코호트 retention curve의 운영 해석 — 같은 곡선에서 5가지 질문 빼내기
D1·D7·D30 retention 한 줄 같이 보지만 그 곡선에는 5가지 다른 질문이 숨어 있습니다. 곡선의 모양이 안정화되는가·기울기가 어디서 꺾이는가·코호트 간 폭이 좁혀지는가. 운영자가 같은 그래프에서 다른 의사결정을 빼내는 법을 정리합니다.
“D7 retention 32%인데 좋은 거예요?” 이 질문은 잘못된 출발점입니다. retention 한 숫자는 운영 의사결정에 너무 적은 정보를 줍니다. 같은 코호트 retention curve에는 최소 5가지 질문이 숨어 있습니다 — 곡선이 안정화되는가, 기울기가 어디서 꺾이는가, 코호트 간 폭이 좁아지는가. 운영자가 같은 그래프에서 다른 의사결정을 빼내는 법을 정리합니다.
1. retention curve의 5가지 정보 층
코호트 retention curve는 한 모양의 곡선이지만 그 안에 다섯 종류의 정보가 들어있습니다.
- 레벨 — 곡선이 어디 즈음에 있나 (D1·D7·D30 절대값)
- 기울기 — 어디서 가파르게 빠지고 어디서 평탄해지나
- 안정화 — 장기적으로 꼬리가 0에 닿나, 아니면 평행선을 그리나
- 코호트 간 변화 — 신규 코호트가 이전보다 잘 남나
- 세그먼트 폭 — 같은 코호트 안에서 채널·디바이스별 차이
레벨만 보고하면 다른 4개의 정보가 사라집니다. 운영 의사결정이 단조로워지는 가장 큰 이유입니다. 5가지를 한 그래프에서 같이 빼내는 습관이 retention 분석의 표준이 되어야 합니다.
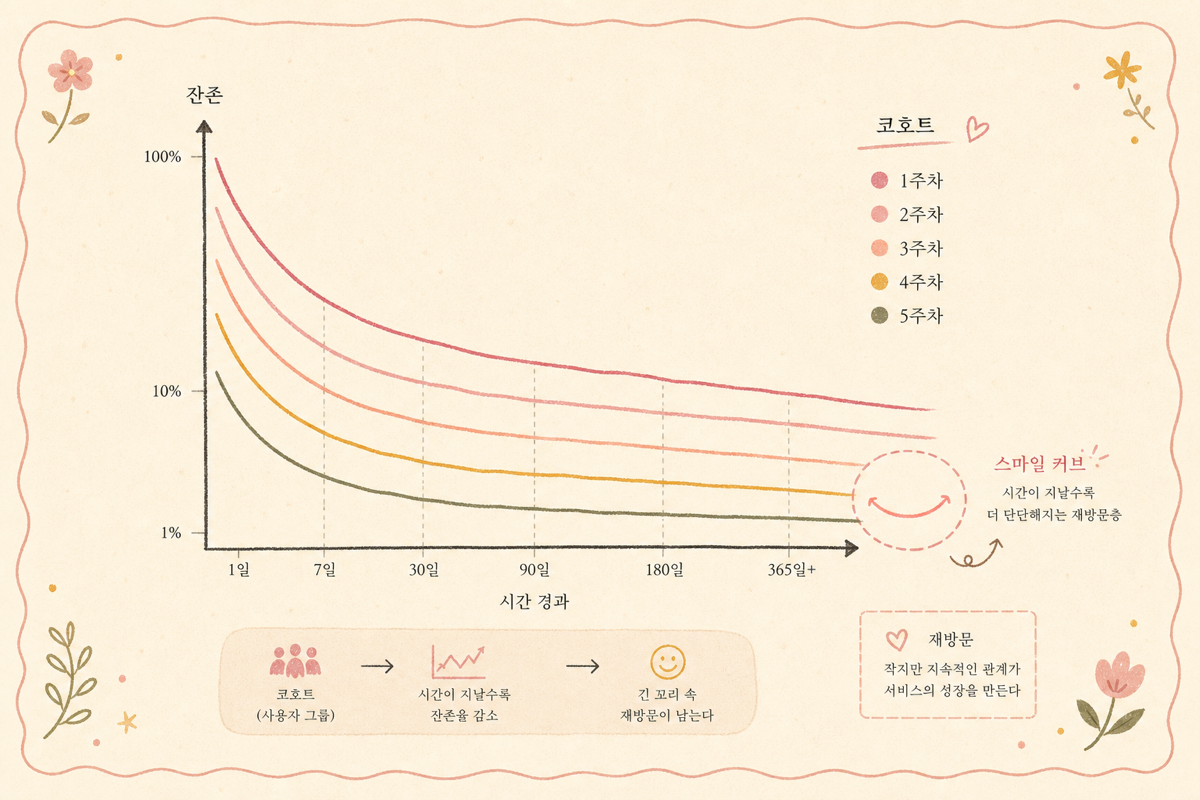
2. 레벨 — D1·D7·D30이 단독으로 답할 수 없는 것
D7 retention 32%가 좋은지 아닌지의 답은 비즈니스에 따라 완전히 다릅니다. 캐주얼 게임은 32%면 양호, 구독 서비스는 32%면 위기입니다. 절대값으로 의사결정하는 건 운영 첫 해의 함정입니다.
레벨이 운영 가치를 가지는 자리는 두 곳입니다.
- 같은 비즈니스의 시계열 비교 — 우리 D7이 6개월 전 28%에서 32%로 갔다
- 같은 비즈니스 안의 세그먼트 비교 — 신규 채널 D7 22% vs 기존 28%
벤치마크와 비교는 위험합니다. “업계 평균 D7 30%“는 평균치가 어떤 비즈니스 모델·어떤 정의·어떤 OS로 묶였는지 정확히 모릅니다. 자기 시계열·자기 세그먼트만 신뢰하세요.
3. 기울기 — 어디서 꺾이는가
retention curve의 두 번째 정보는 기울기 변화 지점입니다. 가장 흔한 패턴은 다음입니다.
- D0~D1 사이의 큰 떨어짐 — 첫 사용 충격
- D1~D7 사이의 점진적 떨어짐 — 학습·습관 형성 구간
- D7~D30 사이의 평탄화 — 충성 코호트 안정화
가장 가파른 구간(보통 D0~D1)은 “첫 사용 경험” 문제입니다. 첫 화면·첫 작업·첫 보상이 너무 약하거나 너무 어려운 신호입니다. 가장 평탄한 구간(보통 D14 이후)은 “충성 코호트의 베이스 라인”입니다. 이 베이스 라인 자체가 비즈니스의 LTV를 결정합니다.
운영 결정의 한 줄 패턴은 다음입니다.
첫 가파른 구간을 완만하게 만드는 게 단기 효과, 마지막 평탄한 구간을 끌어올리는 게 장기 효과.
신규 캠페인·온보딩 개선은 첫 구간에 작동, CRM·기능 개선은 마지막 구간에 작동. 마케터는 두 자리를 구분해서 KPI를 다르게 묶어야 합니다.
4. 안정화 — 꼬리가 평행이 되는가
retention curve의 가장 중요한 진단 — 꼬리가 0에 닿느냐, 아니면 어떤 수치에서 평행을 그리느냐.
꼬리가 0에 닿으면 모든 유저가 결국 떠나는 비즈니스 — 캐주얼 게임의 일부, 일회성 거래 위주 이커머스. 꼬리가 양수 에서 평행을 그리면 충성 코호트가 자리잡는 비즈니스 — 구독·앱·이메일·B2B SaaS.
평행이 되는 자리의 이 비즈니스의 진짜 가치 주체입니다. Reforge·Sean Ellis 프레임에서 강조하는 “smile curve”가 이 자리입니다. 신규 유입의 일부가 평행 코호트로 정착하면 retention curve의 꼬리가 위로 올라가는 모양이 나옵니다.
| 패턴 | 모양 | 비즈니스 | 운영 결정 |
|---|---|---|---|
| 꼬리가 0으로 | 단순 감쇠 | 일회성 거래 | 신규 유입에 의존, CAC 회수 빠르게 |
| 꼬리가 양수 평행 | flat 꼬리 | 구독·앱·SaaS | 평행 코호트의 LTV가 핵심 |
| 꼬리가 위로 | smile | 강한 충성 | resurrected user·핵심 사용 패턴 |
5. 코호트 간 변화 — 우리가 좋아지고 있는가
retention curve의 진짜 운영 가치는 “어제 대비 오늘”이 아니라 “이번 달 코호트 vs 지난 분기 코호트”의 비교입니다. 같은 곡선이 시계열로 어떻게 변하는가.
좋은 코호트 변화의 신호는 다음입니다.
- 새 코호트의 D7이 같은 계절의 작년 코호트보다 높음
- 새 코호트의 평탄화 자리가 더 높음
- 새 코호트의 꼬리가 0이 아닌 양수에서 안정화
흔한 운영 함정은 “새 코호트의 D1이 더 높은데 D30은 더 낮다” 같은 패턴입니다. 신규 유입 채널의 첫 사용은 좋지만 정착으로는 안 이어진다는 신호입니다. 이런 자리는 채널 평가의 단위를 D1에서 D30 또는 평탄화 자리로 옮겨야 합니다.
6. 세그먼트 폭 — 평균이 가리는 것
retention curve의 평균 한 줄은 세그먼트 간 큰 차이를 가립니다. 같은 D7 32%가 채널·디바이스·신규/기존별로 다음처럼 나뉘는 경우가 흔합니다.
- iOS 신규: D7 28%
- iOS 기존: D7 41%
- Android 신규: D7 22%
- Android 기존: D7 35%
이 분해를 안 보면 “iOS·Android 합쳐서 32%“라는 한 숫자만 남습니다. 같은 곡선을 채널·디바이스·코호트별로 나눠 그리는 습관이 retention 분석의 두 번째 표준입니다.
import pandas as pd
# events: ['user_id', 'segment', 'cohort_week', 'day_offset', 'active']ret = (events.groupby(['segment', 'cohort_week', 'day_offset'])['active'] .mean().unstack('day_offset'))print(ret.head())이게 본문의 유일한 코드입니다. pandas 한 묶음으로 세그먼트 × 코호트 × 일자별 retention 매트릭스가 나옵니다. 이걸 시각화한 게 코호트 retention 히트맵의 출발입니다.
7. 마케팅 실무 케이스 3개
7-1. 신규 캠페인 평가 — D1 vs 평탄화 자리의 분리
새 광고 캠페인의 D1 retention이 기존보다 5%p 높은데 D30은 3%p 낮습니다. D1 기준으로는 성공, D30 기준으로는 실패. 운영 결정은 둘 중 어느 쪽에 더 가중치를 둘지에 달려 있습니다. 신규 채널 평가의 단위를 처음부터 평탄화 자리로 잡으면 단기 호조에 속지 않습니다.
7-2. CRM 개선의 효과 — 꼬리만 변화시킨다
푸시·이메일 같은 CRM 개선은 보통 D1·D7에는 거의 영향이 없고, D30 이후의 꼬리에만 영향을 줍니다. 짧은 기간 평가로는 효과가 안 보이지만, retention curve의 꼬리만 따로 보면 평행선이 위로 올라가는 게 보입니다. CRM KPI를 D7에서 D30 또는 평탄화 자리로 옮기는 게 평가 정합성을 만듭니다.
7-3. 가격 변경 후 retention curve의 모양 변화
가격 인상은 retention curve의 모양을 통째로 바꿉니다. 새 가격에 맞는 새 유저가 들어와 평탄화 자리가 더 높아질 수도 있고, 가격 민감 유저가 빠져 꼬리가 더 빨리 0으로 갈 수도 있습니다. 가격 변경 후 12주 retention curve를 비교해보면 가격 효과가 도착했는지가 명확해집니다.
8. retention 분석이 깨질 때 — 흔한 함정 3가지
8-1. retention의 정의가 모호하다
“D7 retention”이 사실 “첫 7일 안에 한 번이라도 다시 방문”인지 “정확히 7일째에 방문”인지에 따라 숫자가 통째로 다릅니다. 정의를 한 줄로 명시하지 않은 retention 보고는 비교 자체가 깨집니다. 회사 안에서 정의를 한 번 정리하고 그 정의로 통일해야 합니다.
8-2. 코호트 정의가 너무 거칠다 또는 너무 잘다
월 단위 코호트는 큰 흐름이 보이지만 채널 캠페인 단위 신호가 묻힙니다. 일 단위 코호트는 신호가 너무 노이지합니다. 주 단위가 보통 좋고, 큰 캠페인 시점에서만 이벤트 단위 코호트를 따로 봅니다.
8-3. 평균만 보고 분포를 안 본다
retention의 평균은 평행 코호트와 빠르게 떠나는 코호트의 합입니다. 분포를 안 보면 평균이 좋아졌을 때 어디가 좋아졌는지 모릅니다. 코호트 retention 히트맵을 같이 그려야 어떤 세그먼트·어떤 시기 코호트가 변화시켰는지가 보입니다.
9. 마치며 — 같은 그래프에서 다른 질문을 빼내라
retention curve가 마케터에게 주는 진짜 가치는 한 숫자가 아니라 같은 곡선에서 의사결정에 필요한 다른 신호를 분리하는 도구입니다.
- 첫 사용 → 가파른 첫 구간
- 학습·습관 → 중간 기울기
- 충성·평행 → 꼬리 안정화
- 우리가 나아지는가 → 코호트 간 변화
- 어디가 다른가 → 세그먼트 폭
5가지 정보 층 중 어느 한두 개에 집중해 보고하는 운영 패턴을 만들면 retention 분석의 깊이가 달라집니다.
다음 글에서는 같은 마케팅 데이터의 또 다른 구조, switchback experiment를 다룹니다. 같은 유저에게 ON/OFF를 번갈아 적용하는 실험 설계입니다.
참고
- Reforge — Retention Engine 프레임 — 코호트 retention의 운영 프레임 표준
- Sean Ellis · Brian Balfour, Growth 시리즈 — retention 5층 정보 프레임의 출발
- Andrew Chen, The Cold Start Problem (2021) — 신규 코호트 retention 분석
- Amplitude — Retention 표준 정의 — 코호트 정의·집계 방법론
- Mixpanel — Cohort retention 가이드 — 운영 도구의 표준 적용
- huny.log 내부 글: BG/NBD LTV, CAC·LTV 베이지안, Uplift 모델링
그로스해킹 카테고리의 다른 글
전체 보기 →-
2026·05·16
AARRR을 진짜 운영하는 법 — North Star metric, funnel ops, growth loop의 실전 가이드
AARRR(acquisition·activation·retention·referral·revenue)는 그로스해킹의 기본 프레임이지만 실제 운영에서는 자주 깨집니다. North Star metric 정의, 단계별 funnel ops, growth loop 설계까지 실전 가이드로 정리합니다.
-
2026·05·10
코호트 LTV 곡선 — 누적 매출 그래프 그리고 해석하기
평균 LTV 한 숫자로는 채널·시즌·세그먼트 차이가 안 보입니다. 코호트별 누적 매출 곡선을 그려 그 차이를 시각적으로 잡고, 곡선 모양으로 운영 결정을 내리는 표준 워크플로.
-
2026·05·10
ROAS·CAC·LTV — 세 숫자 서로 다른 질문에 답하는 이유
회의에서 ROAS만 들고 가면 장기·LTV가 빠지고, CAC만 보면 광고 효율이 빠집니다. 세 숫자를 한 슬라이드에 입체적으로 두는 표준 양식과 의사결정 프레임.
-
2026·05·10
CAC Payback period — 광고비를 몇 개월 만에 회수하는가
CAC 한 번 쓰고 끝이 아닙니다. 그 광고비를 매출로 회수하는 데 몇 개월 걸리는지가 현금흐름·재투자 속도를 결정합니다. payback period 계산·운영 룰·SaaS vs 이커머스 차이.