LLM-as-judge·임베딩 점수가 진짜 CTR과 다른 자리. 시장 검증 결과 vs 사전 점수의 일치율을 매주 측정. 65% 미만이면 사전 필터 신뢰 못 함, 다시 학습 필요.
6-2. Thompson 사전이 너무 강함
Beta(50, 950) 같은 강한 사전은 데이터가 와도 잘 안 움직입니다. Beta(3, 97) 정도의 약한 사전이 표준. Cold start 글 참조.
6-3. Sequential cut 임계가 너무 보수적
cut 임계가 너무 보수적이면 명백히 나쁜 소재가 1주 더 살아 예산 낭비. 도메인에 맞춰 임계 조정. 첫 분기는 보수적, 점차 공격적으로.
7. 마치며 — 100개 시대의 운영 표준
LLM·생성형 AI가 마케팅 소재를 100개씩 뽑아내는 시대에, 운영의 핵심은 “다 노출하기”가 아니라 “빨리 추리기”입니다. 3단계 funnel — 사전 필터·예산 분배·중도 cut — 이 운영 캘린더의 표준이 되어가고 있습니다.
운영자가 챙겨야 할 흐름:
- 주간 사이클 — 100개 생성 → 30 사전 → 10 Thompson → 5 finals
- 분기 검증 — 사전 필터 정확도·Thompson 수렴 점검
- 연간 재학습 — 사전 모델·Beta 사전·cut 임계 재추정
이 인프라가 깔리면 마케팅 팀 1명이 매주 100개의 가능성을 5개의 시장 검증 결과로 변환할 수 있습니다.
다음 글에서는 같은 자리의 또 다른 도구, customer segmentation의 mixture model을 다룹니다. k-means 너머의 세그먼테이션 도구.
참고
- Schwartz, Bradlow & Fader (2017), Customer Acquisition via Display Advertising Using Multi-Armed Bandit Experiments, Marketing Science — MAB 광고 표준 사례
- Russo, Van Roy, Kazerouni, Osband, Wen (2018), A Tutorial on Thompson Sampling — Thompson 산업 적용
- Kohavi, Tang & Xu (2020), Trustworthy Online Controlled Experiments — 실험 운영 표준 교과서
- Vowpal Wabbit — contextual bandit 운영 표준
- Meta Advantage+ Creative — 매체 표준 자동화
- huny.log 내부 글: LLM 카피 파이프라인, Cold start Thompson, Sequential testing, LLM-as-judge, 임베딩 운영
그로스해킹 카테고리의 다른 글
전체 보기 →-
2026·05·16
AARRR을 진짜 운영하는 법 — North Star metric, funnel ops, growth loop의 실전 가이드
AARRR(acquisition·activation·retention·referral·revenue)는 그로스해킹의 기본 프레임이지만 실제 운영에서는 자주 깨집니다. North Star metric 정의, 단계별 funnel ops, growth loop 설계까지 실전 가이드로 정리합니다.
-
2026·05·10
코호트 LTV 곡선 — 누적 매출 그래프 그리고 해석하기
평균 LTV 한 숫자로는 채널·시즌·세그먼트 차이가 안 보입니다. 코호트별 누적 매출 곡선을 그려 그 차이를 시각적으로 잡고, 곡선 모양으로 운영 결정을 내리는 표준 워크플로.
-
2026·05·10
ROAS·CAC·LTV — 세 숫자 서로 다른 질문에 답하는 이유
회의에서 ROAS만 들고 가면 장기·LTV가 빠지고, CAC만 보면 광고 효율이 빠집니다. 세 숫자를 한 슬라이드에 입체적으로 두는 표준 양식과 의사결정 프레임.
-
2026·05·10
CAC Payback period — 광고비를 몇 개월 만에 회수하는가
CAC 한 번 쓰고 끝이 아닙니다. 그 광고비를 매출로 회수하는 데 몇 개월 걸리는지가 현금흐름·재투자 속도를 결정합니다. payback period 계산·운영 룰·SaaS vs 이커머스 차이.