Geo·시간 혼합 인과추론 — Synthetic DiD로 채널 incrementality 보정
DiD는 시간축, Geo-lift는 공간축. 둘 다 단축이라 가정이 종종 무너집니다. Synthetic DiD는 두 축을 한 추정량으로 묶어 평행 추세 가정의 부담을 덜어줍니다. TV+디지털 동시 변경 같은 다중 처리에서도 채널 incrementality를 안정적으로 잡는 도구.
“지난달 TV 광고 + 디지털 비주얼을 동시에 바꿨는데, 매출이 12% 올랐어요. TV 효과인가요, 디지털 효과인가요?” 이 질문은 시간축만 보는 DiD나 공간축만 보는 Geo-lift 어느 한 도구로도 깔끔히 답하지 못합니다. Synthetic DiD는 두 축을 한 추정량으로 묶어, 단축 인과추론이 흔들리는 자리에서 안정적인 보정을 만들어 줍니다. 이 시리즈의 마지막 글, 인과추론의 마무리 퍼즐을 맞춥니다.
1. 단축 인과추론의 한계 — 두 도구가 부딪히는 자리
이 시리즈 1편에서 다룬 Diff-in-Diff는 시간축에서 작동합니다. 처리군과 대조군의 사전·사후 차이의 차이를 봅니다. 그런데 평행 추세 가정이 종종 깨지고, staggered 처리에서는 추정 자체가 흔들립니다.
Geo-lift는 공간축에서 작동합니다. 광고를 켠 도시와 끈 도시(또는 합성 대조)를 비교합니다. 그런데 단일 시점 비교만 하면 시간 추세를 떼어내지 못하고, 처리 도시가 적으면 합성 대조의 신뢰성이 흔들립니다.
두 도구가 같이 흔들리는 가장 흔한 자리는 다음과 같습니다.
- TV·OOH·디지털을 동시에 바꿨을 때 — 어느 채널 효과인지 분리되지 않음
- 처리 시점·처리 도시가 둘 다 적을 때 — DiD는 평행 추세, Geo-lift는 합성 대조 모두 흔들림
- 사전 추세에 장기 트렌드와 시즌이 같이 들어 있을 때 — 시간 추세만으로 못 떼어냄
Synthetic DiD는 이 두 도구의 가정 부담을 덜어주는 결합 추정량입니다. Arkhangelsky·Athey·Hirshberg·Imbens·Wager(2021)가 정리했고, 마케팅에서는 채널 incrementality 보정의 표준이 되어가고 있습니다.
2. 두 축을 동시에 보는 이유
DiD를 다시 한번 식으로 적으면 다음과 같습니다.
이 식 안에서 모든 시점은 똑같이 1/T의 가중치를 가지고, 모든 대조 도시는 똑같이 1/N의 가중치를 가집니다. 모든 시점·모든 대조군이 동등하게 취급된다는 가정입니다.
Synthetic Control은 공간축 가중치를 학습합니다 — 처리 도시와 사전 추세가 비슷한 대조 도시에 더 큰 가중치를 줍니다. 시간축 가중치는 여전히 1/T입니다.
Synthetic DiD는 양쪽 축을 모두 학습합니다.
복잡해 보이지만 의미는 단순합니다. 는 공간축 가중치(어느 대조 도시가 처리 도시를 잘 닮았나), 는 시간축 가중치(어느 사전 시점이 처리 시점과 비슷한 추세를 가졌나). 두 가중치가 곱해져 잔차의 가중합을 최소화하는 효과 추정치 를 푼 것입니다.
| 추정량 | 시간축 가중치 | 공간축 가중치 | 가정 부담 |
|---|---|---|---|
| DiD | 균등 (1/T) | 균등 (1/N) | 평행 추세 |
| Synthetic Control | 균등 | 학습 (사전 적합) | 합성 가능 |
| Synthetic DiD | 학습 | 학습 | 둘 다 부담이 작음 |
직관적으로 — DiD가 깐 평행 추세가 살짝 흔들려도 시간축 가중치가 그 영향을 덜어주고, Synthetic Control이 깐 합성 가능성이 살짝 흔들려도 시간축의 차분 구조가 받쳐줍니다. 두 가정이 동시에 크게 무너지지만 않으면, 결합 추정량이 단축 추정량보다 안정적입니다.
3. 직관 — “두 축에서 가까운 데이터를 더 본다”
수식을 잠깐 내려놓고 직관으로 보면 Synthetic DiD가 하는 일은 단순합니다.
처리 도시와 비슷한 대조 도시를 골라(공간 가중치), 처리 시점과 비슷한 사전 시점을 골라(시간 가중치), 그 묶음 위에서 DiD를 다시 푼다.
예시로 생각해봅시다. 서울에서 새 캠페인을 켰을 때 대조군 후보가 부산·대구·대전·광주 4개 도시라고 합시다.
- DiD라면 4개 도시 평균을 그대로 대조
- Synthetic Control이라면 사전 추세가 서울과 가장 비슷한 도시 조합(예: 부산 0.4 + 대전 0.3 + 광주 0.3)으로 합성
- Synthetic DiD는 같은 공간 합성을 하면서, 사전 시점들도 서울 처리 시점과 비슷한 시점에 가중치를 더 줘서 차분 구조 위에 다시 풀어냄
운영 관점에서 차이는 다음과 같이 나타납니다.
- 사전 추세가 평행이 아닐 때 — DiD는 흔들림, Synthetic DiD는 시간 가중치가 보정
- 처리 도시와 비슷한 대조가 거의 없을 때 — Synthetic Control은 흔들림, Synthetic DiD는 차분 구조가 받쳐줌
- 처리 시점에 외부 충격이 있었을 때 — 단축 추정량은 충격을 효과로 오인, Synthetic DiD는 시간 가중치가 그 시점을 작게 만들 수 있음
4. 코드 한 묶음 — synthdid 한 줄로 시작
Synthetic DiD는 다행히 R 패키지 synthdid(Athey 그룹), Python 패키지 pysdid로 그대로 돌아갑니다. 마케터가 알아야 할 코드는 한 줄로 충분합니다.
from pysdid import sdid
# panel: ['unit', 'time', 'y', 'treated'] 컬럼 패널 데이터result = sdid(panel, unit='unit', time='time', outcome='y', treatment='treated')print(result.tau, result.se, result.ci_95)이게 본문에 박는 유일한 코드입니다. 패널 데이터(유닛 × 시점 매트릭스 + 처리 표시)를 던지면 점추정 , 표준오차, 95% 신뢰구간을 한 번에 줍니다. 무거운 가중치 학습은 패키지 내부에서 처리됩니다.
운영적으로 챙길 한 가지 — placebo 검정입니다. 처리 도시 대신 대조 도시 한 개를 가짜 처리로 두고 같은 추정을 돌렸을 때 효과가 0 근처로 나와야 신뢰할 수 있습니다. synthdid는 placebo 그래프를 자동으로 그려주는 함수가 있으니, 보고서에 같이 첨부하는 게 표준입니다.
5. 마케팅 실무 케이스 3개
5-1. TV + 디지털 동시 변경 — 채널별 기여 분리
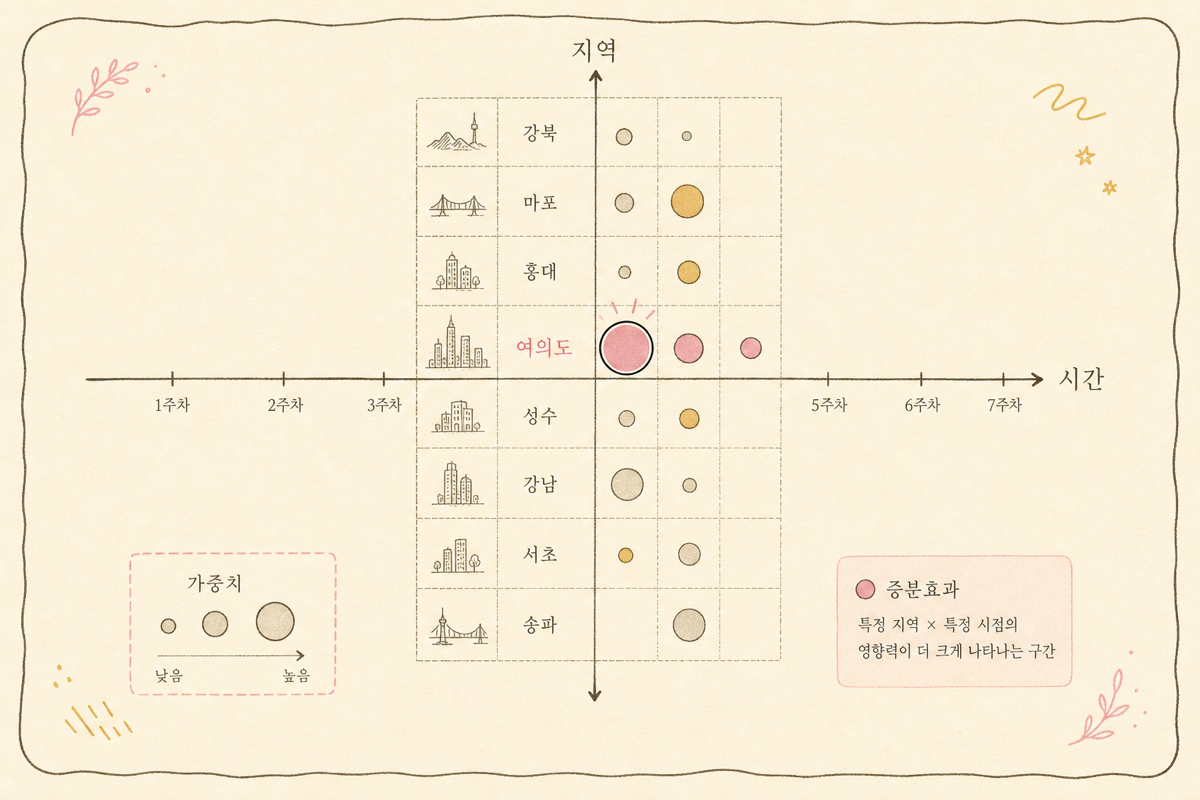
가장 어려운 자리입니다. TV 광고와 디지털 비주얼을 같은 주에 동시에 바꿨고, 매출이 올랐습니다. 단순 DiD나 Geo-lift로는 두 채널 효과가 뒤섞입니다.
운영 패턴은 다음과 같이 짭니다.
- TV 광고는 도시별로 도달이 다름 — 공간 가중치 학습에서 자연스럽게 나뉨
- 디지털은 일별 노출이 들쑥날쑥 — 시간 가중치 학습이 안정화 도움
- 두 채널이 동시에 변동되었으면, 처리 행렬 를 두 컬럼으로 두고 두 효과 를 동시에 추정 (multi-treatment Synthetic DiD)
이 분해는 단순하지 않지만, 두 채널이 도시별·시간별로 노출이 다른 만큼 분리 가능성이 생깁니다. 두 채널이 정확히 같은 도시·같은 시점에만 켜졌다면 어떤 도구로도 분리할 수 없습니다.
5-2. Staggered 캠페인 롤아웃 — 도시·시점별 다른 시작
대형 광고주가 도시별로 1주 간격으로 캠페인을 점진 롤아웃하는 경우입니다. 1편에서 다룬 TWFE 한계가 정확히 발생하는 자리입니다.
- 도시 A는 t=0에 시작, 도시 B는 t=1, 도시 C는 t=2…
- TWFE는 이질적 효과를 잘못 가중하지만 — Synthetic DiD는 도시별·시점별 가중치를 따로 학습해 staggered 편향을 줄여줌
- 각 도시별 를 추정하고 그 평균을 보고하는 패턴이 가장 자연스러움
5-3. 단일 도시 대형 캠페인 — 합성 대조에 의존
서울에서만 대형 OOH 캠페인을 했고, 다른 도시는 전혀 안 했습니다. 처리 도시가 1개라 DiD는 사실상 불가능합니다.
- Synthetic Control이 1순위, Synthetic DiD가 2순위
- Synthetic Control이 사전 추세가 깨끗하면 충분하지만 — 캠페인 시점에 매크로 충격이 있었으면 흔들림
- Synthetic DiD는 시간 가중치가 그 충격 시점을 자동으로 작게 만들어 보험 역할
6. Synthetic DiD가 깨질 때 — 흔한 함정 3가지
6-1. 처리·대조군의 사전 기간이 너무 짧다
시간 가중치 학습은 사전 기간에 정보를 모읍니다. 사전 4주만 있고 사후 8주를 본다면 시간 가중치가 거의 균등이 되어 DiD에 가까워집니다. 사전 8~12주 이상은 확보하는 게 표준입니다.
6-2. 대조 후보 풀이 너무 작다
공간 가중치 학습은 대조 후보 도시 풀에서 가짜 대조군을 합성합니다. 후보가 5개 미만이면 합성이 거의 평균이 되어 Synthetic Control 효과가 사라집니다. 도시 단위라면 최소 10~15개 후보를 확보하세요. 코호트 단위라면 더 많이.
6-3. 처리 자체가 대조 후보에 영향을 미친다(spillover)
서울에서 캠페인을 했는데 인접 도시 광고 단가나 매체 노출에 spillover가 일어나면, 대조 도시까지 효과를 일부 받습니다. 이 경우 Synthetic DiD는 효과를 과소 추정합니다. 인접 도시를 대조 풀에서 빼는 등의 사전 정리가 필요합니다.
7. 시리즈 5편을 묶는 한 줄 — 인과추론·예측·식별이 같이 가는 시대
이번 시리즈를 통해 5편의 글로 마케팅 의사결정의 도구 지형을 다시 그렸습니다.
- 1편 DiD — 시간축에서 효과를 분리
- 2편 Conformal Prediction — 점추정에 분포 가정 없이 보증
- 3편 BG/NBD — 비계약 고객 LTV의 운영 모델
- 4편 Privacy Sandbox — 식별 환경의 새 좌표
- 5편 Synthetic DiD — 인과추론의 결합 보정
5편이 각자의 자리를 가지면서도 한 운영 흐름으로 묶입니다.
- 식별은 4편의 좌표 위에서 — 1st party + Privacy Sandbox + CDP의 결합
- 예측은 3편의 LTV 모델로 — 점추정 + 2편의 Conformal 보증
- 효과 검증은 1편 + 5편으로 — DiD·Geo-lift·Synthetic DiD의 적절한 선택
8. 마치며 — 마케터의 인과추론 도구상자
5편을 다 읽고 났을 때 마케터의 손에 남는 것은 정교한 수식이 아니라 도구 선택의 감각입니다.
- A/B 가능 → A/B
- A/B 불가능, 사전 추세 깨끗 → DiD
- 단일 처리 도시, 합성 대조 가능 → Synthetic Control
- 사전 추세도 흔들리고 합성도 흔들림 → Synthetic DiD
- 점추정 위에 보증이 필요 → Conformal Prediction
- 데이터가 너무 적음 → 베이지안 (huny.log의 퍼널 베이지안·CAC/LTV 베이지안 글)
도구는 의사결정의 신뢰성을 높이기 위한 수단이지 그 자체가 목적이 아닙니다. 같은 보고서에 두 도구의 추정치가 함께 있고 그 차이가 어디서 오는지 마케터가 설명할 수 있다면, 어떤 도구를 썼는지보다 의사결정의 질이 훨씬 단단해집니다.
참고
- Arkhangelsky, Athey, Hirshberg, Imbens & Wager (2021), Synthetic Difference-in-Differences, AER — Synthetic DiD 원전
- synthdid (R 패키지, Athey 그룹) — placebo 그래프 자동 생성 포함
- pysdid (Python 포팅) — sklearn 호환 인터페이스
- Abadie (2021), Using Synthetic Controls: Feasibility, Data Requirements, and Methodological Aspects — Synthetic Control 종합 리뷰
- Athey & Imbens (2017), The State of Applied Econometrics — Causality and Policy Evaluation — 마케팅 인과추론의 큰 그림
- huny.log 시리즈 글: DiD, Conformal Prediction, BG/NBD LTV, Privacy Sandbox, Geo-lift
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.