Multiple testing 보정 — 메트릭 10개 동시에 보면 거짓 양성을 어떻게 통제하나
A/B 결과 페이지에서 메트릭을 10개 보면 적어도 1개는 우연히 p ≤ 0.05가 됩니다. 그 1개를 효과 있다고 보고하면 거짓 양성. Bonferroni·Benjamini-Hochberg(BH) 보정으로 거짓 양성률을 통제하는 두 가지 표준 도구를 마케터 시각으로.
A/B 테스트 결과 페이지에 메트릭이 매출·전환·CTR·리텐션·체류시간… 10개 정도 떠 있습니다. 한두 개가 로 표시됩니다. 운영자는 자연스럽게 “통계적으로 유의함”으로 보고합니다. 그게 함정입니다. 효과가 정말 0인 메트릭 10개를 동시에 검정하면 적어도 1개는 우연히 0.05를 깨뜨릴 확률이 약 40%입니다. 메트릭 10개를 보는 행위 자체가 5% 보증을 깨뜨립니다. 이 함정을 푸는 표준 도구 두 가지를 정리합니다.
1. 메트릭 10개 동시 검정의 거짓 양성률
A/B 테스트의 5% 거짓 양성률은 한 메트릭에 한 번만 검정한다는 가정 위에 있습니다. 메트릭 개를 동시에 검정하고 어느 하나라도 면 “유의”로 보고하는 룰을 굴리면, 적어도 한 메트릭이 우연히 0.05를 깨뜨릴 확률은 다음입니다.
, 이면 1 - 0.95^10 ≈ 0.40. 거의 절반입니다. 메트릭 20개면 0.64까지 올라갑니다.
운영적으로 이 함정의 결과는 다음입니다.
- 효과 없는 안을 효과 있는 것처럼 보고 — 잘못된 캠페인 확장
- “이번 실험은 분명 유의했는데”가 반복 — 통계 보고에 대한 신뢰 하락
- 가드레일 메트릭이 깜빡이는 신호로 알람 폭증
이 함정의 정답이 multiple testing correction입니다. 검정의 임계 를 메트릭 수에 맞춰 조정하거나, 거짓 양성의 비율(FDR)을 직접 통제합니다.
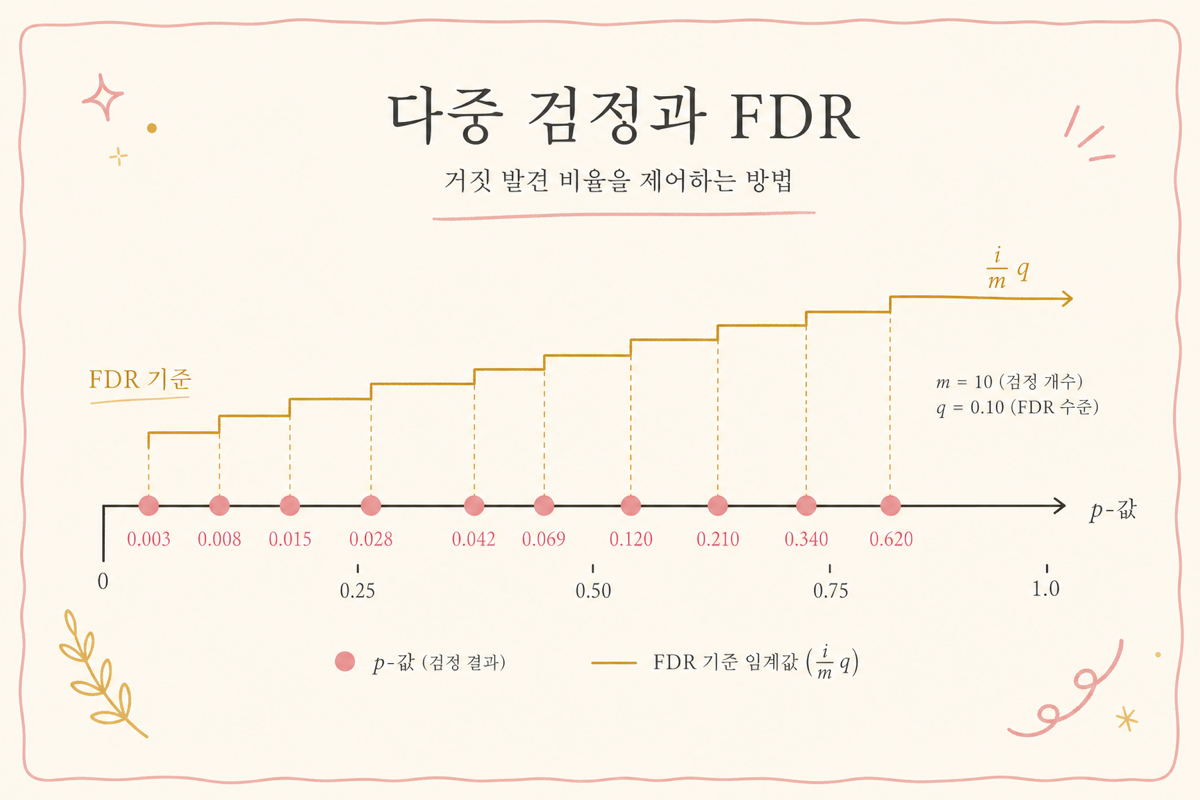
2. Bonferroni 보정 — 가장 단순, 가장 보수적
가장 단순한 보정은 Bonferroni입니다. 한 줄 규칙은 다음입니다.
메트릭 개를 동시에 검정하면, 각 메트릭의 임계를 로 낮춰라.
, 이면 각 메트릭은 여야 유의로 보고. 매우 보수적입니다. 적어도 하나라도 거짓 양성일 확률(family-wise error rate, FWER)이 5% 이하로 보증됩니다.
장단점이 명확합니다.
- 장점 — 단순, 어떤 dependency에서도 안전, 손으로 계산 가능
- 단점 — 너무 보수적, 진짜 효과가 있는 메트릭도 놓칠 수 있음
운영에서 Bonferroni가 잘 맞는 자리는 다음입니다.
- 메트릭 수가 적을 때(3~5개)
- 가드레일 메트릭처럼 거짓 양성을 절대 못 받을 자리
- 통계 검정 자체에 익숙하지 않은 의사결정자에게 보고할 때
3. Benjamini-Hochberg — 현대 표준, FDR 통제
마케팅·유전체학·ML 평가에서 표준이 되어가는 보정은 Benjamini-Hochberg(BH, 1995)입니다. FWER이 아니라 FDR(False Discovery Rate)을 통제합니다.
두 보증의 차이를 한 줄로:
- FWER — 적어도 한 거짓 양성이 일어날 확률
- FDR — 양성으로 보고된 메트릭 중 거짓 양성의 비율
마케팅 운영에서 자주 더 가치 있는 보증은 FDR입니다. “거짓 양성 한 개도 절대 안 됨”보다 “보고된 양성의 90%는 진짜다”가 운영적으로 더 의미있는 경우가 많습니다.
3-1. BH의 한 줄 규칙
메트릭 개의 p-value를 작은 순서대로 정렬하고 , 다음 조건을 만족하는 가장 큰 까지를 양성으로 보고합니다.
(FDR 10%), 이면:
- 이어야 첫 양성 보고
- 이어야 두 번째까지 보고
- 이어야 모두 양성
이 절차는 Bonferroni보다 더 많은 양성을 보고하면서도 FDR을 이하로 보증합니다. 검출력 손실이 훨씬 적습니다.
3-2. 마케터가 보는 결과
| 메트릭 | p-value | Bonferroni 보고 (α=0.05) | BH 보고 (FDR α=0.10) |
|---|---|---|---|
| 매출 | 0.002 | 유의 (≤ 0.005) | 유의 (≤ 0.010) |
| 전환율 | 0.012 | 비유의 | 유의 (≤ 0.020) |
| 객단가 | 0.025 | 비유의 | 유의 (≤ 0.030) |
| CTR | 0.044 | 비유의 | 유의 (≤ 0.040) |
| 리텐션 | 0.080 | 비유의 | 비유의 (≥ 0.050) |
같은 데이터에서 BH가 4개를 양성으로 보고하고 Bonferroni는 1개만 보고합니다. FDR 10% 보증 안에서.
from statsmodels.stats.multitest import multipletests
p_values = [0.002, 0.012, 0.025, 0.044, 0.080, 0.150, 0.230, 0.380, 0.500, 0.700]reject, p_adj, _, _ = multipletests(p_values, alpha=0.10, method='fdr_bh')print(list(zip(p_values, p_adj, reject)))이게 본문의 유일한 코드입니다. statsmodels 한 줄로 BH 보정이 끝납니다. 실험 대시보드에 이 한 줄을 추가하면 메트릭 10개 보고의 정합성이 통째로 올라갑니다.
4. 메트릭을 어떻게 묶을 것인가
multiple testing 보정의 한 가지 더 어려운 자리는 “어디까지를 한 family로 보고 보정할 것인가”입니다.
운영적으로 묶음이 너무 좁으면 보정이 약해 거짓 양성이 들어오고, 너무 넓으면 보정이 강해 진짜 효과를 놓칩니다.
자주 쓰이는 묶음 규칙은 다음입니다.
- 메트릭 family 단위 — 핵심 매출 메트릭 묶음 / 가드레일 메트릭 묶음을 따로
- 실험 단위 — 한 실험의 모든 메트릭을 한 family로
- 의사결정 단위 — “이 안을 확장할까”의 결정에 쓰이는 메트릭만 묶음
가장 흔한 운영 패턴은 다음입니다.
- 핵심 매출 메트릭 1~2개 — Bonferroni (보수적)
- 보조 메트릭 5~10개 — BH (FDR 10%)
- 가드레일 메트릭 3~5개 — Bonferroni (보수적)
세 묶음을 따로 보정하면 의사결정의 단순함을 유지하면서 통계적 정합성을 확보할 수 있습니다.
5. 마케팅 실무 케이스 3개
5-1. A/B 결과의 메트릭 다수 보고
핵심 매출은 효과 없는데 보조 메트릭(객단가·체류시간)이 두 개 유의하게 나왔습니다. BH 보정 없이 보고하면 “유의한 변화가 있었음”으로 들리지만, 실제로는 메트릭 10개 동시 검정의 거짓 양성일 가능성이 큽니다. BH 보정 후에도 두 개가 모두 유의하면 진짜 신호일 가능성이 높습니다.
5-2. 채널·세그먼트별 메트릭 비교
같은 캠페인을 채널 5개·세그먼트 3개로 분해해 메트릭 1개씩 비교하면 15번의 검정이 됩니다. 보정 없이 “Meta·신규 유저에서만 효과”로 보고하면 거짓 양성 가능성이 50%를 넘습니다. BH 보정 후 같은 결론이 유지되어야 신뢰할 수 있습니다.
5-3. 가드레일 알람의 임계 설정
가드레일 메트릭 5개를 매주 모니터링하면서 어느 하나라도 깜빡이면 알람을 보내는 운영. 보정 없이는 매주 한두 번 거짓 알람이 일어납니다. Bonferroni로 임계를 0.01로 낮추거나, BH로 FDR을 통제하면 알람의 신뢰성이 살아납니다.
6. 보정이 깨질 때 — 흔한 함정 3가지
6-1. p-value들이 강하게 상관
BH의 보증은 p-value들이 독립이거나 약한 양의 상관일 때 가장 깨끗합니다. 강한 상관(예: 매출과 매출/유저)이 있으면 보증이 다소 약해집니다. 이 경우 BH-Yekutieli 변형을 쓰는 게 안전합니다(가장 보수적).
6-2. 같은 family를 두 번 보정
실험 플랫폼이 메트릭 단위 보정을 이미 했는데 운영자가 또 보정하면 이중 보정이 됩니다. 너무 보수적이 되어 진짜 효과를 놓칩니다. 보고서를 받을 때 “이 p-value는 보정 전인가 후인가”를 첫 질문으로 두세요.
6-3. 임계 의 의미를 의사결정자와 공유 안 함
FDR 10%는 “양성 보고 중 평균 10%가 거짓”을 의미합니다. 의사결정자가 이 의미를 모르면 BH 결과를 그대로 절대 보증으로 받아들일 위험이 있습니다. 보고서 한 줄에 “FDR 10% 보정”을 적고, 그 의미를 한 번 공유하는 게 표준입니다.
7. 마치며 — 운영에 가장 단순한 한 줄 패치
multiple testing 보정은 통계적으로 깊은 자리지만, 운영 패치는 매우 단순합니다.
A/B 대시보드에 p-adjusted 컬럼 한 칸을 추가하라.
statsmodels 한 줄, 또는 R의 p.adjust(method='BH') 한 줄이면 됩니다. 이 단순한 패치로 메트릭 다수 보고의 거짓 양성이 통계적으로 통제됩니다. 운영자가 메트릭을 더 안심하고 보고, 의사결정자가 보고서를 더 신뢰합니다.
다음 글에서는 또 다른 마케팅 데이터 자리, cold start 문제를 다룹니다. 신규 유저·신규 상품·신규 캠페인의 정보가 없는 상태에서 어떻게 의사결정하느냐의 문제입니다.
참고
- Benjamini & Hochberg (1995), Controlling the false discovery rate, JRSS-B — BH 원전
- Benjamini & Yekutieli (2001), The control of the false discovery rate in multiple testing under dependency, AOS — BH-Yekutieli 변형
- Storey (2002), A direct approach to false discovery rates, JRSS-B — q-value 접근
- Romano & Wolf (2005), Stepwise multiple testing as formalized data snooping, Econometrica — 산업 적용 표준
- statsmodels — multipletests 문서 — Python 운영 적용
- huny.log 내부 글: A/B 함정 5가지, Sequential testing, CUPED
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.