Overfitting과 정규화 — 외운 모델 vs 일반화하는 모델
학습 데이터에서 99% 정확도, 새 데이터에서 60% — 가장 흔한 ML 함정 overfitting입니다. 모델이 데이터를 외운 자리. L1·L2·Dropout·Early Stopping 같은 정규화로 일반화하는 모델로 만드는 방법, 마케터·운영자가 알아야 할 핵심 직관.
“학습 데이터에서 99% 정확도! 운영에 들어갔는데 60%로 떨어졌어요.” 가장 흔한 ML 운영 사고이고 원인은 늘 같습니다 — overfitting. 모델이 학습 데이터를 외워버린 자리입니다. 정규화는 모델이 외우지 않고 일반화하도록 강제하는 도구. L1·L2·Dropout·Early Stopping 같은 도구가 어떻게 그 일을 하는지 정리합니다.
1. Overfitting의 한 줄 정의
Overfitting의 한 줄 정의:
모델이 학습 데이터의 패턴 + 노이즈까지 외워서, 새 데이터에 일반화 못 함.
학습 데이터의 손실은 0에 가깝지만, 검증·테스트 데이터에선 손실 큼. 모델이 진짜 패턴이 아니라 학습 데이터 특정 자리의 우연을 외운 결과.
운영에서 자주 보이는 패턴:
- 학습 정확도 99% / 운영 정확도 60% — 강한 overfitting
- 학습 75% / 운영 73% — 약간의 일반화 갭, 보통 OK
- 학습 65% / 운영 64% — 일반화 잘 됨
세 번째 자리가 운영 표준 목표. 학습 정확도 자체가 높을 필요 없습니다 — 운영 정확도와의 갭이 작으면 됩니다.
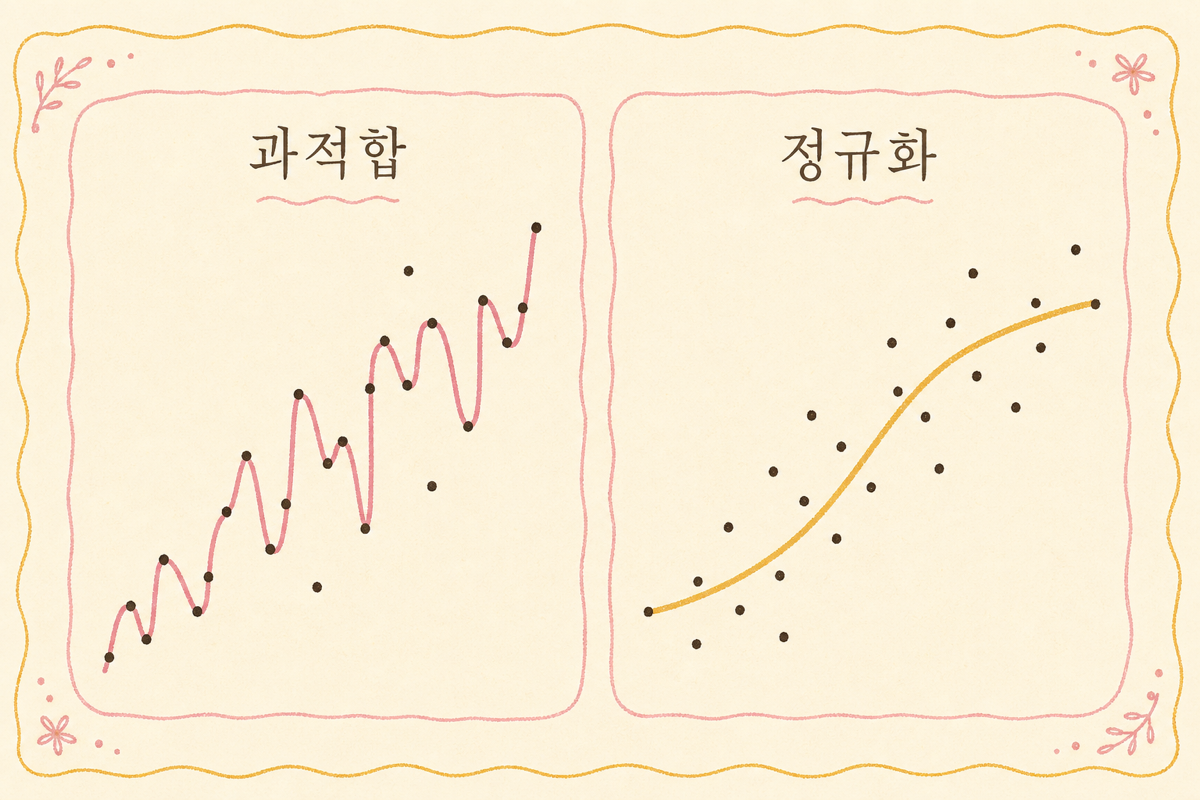
2. Overfitting이 일어나는 이유
세 가지 본질적 원인:
2-1. 모델이 너무 복잡
100개 데이터에 100차 다항식 회귀를 굴리면, 모델이 100개 점을 정확히 통과. 학습 손실 0이지만 새 데이터에 엉터리. 모델 표현력이 데이터 양에 비해 너무 큼.
2-2. 데이터가 너무 적음
같은 모델·같은 규제 수준에서 데이터가 1만 개면 잘 일반화, 1,000개면 overfitting. 학습 데이터의 우연을 외울 자리가 많아짐.
2-3. 데이터 누수
학습 데이터에 미래 정보·테스트 데이터 정보가 섞여 들어감. 학습 정확도는 매우 높지만 진짜 운영에선 의미 없음. ML 운영의 가장 무서운 함정.
3. 정규화 — 모델이 외우지 못하게 강제
정규화의 한 줄 정의:
모델이 너무 복잡해지지 못하도록 손실 함수에 페널티 추가.
기본 손실에 정규화 항 더함:
는 정규화 강도. 모델이 학습 손실을 줄이려 하지만 동시에 정규화 페널티도 줄여야 해서, 자연스럽게 단순한 모델 선호.
3-1. L2 정규화 (Ridge)
가장 흔한 정규화. 가중치 제곱합을 페널티:
큰 가중치에 큰 페널티 → 모델 가중치를 작게 유지. 모든 변수를 골고루 사용.
3-2. L1 정규화 (Lasso)
가중치 절댓값 합:
L2와 다른 성질 — 일부 가중치를 정확히 0으로 만듦. 자동 변수 선택 효과. 변수 100개 중 핵심 10개만 사용하는 모델.
3-3. Elastic Net
L1·L2 결합:
L1의 변수 선택 + L2의 안정성. 운영 표준.
3-4. Dropout (딥러닝)
학습 중 무작위로 뉴런 일부를 꺼서 모델이 특정 뉴런에 의존하지 못하게. 신경망의 표준 정규화.
3-5. Early Stopping
검증 손실이 증가하기 시작하면 학습 멈춤. 가장 간단하고 강력한 정규화. 자동으로 최적 학습 시점 찾음.
| 정규화 도구 | 모델 가족 | 운영 효과 |
|---|---|---|
| L2 (Ridge) | 회귀·분류 | 가중치 작게, 안정적 |
| L1 (Lasso) | 회귀·분류 | 자동 변수 선택 |
| Elastic Net | 회귀·분류 | L1+L2 결합 |
| Dropout | 딥러닝 | 신경망 일반화 |
| Early Stopping | 모든 모델 | 최적 학습 시점 |
| Tree depth limit | Tree 모델 | overfitting 방지 |
4. Bias-Variance Trade-off — 정규화의 본질
정규화가 푸는 더 깊은 자리 — bias-variance trade-off.
- Bias (편향) — 모델이 단순해서 진짜 패턴 못 잡음 (underfitting)
- Variance (분산) — 모델이 복잡해서 데이터마다 다른 답 (overfitting)
좋은 모델은 두 사이의 균형. 정규화 강도 가 그 균형 조절.
- — 정규화 없음. variance 큼 (overfitting)
- 매우 큼 — 모델이 너무 단순. bias 큼 (underfitting)
- 중간 — 균형
from sklearn.linear_model import Ridge, Lassofrom sklearn.model_selection import cross_val_score
# L2 정규화 — alpha가 lambdaridge = Ridge(alpha=1.0)scores = cross_val_score(ridge, X, y, cv=5, scoring='neg_mean_squared_error')
# L1 정규화 — 변수 선택 효과lasso = Lasso(alpha=0.1)lasso.fit(X, y)print('Selected features:', sum(lasso.coef_ != 0))이게 본문에 박는 유일한 코드입니다. sklearn의 정규화 모델 두 줄. cross-validation으로 결정이 운영 표준 흐름.
5. Overfitting의 진단 — 운영 점검 5가지
5-1. Train·Validation 손실 곡선
가장 단순. 같은 그래프에 둘 다 그림.
- 둘 다 줄고 평행 — 좋은 학습
- Train 줄지만 Val 증가 — overfitting
- 둘 다 안 줄음 — underfitting
5-2. 학습·운영 정확도 갭
학습 75% / 운영 50%면 큰 overfitting. 갭 5%p 이내가 운영 목표.
5-3. Cross-validation 분산
CV 5번 결과의 표준편차가 크면 데이터에 모델이 흔들림. 정규화 강화 필요.
5-4. 변수 중요도의 안정성
같은 모델을 다른 데이터 분할로 학습할 때 변수 중요도가 매번 흔들리면 overfitting. 안정적 핵심 변수가 떠오르는 게 잘 일반화된 모델.
5-5. 운영 시간에 따른 성능 저하
학습 후 첫 주는 좋다가 점차 떨어지면 — 데이터 drift + overfitting의 결합. 임베딩 운영 글의 drift 모니터링 표준 적용.
6. 마케팅 운영 자리에서의 함정
6-1. LTV 모델 overfitting
가입자 수천 명에 변수 50개 모델 학습 → 학습 정확도 매우 높지만 새 가입자에 흔들림. 변수 줄이거나 L1 정규화로 자동 선택.
6-2. CTR 예측 모델
피처 엔지니어링으로 1,000개 변수 만들면 overfitting 위험. L1 + cross-validation으로 핵심 변수 100개 자동 선택.
6-3. 광고 카피 분류기
학습 데이터의 작은 풀에 overfitting → 새 카피 톤에 일반화 못 함. fine-tuning에 dropout + early stopping 결합.
6-4. 시계열 모델의 데이터 누수
미래 데이터로 과거 예측하면 사실상 데이터 누수. 운영 정확도가 학습보다 매우 떨어짐. 시계열 cross-validation(time-series split)으로 검증.
7. 정규화에 익숙해지면 다음 글들
- 평가 지표 도구상자 — 평가 시점의 정규화 효과 측정
- Cross-validation — 진짜 일반화 능력 평가
- Conformal Prediction — 모델 위에 보증 구간
- BG/NBD LTV — 도메인 모델의 정규화 의미
8. 마치며 — 외우지 않는 모델
머신러닝의 핵심 도전은 학습 데이터에서 잘 하는 게 아니라 새 데이터에 일반화입니다. 정규화는 그 도전의 표준 도구.
학습 정확도가 운영 목표 아니다. 학습·운영 정확도의 갭이 작은 모델이 좋은 모델.
이 한 줄을 잡고 있으면 운영 ML 모델의 평가·유지보수가 단단해집니다.
다음 글에서는 같은 자리의 또 다른 기초 — 평가 지표 도구상자를 다룹니다. 어떤 자리에 어떤 지표를 쓸지의 운영 가이드.
참고
- Tibshirani (1996), Regression Shrinkage and Selection via the Lasso, JRSS-B — Lasso 원전
- Hoerl & Kennard (1970), Ridge Regression — L2 정규화 원전
- Srivastava et al. (2014), Dropout: A Simple Way to Prevent Neural Networks from Overfitting, JMLR — Dropout 원전
- Hastie, Tibshirani & Friedman (2009), The Elements of Statistical Learning — 정규화 종합
- scikit-learn — Linear Models 문서 — 운영 표준
- huny.log 내부 글: 회귀와 분류, 손실 함수와 학습, Cross-validation(다음 글), Conformal Prediction
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.