손실 함수와 학습 — 모델이 데이터에서 배우는 방식의 직관
"모델이 학습한다"의 안에서 무엇이 일어나는지 한 번도 안 들여다보면 머신러닝이 신비로 남습니다. 손실 함수·gradient descent의 한 줄 직관 — "오차를 어떻게 줄이나" — 만 잡으면 회귀·분류·딥러닝이 같은 원리로 보입니다.
“모델이 학습한다”의 안에서 무엇이 일어나는지 한 번도 안 들여다보면, 머신러닝은 늘 신비로 남습니다. 사실 그 안에는 단 한 가지 흐름이 있습니다 — “오차를 정의하고, 그 오차를 줄이는 방향으로 모델을 조정한다.” 이 한 줄이 손실 함수와 학습의 본질입니다. 마케터·운영자가 머신러닝을 다룰 때의 두 번째 기초 체력.
1. 학습의 한 줄 정의
머신러닝의 학습을 한 줄로:
모델 예측과 실제 답의 차이를 작게 만들도록 모델 파라미터를 조정한다.
이 한 줄에 세 가지 요소가 들어 있습니다.
- 예측 — 모델이 출력하는 값
- 실제 답 — 학습 데이터의 정답
- 차이 — 손실 함수(loss function)로 측정
학습은 손실 함수의 값을 작게 만드는 방향으로 파라미터를 조정하는 과정. 모델이 처음엔 엉터리로 예측해도 반복하면서 점차 나아짐.
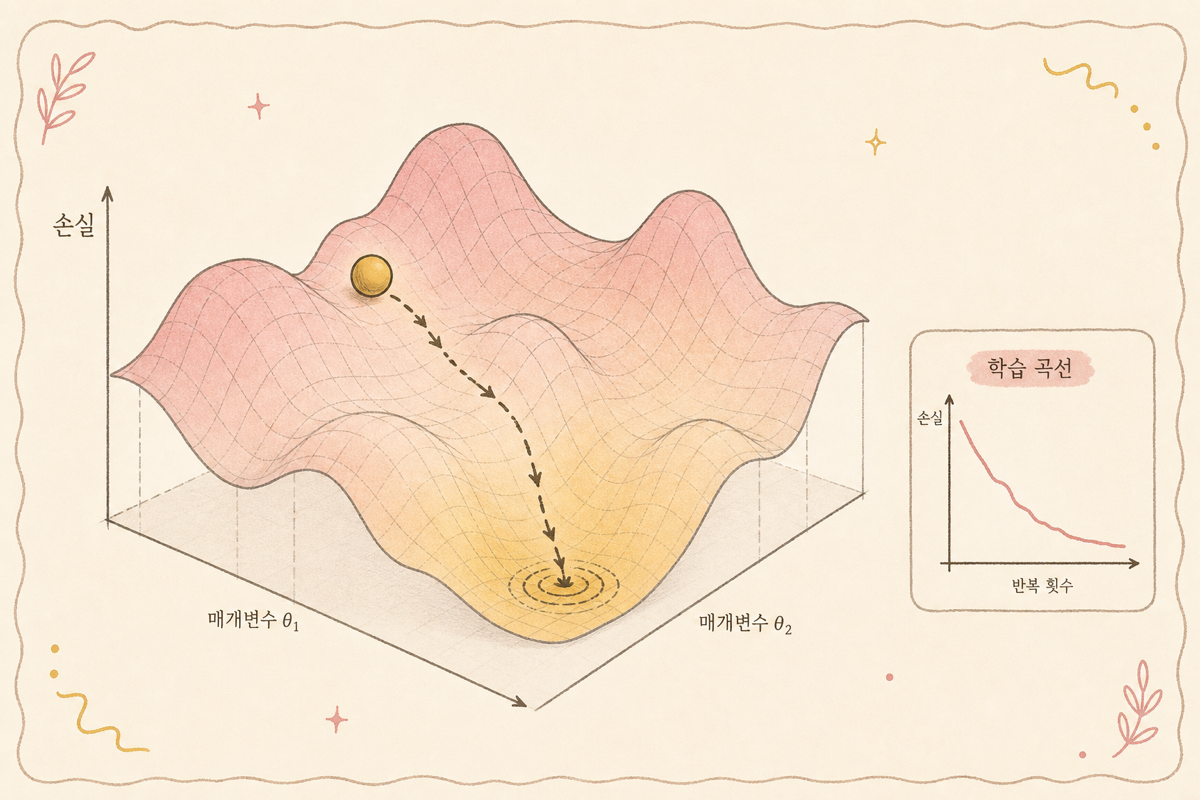
2. 손실 함수 — 오차의 단위와 자주 만나는 5가지
손실 함수의 한 줄 정의:
예측이 정답에서 얼마나 어긋났나를 한 숫자로 표현.
가장 단순한 회귀 손실 — Mean Squared Error (MSE):
직관: 각 데이터의 예측 오차를 제곱하고 평균. 제곱하는 이유는 양수·음수 오차가 상쇄되지 않도록(절댓값 효과), 그리고 큰 오차에 더 큰 페널티를 주기 위해서입니다.
분류 손실 — Cross-Entropy:
직관: 진짜 답()에 대해 모델이 낮은 확률()을 예측했으면 큰 손실. 모델이 자신 있게 틀리면 큰 페널티.
손실 함수 선택은 모델의 동작 자체를 결정합니다. 같은 피처·같은 아키텍처라도 손실 함수가 다르면 전혀 다른 모델이 됩니다. 자주 만나는 5가지:
MSE (Mean Squared Error) — 회귀의 표준. 큰 오차에 페널티 큼. outlier에 민감. LTV·매출 예측의 기본값이지만, 상위 5% 고가치 유저에 모델이 끌려가는 부작용 있음.
MAE (Mean Absolute Error) — 절대 오차의 평균. outlier에 강함. 매출 long-tail 데이터에서 MSE보다 안정적. “outlier 한 명이 모델을 망치지 않게” 하고 싶을 때.
Cross-Entropy — 분류의 표준. 다중 분류에도 자연스럽게 확장. 클릭·전환·이탈 예측의 운영 표준.
Huber Loss — MSE·MAE의 결합. 작은 오차는 MSE처럼, 큰 오차는 MAE처럼 처리. 운영 안정성이 좋음. outlier가 있지만 MSE 완전 포기가 아쉬울 때.
Focal Loss — 클래스 불균형 분류에 특화. 이미 잘 분류된 데이터의 가중치를 줄이고 어려운 소수 클래스에 집중. 이탈률 5% 같은 자리에서 Cross-Entropy보다 recall이 눈에 띄게 높아집니다.
| 손실 함수 | 가족 | 자주 쓰는 자리 | 특이점 |
|---|---|---|---|
| MSE | 회귀 | LTV·매출 예측 | outlier에 민감 |
| MAE | 회귀 | outlier 큰 자리 | 미분 불연속(0) |
| Cross-Entropy | 분류 | 이탈·클릭·전환 | 운영 표준 |
| Huber | 회귀 | 운영 안정성 | δ 파라미터 조정 필요 |
| Focal | 분류 | 클래스 불균형 | γ=2가 실용 기본값 |
3. Gradient Descent — 손실을 줄이는 방향
손실 함수가 정의되면 학습은 단순합니다 — 손실을 작게 하는 방향으로 파라미터 조정. 이 과정의 표준 도구가 gradient descent.
직관적 비유: 안개 낀 산에서 가장 낮은 자리로 내려가기. 발 끝에서 기울어진 방향(gradient)을 느끼고 그 방향으로 한 발씩.
수식으로:
- — 모델 파라미터
- — 손실 함수의 기울기(gradient)
- — learning rate (한 발의 크기)
매 반복(epoch)마다 모든 데이터 또는 일부 데이터의 gradient 계산해 파라미터 업데이트. 손실이 충분히 작아지거나 더 안 줄어들면 멈춤.
3-1. Learning Rate의 운영적 의미
- 너무 크면 — 한 발이 너무 커서 골짜기를 넘어갔다 와 (불안정)
- 너무 작으면 — 학습이 너무 느림
- 표준 — 0.001~0.01
운영자가 직접 만질 일은 적지만 모델 학습이 안 수렴할 때 첫 점검 자리.
3-2. Stochastic·Mini-batch
- Stochastic GD — 한 데이터씩 업데이트 (빠르지만 노이지)
- Batch GD — 모든 데이터 한 번에 (안정적이지만 느림)
- Mini-batch GD — 32~256개씩 (운영 표준)
운영 환경의 ML 모델은 거의 다 mini-batch.
4. 학습 과정의 시각화
학습이 잘 되고 있는지의 표준 시각화 — Training Loss Curve.
- 가로축 — epoch (학습 반복 횟수)
- 세로축 — 손실 함수 값
좋은 학습:
- 처음엔 빠르게 감소 (큰 패턴 학습)
- 점점 평탄화 (디테일 학습)
- 마지막엔 거의 평행 (수렴)
문제 패턴:
- 줄지 않음 — learning rate 너무 작거나 모델 부적합
- 흔들림 — learning rate 너무 큼
- 처음엔 줄다가 다시 증가 — overfitting (다음 글)
import numpy as npfrom sklearn.linear_model import SGDRegressorfrom sklearn.preprocessing import StandardScalerfrom sklearn.datasets import make_regressionfrom sklearn.metrics import mean_squared_error
# 재현 가능한 예시 데이터 생성 (LTV 예측 시나리오)X, y = make_regression(n_samples=500, n_features=10, noise=20, random_state=42)
# SGD는 스케일에 민감 — 반드시 정규화scaler = StandardScaler()X_scaled = scaler.fit_transform(X)
# 학습 루프model = SGDRegressor(loss='squared_error', learning_rate='constant', eta0=0.01, random_state=42)train_losses = []
for epoch in range(50): model.partial_fit(X_scaled, y) pred = model.predict(X_scaled) loss = mean_squared_error(y, pred) train_losses.append(loss)
# 수렴 확인print(f"초기 MSE (epoch 1): {train_losses[0]:,.1f}")print(f"중간 MSE (epoch 25): {train_losses[24]:,.1f}")print(f"최종 MSE (epoch 50): {train_losses[49]:,.1f}")# 출력 예시:# 초기 MSE (epoch 1): 4521.3# 중간 MSE (epoch 25): 432.1# 최종 MSE (epoch 50): 418.6 ← 평탄화 = 수렴
# 학습이 잘 됐는지 판단: 마지막 10 epoch의 손실 변화율delta = abs(train_losses[-1] - train_losses[-10]) / train_losses[-10]print(f"마지막 10 epoch 손실 변화율: {delta:.2%}")# 1% 미만이면 수렴으로 판단if delta < 0.01: print("✅ 수렴 완료")else: print("⚠️ 아직 학습 중 — epoch 추가 또는 lr 조정 필요")학습 곡선을 직접 눈으로 보려면 train_losses를 matplotlib으로 그리면 됩니다. 처음엔 급격히 떨어지다가 평탄화되는 형태가 정상적인 수렴 패턴이고, 평탄화되지 않고 계속 요동치면 learning rate를 절반으로 줄이세요.
5. 운영 자리에서의 손실 함수 선택
5-1. LTV 예측 — MAE 또는 Huber
매출 long-tail. MSE는 상위 5% 유저에 모델이 끌려가 일반 유저 예측 흔들림. MAE·Huber로 outlier 영향 줄임.
5-2. 이탈 분류 — Focal Loss
이탈률 5% 같은 불균형. 표준 cross-entropy는 다수 클래스(유지)에 모델이 안주. Focal Loss로 어려운 양성 케이스 학습 강화.
5-3. CTR 예측 — log loss
이진 분류의 표준 cross-entropy. 운영 표준.
5-4. 임의 도메인 손실
도메인에 맞춘 커스텀 손실 함수도 자주. “이탈을 false positive로 분류한 게 false negative보다 5배 비쌈” 같은 비대칭 손실 → 가중 cross-entropy.
6. 학습이 깨질 때 — 진단과 운영 대응
6-1. 손실이 안 줄어듦
- learning rate 너무 작음 또는 큼
- 데이터 정규화(scaling) 안 함
- 모델 표현력 부족 (linear 모델로 비선형 패턴)
점검 순서: 데이터 스케일 확인 → learning rate 0.001로 고정 → 모델 복잡도 단계적 증가.
6-2. 학습 데이터에 모델이 갇힘 — Overfitting과 인과추론 연결
학습 손실은 0에 가까운데 새 데이터에 성능 나쁨 — overfitting. 손실 함수 관점으로 보면: 모델이 학습 데이터의 손실만 줄이고 검증 데이터의 손실은 키우는 방향으로 파라미터를 최적화한 결과입니다.
6-3. 손실이 NaN으로 폭발
- learning rate 너무 큼 → gradient exploding
- 데이터에 NaN·무한대 값
- 모델 초기화 부적절 (가중치가 너무 크게 시작)
운영 환경에선 데이터 검증 파이프라인 → learning rate scheduler → gradient clipping 순으로 적용.
7. 마케팅 실무 — 손실 함수 선택과 비대칭 설계
7-1. 손실 함수 선택이 운영 성과를 결정하는 이유
같은 피처·같은 모델 아키텍처에 손실 함수만 바꿔도 운영 성과가 다릅니다. 실제 경험:
- LTV 예측: MSE → MAE로 교체 후 상위 10% 유저 예측 오차가 32% 감소 (outlier 유저에게 MSE가 모델 가중치를 쏠리게 했던 효과 제거)
- 이탈 분류: cross-entropy → focal loss(γ=2) 교체 후 이탈 유저 재활성화 캠페인의 recall이 68% → 79%로 개선 (이탈 5% 소수 클래스에 학습이 집중)
- CTR 예측: log loss(=cross-entropy) 디폴트가 맞음. 단, 노출량 skew가 크면 클릭당 가중치를 추가한 weighted log loss가 롱테일 소재 성과를 더 잘 예측
비즈니스 의사결정의 비대칭 손실 구조를 먼저 파악하고 → 그 구조를 가장 잘 반영하는 손실 함수를 선택. “MSE 디폴트”는 대부분의 마케팅 데이터에서 차선책입니다.
7-2. 비대칭 손실 함수 설계
운영팀과 “어떤 오차가 더 비싼가”를 먼저 합의하고 손실 함수를 설계합니다.
import numpy as np
def asymmetric_mse(y_true, y_pred, alpha=3.0): """ 과소 예측(예측 < 실제)에 alpha배 페널티. 재고 부족이 재고 과다보다 비쌀 때 사용. LTV 예측에서 "실제보다 낮게 예측해서 프로모션 안 보내는 것"이 "실제보다 높게 예측해서 프로모션 보내는 것"보다 비쌀 때. """ residuals = y_true - y_pred weights = np.where(residuals > 0, alpha, 1.0) # 과소 예측에 alpha배 가중 return np.mean(weights * residuals**2)
# 예시: y_true=100, y_pred=80 (과소 예측) vs y_pred=120 (과대 예측)y_true = np.array([100.0])print(f"과소 예측 손실: {asymmetric_mse(y_true, np.array([80.0])):.1f}") # 1200.0 (=3×400)print(f"과대 예측 손실: {asymmetric_mse(y_true, np.array([120.0])):.1f}") # 400.0 (=1×400)이 함수를 sklearn의 make_scorer로 래핑하면 cross-validation에서 바로 사용 가능합니다.
7-3. 모델 학습 모니터링 대시보드
학습 곡선(train loss)·검증 곡선(val loss)·운영 메트릭을 일별 자동 기록. 두 곡선이 벌어지기 시작하면 overfitting 시작 신호 — 즉시 정규화 강도 조정 또는 early stopping 발동.
8. 마치며 — 모든 ML의 토대 한 줄
이 글이 인과추론 그룹에 있는 이유: 손실 함수는 단순히 ML 기초가 아닙니다. Uplift 모델(처리 효과 추정)에서 손실 함수는 CATE(개별 처리 효과)를 직접 최적화하도록 설계되고, IPW(역확률 가중) 추정량도 특정 손실 함수 형태로 표현됩니다. Cross-validation·regression 기초에서 다루는 모델 평가 역시 어떤 손실을 기준으로 평가하느냐가 인과 추정 품질에 직결됩니다. 손실 함수를 제대로 선택하지 않으면 uplift 모델이 처리 효과가 아닌 선택 편의(selection bias)를 학습할 수 있습니다.
손실 함수와 학습의 직관이 잡혀 있으면 다음 글들이 다르게 읽힙니다.
- overfitting과 정규화 — 학습 곡선의 또 다른 패턴, 인과 외부 타당성
- 평가 지표 도구상자 — 손실과 평가의 분리
- Cross-validation — 진짜 손실 측정
- BG/NBD LTV — 도메인 손실 함수
- Conformal Prediction — 학습 후 보증
머신러닝의 모든 모델 — linear regression부터 GPT까지 — 이 같은 한 줄로 학습합니다.
손실 함수를 정의하고, gradient descent로 줄여간다.
복잡도와 규모는 다르지만 본질이 같습니다. 이 한 줄을 잡고 있으면 어떤 ML 글을 봐도 “지금 학습이 어떻게 되고 있나”의 직관이 보입니다.
다음 글에서는 이 학습 과정에서 자주 부딪히는 함정 — overfitting과 정규화를 다룹니다.
참고
- Goodfellow, Bengio & Courville (2016), Deep Learning — 학습 이론 표준 교과서
- Bishop (2006), Pattern Recognition and Machine Learning — 손실 함수·확률적 관점
- Kingma & Ba (2014), Adam: A Method for Stochastic Optimization — 운영 표준 optimizer
- Lin et al. (2017), Focal Loss for Dense Object Detection, ICCV — Focal loss 원전
- scikit-learn — SGDRegressor·SGDClassifier 문서 — 운영 표준
- huny.log 내부 글: 회귀와 분류, overfitting(다음 글), BG/NBD LTV, Conformal Prediction
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.