Customer segmentation 너머 — k-means 아닌 mixture model로 세그먼트 다루기
k-means는 모든 유저를 한 세그먼트에 강제로 박습니다. 실제 유저는 여러 세그먼트의 혼합 — 평일엔 직장인, 주말엔 부모. Gaussian Mixture Model이 같은 데이터에 확률적 세그먼트 멤버십을 줍니다. 마케터가 운영에 가져갈 또 다른 세그멘테이션 도구.
“이 유저는 어느 세그먼트인가요?”의 답이 늘 한 개여야 할 이유가 있을까요. 평일엔 직장인 캠페인, 주말엔 부모 캠페인이 잘 듣는 같은 유저. k-means는 한 세그먼트만 강제 배정하지만, 실제 행동은 여러 세그먼트의 혼합입니다. Gaussian Mixture Model(GMM)·Latent Class Analysis 같은 mixture model은 유저의 확률적 멤버십을 추정합니다. 같은 행동 데이터에서 더 풍부한 세그멘테이션을 빼내는 도구.
1. k-means의 한계 — hard assignment
k-means는 마케팅 BI에서 가장 흔한 클러스터링 도구입니다. 단순하고 빠르고 운영 가벼움. 그런데 한 가지 가정이 강합니다.
모든 유저를 정확히 한 세그먼트에 hard assign.
이 가정의 운영 한계:
- 경계 유저 — A·B 두 세그먼트 사이의 유저도 한쪽에 강제 박힘
- 혼합 행동 — 직장인 + 부모 행동을 섞은 유저는 한 세그먼트만 받음
- 불확실성 정보 손실 — “이 유저가 A 세그먼트일 확률”의 정보 사라짐
마케팅 캠페인 타겟팅에서 이 한계가 비용을 만듭니다.
- 경계 유저에 한 메시지만 보내면 다른 효과를 놓침
- 혼합 행동 유저는 두 캠페인 모두에 적합한데 한 쪽만 받음
- 캠페인 평가 시 세그먼트 멤버십이 흔들리면 결과 해석이 깨짐
mixture model은 이 hard assignment를 soft probabilistic membership으로 바꿉니다. 같은 데이터에 더 풍부한 정보.
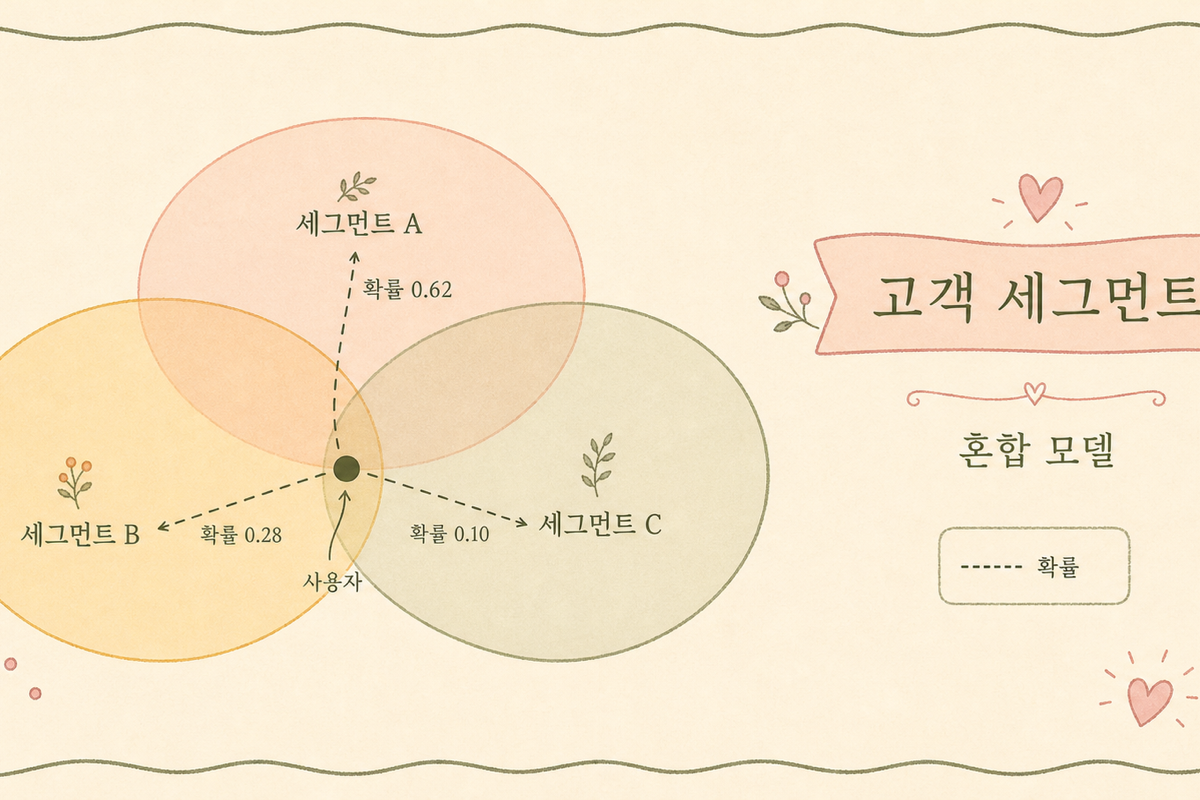
2. GMM의 한 줄 직관
Gaussian Mixture Model의 한 줄 직관:
데이터를 K개의 Gaussian 분포의 혼합으로 모델링. 각 유저는 K개 분포 중 어디에서 나왔을 확률을 가진다.
수식으로:
여기서 는 세그먼트 의 사전 비중, 는 평균·공분산 가진 Gaussian. 각 유저 의 사후 멤버십:
직관: 분자는 “세그먼트 가 이 유저를 얼마나 잘 설명하는가”, 분모는 모든 세그먼트의 설명력 합. 이 비율이 사후 멤버십 확률.
각 유저가 모든 세그먼트에 대해 멤버십 확률을 받습니다. 합이 1.
운영적 의미:
- 경계 유저 — Pr(A) = 0.55, Pr(B) = 0.45 같이 표현
- 혼합 행동 — Pr(직장인) = 0.4, Pr(부모) = 0.6
- 명확한 유저 — Pr(A) = 0.95, Pr(나머지) = 0.05
3. EM 알고리즘 — GMM이 파라미터를 학습하는 방법
GMM을 학습시키는 엔진이 EM(Expectation-Maximization) 알고리즘입니다. 왜 EM인가를 이해하면 GMM이 언제 잘 작동하고 언제 실패하는지가 보입니다.
E-step: “각 점이 어느 클러스터에 속할 확률 추정”
현재 파라미터(, , )를 고정한 채, 모든 유저에 대해 사후 멤버십 확률을 계산합니다.
직관: “지금 알고 있는 클러스터 모양으로 봤을 때, 이 유저는 어느 클러스터에서 나왔을 것 같나?” 를 각 유저마다 계산.
M-step: “그 확률로 가중평균해 파라미터 업데이트”
E-step에서 계산한 를 가중치로 삼아 파라미터를 다시 추정합니다.
직관: “클러스터 k에 속할 확률이 높은 유저들을 더 많이 반영해서 클러스터 중심·분산을 다시 계산.” 가 클수록 그 유저가 클러스터 k의 파라미터 추정에 더 많이 기여.
이 E·M 두 단계를 수렴할 때까지 반복합니다. 수렴 보장이 있고(log-likelihood 단조 증가), 구현이 단순합니다.
4. K(세그먼트 수)를 어떻게 정하나 — BIC 실예시
GMM의 가장 어려운 자리. K가 너무 작으면 세분화 부족, 너무 많으면 운영 부담.
BIC·AIC 수식
은 likelihood, 는 파라미터 수, 은 데이터 수. BIC는 모델 복잡도에 페널티를 줍니다. AIC보다 보수적 — 작은 K를 더 선호.
K=2~10 모델 fit 후 BIC 곡선 코드
아래 코드가 K를 자동으로 탐색하고 BIC 곡선을 그려 “꺾이는 지점”을 찾아줍니다.
import numpy as npimport matplotlib.pyplot as pltfrom sklearn.mixture import GaussianMixture
X = customer_features # (n_users, n_features)
bic_scores = []aic_scores = []k_range = range(2, 11)
for k in k_range: gmm = GaussianMixture( n_components=k, covariance_type="full", n_init=10, # 여러 초기화 중 최선 선택 random_state=42, ).fit(X) bic_scores.append(gmm.bic(X)) aic_scores.append(gmm.aic(X))
# BIC가 가장 낮은 K 선택best_k = k_range[np.argmin(bic_scores)]print(f"BIC 최적 K = {best_k}") # 예: BIC 최적 K = 5
# 시각화 — 꺾이는 지점(elbow)이 최적 Kplt.figure(figsize=(8, 4))plt.plot(list(k_range), bic_scores, marker="o", label="BIC")plt.plot(list(k_range), aic_scores, marker="s", linestyle="--", label="AIC")plt.axvline(best_k, color="red", linestyle=":", label=f"Best K={best_k}")plt.xlabel("K (세그먼트 수)")plt.ylabel("Information Criterion")plt.legend()plt.title("BIC/AIC vs K — 꺾이는 지점이 최적 세그먼트 수")plt.tight_layout()plt.savefig("bic_curve.png", dpi=150)결과 해석: BIC 곡선이 K=5에서 꺾이고 K=6 이후 완만해진다면 K=5가 수학적 최적입니다. 이때 운영적으로 5개 세그먼트를 관리할 수 있는지도 함께 판단합니다. 보통 4-7개 안에서 BIC 최솟값을 고르는 게 마케팅 운영에서 현실적입니다.
운영 적합성
운영적으로 의미 있는 K는 보통 4-7개. 캠페인 디자인·메시지 변형이 너무 많으면 운영 부담. 4-7 안에서 BIC가 가장 낮은 K가 표준.
Bayesian Nonparametric (Dirichlet Process)
K를 미리 안 정하고 데이터가 알아서 결정. 운영 부담 크지만 K 결정의 주관성 사라짐.
| 도구 | K 결정 | 적용 |
|---|---|---|
| BIC·AIC | 수학적 | 사전 K 후보 5-10 |
| Cross-validation | 도메인 메트릭 | 운영 메트릭이 명확할 때 |
| Dirichlet Process | 자동 | 새 도메인·탐색적 분석 |
5. 마케팅 운영의 활용 — soft membership으로 무엇을 하나
5-1. soft 타겟팅
같은 유저에게 여러 캠페인을 멤버십 확률에 비례해 노출:
- Pr(A) = 0.7 → 캠페인 A에 우선 노출, 빈도 높게
- Pr(A) = 0.4 → 캠페인 A·B 둘 다에 노출, 각각 빈도 중간
- Pr(A) = 0.1 → 캠페인 A는 거의 노출 안 함
기존 hard assignment 기준 가장 가까운 1개 캠페인만 받았던 자리에서, 멤버십 비례 분배가 가능해집니다.
5-2. 세그먼트별 LTV 가중 계산
soft membership의 가장 강력한 활용입니다. 각 유저의 LTV 기댓값을 멤버십 확률로 가중 평균하면 경계 유저의 LTV를 더 정밀하게 추정합니다. 이 LTV 추정치는 BG/NBD LTV 모델과 결합해 세그먼트별 예산 배분의 입력으로 쓸 수 있습니다.
from sklearn.mixture import GaussianMixtureimport numpy as npimport pandas as pd
X = customer_features # (n_users, n_features)ltv_per_user = ltv_array # (n_users,) — 개인별 LTV 예측값
gmm = GaussianMixture(n_components=5, n_init=10, random_state=42).fit(X)memberships = gmm.predict_proba(X) # (n_users, 5) — 각 행 합 = 1
# 세그먼트별 가중 평균 LTV# memberships[:, k] 가 k번 세그먼트 멤버십 확률segment_ltv = {}for k in range(5): weights = memberships[:, k] # 멤버십 확률이 0.3 이상인 유저만 포함 (경계 유저 노이즈 감소) mask = weights >= 0.3 if mask.sum() == 0: segment_ltv[k] = 0.0 continue segment_ltv[k] = np.average(ltv_per_user[mask], weights=weights[mask])
# 결과: {0: 45200, 1: 128000, 2: 31000, 3: 89000, 4: 210000}# 세그먼트 4의 LTV가 가장 높음 → 해당 세그먼트 획득에 예산 집중print(pd.Series(segment_ltv).sort_values(ascending=False))5-3. 캠페인 평가의 보정
A/B 결과를 세그먼트별로 분석할 때 hard assignment는 경계 유저를 한 쪽에 박습니다. soft membership으로 가중 평균하면 경계의 노이즈가 줄어듭니다.
5-4. 신규 유저 cold start
GMM은 새 유저가 들어와도 각 세그먼트의 likelihood를 계산해 즉시 멤버십을 줍니다. k-means는 단순히 가장 가까운 centroid에 배정하지만 GMM은 분산까지 고려해 더 의미 있는 매칭.
6. GMM이 깨질 때 — 흔한 함정 3가지
6-1. 차원이 너무 높음
GMM은 공분산 행렬을 추정. 변수 100개면 공분산 행렬이 100×100 — 추정 불안정. 차원 축소(PCA)나 diagonal·spherical covariance로 단순화.
6-2. Gaussian 가정이 깨진다
GMM은 각 세그먼트가 Gaussian이라고 가정. 비정형 분포(skewed·multi-modal)가 같은 세그먼트 안에 있으면 잘못 분리. variational autoencoder·t-distribution mixture 같은 변형이 답.
6-3. 멤버십을 hard 결정으로 환원
GMM 결과를 받고서 argmax로 한 세그먼트만 결정해 운영하면 GMM의 가치 절반이 사라집니다. soft membership 자체를 운영에 활용해야 합니다.
7. 마케팅 실무 케이스 3개
7-1. RFM 세그먼테이션 보강
전통 RFM(Recency·Frequency·Monetary) 4×4×4 = 64개 세그먼트 대신, GMM으로 5-7 soft 세그먼트. 멤버십 확률을 캠페인 가중치에 직접 사용.
7-2. 광고 매체 풀 세그먼테이션
매체별 유저 풀의 행동 패턴이 다름. GMM으로 매체 풀별 세그먼트 추정 → 각 풀의 적합한 메시지 결정.
7-3. 신규 유저 빠른 매칭
가입 첫 7일 행동으로 GMM 멤버십 추정. 멤버십 확률에 비례한 메시지·할인 코드 자동 노출. cold start 환경의 빠른 개인화.
8. 마치며 — 세그먼테이션의 도구상자
마케터의 세그먼테이션 도구상자에는 이제 두 층이 있습니다.
- k-means — 단순, 빠름, hard assignment. 빠른 탐색·BI 보고용
- GMM·mixture model — soft membership, 분포 다룸. 운영·캠페인 타겟팅용
두 도구는 같은 자리에 경쟁하지 않습니다 — 다른 자리에 답합니다. k-means로 세그먼트를 빠르게 발견하고, GMM으로 운영에 가져가는 패턴이 운영 표준이 되어가고 있습니다.
EM 알고리즘이 학습한 soft membership을 LTV 모델과 결합하면 세그먼트별 예산 배분까지 자동화할 수 있습니다. 그 연결 고리는 BG/NBD LTV 예측과 코호트 retention 분석에서 이어집니다.
다음 글로 이어가기- BG/NBD LTV 예측 — 세그먼트별 LTV 모델 적용과 예산 배분
- 코호트 retention 분석 — 세그먼트 유지율을 시간 축으로 추적
- Survival churn 예측 — 이탈 확률을 시계열로 모델링하는 법
참고
- Bishop (2006), Pattern Recognition and Machine Learning — GMM·EM 표준 교과서
- Magidson & Vermunt (2002), Latent Class Models for Clustering — LCA 마케팅 적용
- Wedel & Kamakura (2000), Market Segmentation: Conceptual and Methodological Foundations — 산업 적용 표준
- scikit-learn — GaussianMixture — 운영 표준
- PyMC-Marketing — Customer Lifetime Value — 베이지안 mixture
- huny.log 내부 글: BG/NBD LTV, 코호트 retention, Survival churn, Stratified A/B
CRM·라이프사이클 카테고리의 다른 글
전체 보기 →-
2026·05·16
CRM 라이프사이클 메시징 설계 — onboarding·activation·retention·win-back 4단계 매트릭스
신규 가입부터 이탈 win-back까지 사용자 라이프사이클 4단계의 메시지 트리거·채널·KPI를 매트릭스로 정리합니다. 마케터·CRM 운영자가 캠페인 자동화를 처음 설계할 때 옆에 두고 보는 입문 가이드.
-
2026·05·09
Customer journey orchestration — 채널을 시간 축에서 묶는 법
같은 사용자가 광고·이메일·푸시·SMS를 받는 순서가 ROAS를 좌우합니다. customer journey orchestration이 cross-channel 시퀀싱을 자동화해 마찰을 줄이는 흐름. 도구·룰·평가 정리.
-
2026·05·07
Survival 분석으로 이탈 예측 — 마케팅 churn에 Kaplan-Meier·Cox PH
"이 유저가 떠날까"보다 "언제 떠날까"가 더 운영적인 질문입니다. Survival 분석은 시간을 명시적으로 다뤄 이탈 시점 분포를 추정하고, 변수의 영향을 hazard ratio로 보고합니다. Kaplan-Meier 곡선·Cox PH 모델로 마케팅 churn을 다루는 표준 도구.