회귀와 분류 — 마케터가 가장 자주 만나는 두 머신러닝 모델 가족
"이 유저의 LTV는 얼마?" "이 유저가 이탈할까?" 두 질문이 머신러닝의 두 가족 — 회귀와 분류 — 의 출발점입니다. 무엇이 다르고 어디 쓰는지·어떻게 평가하는지를 한 글로 정리. ML 기초 체력의 첫 자리.
“이 유저의 LTV는 얼마?” “이 유저가 이탈할까?” 마케팅 자리의 두 질문은 머신러닝의 두 모델 가족 — 회귀(regression)와 분류(classification) — 의 출발점입니다. 둘이 무엇이 다른지·어디 쓰는지·어떻게 평가하는지를 한 글로 정리합니다. 머신러닝 기초 체력의 첫 자리이자 시리즈 1·2·3 글들의 토대.
1. 두 가족의 한 줄 정의
머신러닝의 supervised learning(지도 학습)은 두 가족으로 나뉩니다.
- 회귀 (regression) — 연속된 숫자 예측 (LTV 12만원·CTR 0.034·매출 850만원)
- 분류 (classification) — 카테고리·라벨 예측 (이탈할까? 클릭할까? 어느 세그먼트?)
같은 데이터로 두 가족 모두 적용 가능한 자리도 있습니다.
- “이 유저가 이탈할까” → 분류 (이탈/유지)
- “이 유저의 이탈 확률은?” → 회귀 (0~1 사이 숫자)
- “이 유저는 30일 안에 이탈할까?” → 분류
- “이 유저의 예상 잔존 일수는?” → 회귀
질문의 형태가 도구를 결정합니다. 운영 자리의 첫 결정.
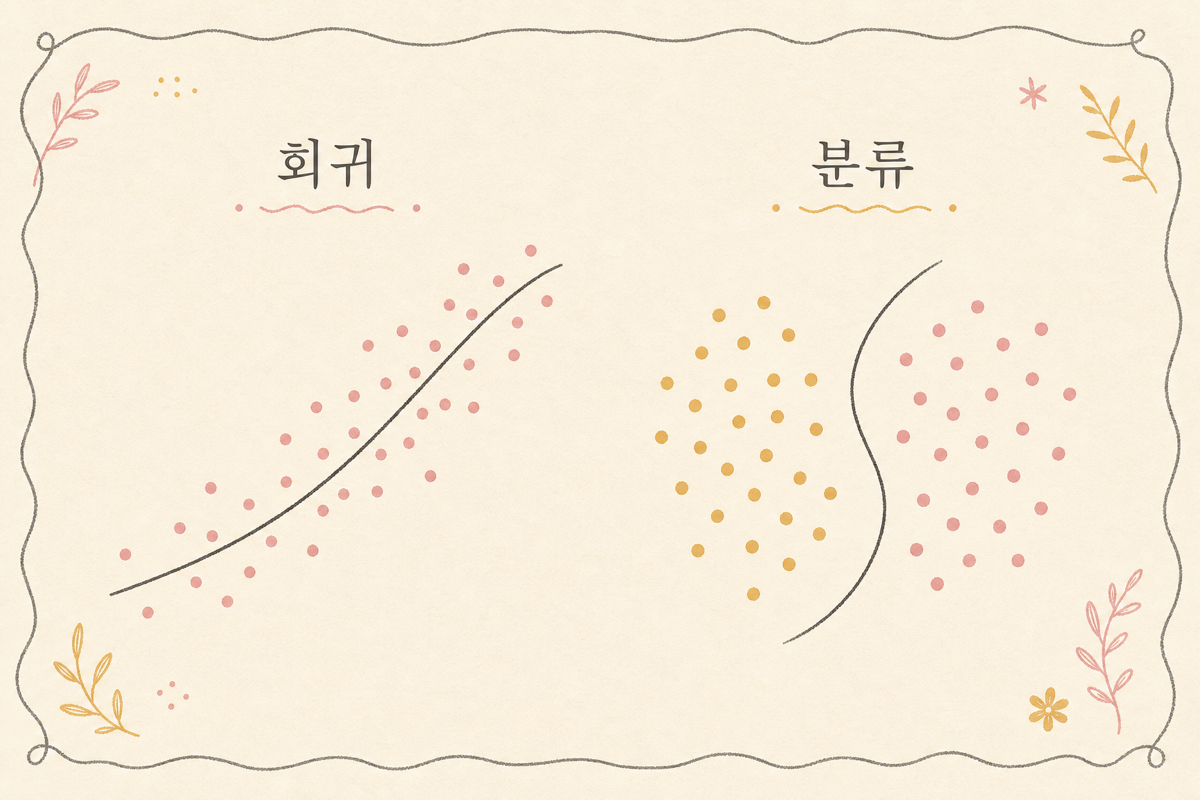
2. 회귀 — 숫자 예측의 가족
회귀의 한 줄 직관:
입력 변수들에서 연속된 숫자를 예측한다.
수식으로 가장 단순한 형태(linear regression):
각 입력 변수 에 학습된 가중치 를 곱하고 합. 결과가 예측된 숫자 .
마케팅 자리:
- LTV 예측 — 가입자 정보 → 12개월 LTV 숫자
- CTR 예측 — 광고·유저·맥락 → 클릭 확률
- 매출 예측 — 시즌·광고비·트렌드 → 다음 주 매출
- 가격 탄력성 — 가격·카테고리 → 수요량
선형 회귀는 가장 단순하지만 운영에선 보통 더 복잡한 모델 — XGBoost·LightGBM·랜덤 포레스트·Gradient Boosting·신경망 — 으로 갑니다. 같은 회귀 가족이지만 비선형 관계까지 다룸.
2-1. 회귀의 평가 지표
| 지표 | 의미 | 자주 쓰는 자리 |
|---|---|---|
| MAE | 평균 절대 오차 | 직관적, outlier에 강함 |
| RMSE | 평균 제곱근 오차 | 큰 오차에 페널티 |
| MAPE | 평균 절대 백분율 오차 | 단위 다른 자리 비교 |
| R² | 설명된 분산 비율 | 0~1, 모델이 얼마나 잘 맞나 |
운영적으로는 MAE·MAPE가 마케터에게 가장 직관적. “예측이 평균 ±15% 어긋남”이 보고서 단위로 자연스럽습니다.
3. 분류 — 카테고리 예측의 가족
분류의 한 줄 직관:
입력 변수들에서 카테고리(또는 카테고리별 확률)를 예측.
마케팅 자리:
- 이탈 예측 — 유저 행동 → 이탈할까? (이진 분류)
- 광고 클릭 예측 — 임프레션 정보 → 클릭? (이진)
- 세그먼트 분류 — 유저 행동 → 어느 세그먼트? (다중 분류)
- 카피 톤 분류 — 텍스트 → 친근/전문/신뢰 (다중)
가장 단순한 모델은 logistic regression — 선형 회귀에 sigmoid 적용해 0~1 확률 출력. 더 복잡하게는 XGBoost·신경망.
3-1. 분류의 평가 지표
| 지표 | 의미 | 자주 쓰는 자리 |
|---|---|---|
| Accuracy | 맞춘 비율 | 균형 데이터 |
| Precision | 양성 예측 중 진짜 양성 | 거짓 양성 비싼 자리 |
| Recall | 진짜 양성 중 잡아낸 비율 | 놓치면 안 되는 자리 |
| F1 | precision·recall 조화평균 | 균형 평가 |
| AUC-ROC | 임계 무관 분류 능력 | 모델 비교 표준 |
| AUC-PR | 클래스 불균형 강함 | 희귀 사건(전환·이탈) |
마케팅 자리는 보통 클래스 불균형이 큰 자리(전환율 5%, 이탈률 2%) — AUC-PR이 AUC-ROC보다 더 적합한 경우 많음.
평가 지표 선택은 평가 지표 도구상자 글(이 시리즈 9편)에서 더 자세히.
4. 이진 분류의 직관 — Confusion Matrix
이진 분류 결과를 한 표로:
| 예측: 양성 | 예측: 음성 | |
|---|---|---|
| 실제: 양성 | True Positive (TP) | False Negative (FN) |
| 실제: 음성 | False Positive (FP) | True Negative (TN) |
- Precision = TP / (TP + FP) — 양성으로 예측한 것 중 진짜 양성
- Recall = TP / (TP + FN) — 진짜 양성 중 잡아낸 비율
- Accuracy = (TP + TN) / 전체
마케팅 의사결정과 연결:
- 이탈 예측: Recall 높이고 싶다 (놓치면 손실) → False Negative 줄이기
- 광고 타겟팅: Precision 높이고 싶다 (잘못 타겟 = 비용) → False Positive 줄이기
- 두 자리는 trade-off — 임계값 조정으로 균형
5. 회귀·분류의 결정 트리 — 어디 쓰나
운영 결정의 흐름:
| 출력 형태 | 가족 | 예시 |
|---|---|---|
| 숫자 | 회귀 | LTV·매출·가격 |
| 0/1 | 이진 분류 | 이탈·클릭·전환 |
| 카테고리 | 다중 분류 | 세그먼트·카테고리·톤 |
| 0~1 확률 | 회귀 또는 logistic 분류 | CTR·이탈 확률 |
같은 자리에 회귀·분류 둘 다 가능한 경우 운영 자리에 따라:
- 임계 결정 필요 → 분류 (예측 + 임계 = 의사결정)
- 정확한 숫자 필요 → 회귀 (LTV 한도·매출 예측)
from sklearn.linear_model import LinearRegression, LogisticRegressionfrom sklearn.metrics import mean_absolute_error, accuracy_score
# 회귀 — LTV 예측reg = LinearRegression().fit(X_train, y_train)y_pred_reg = reg.predict(X_test)print('MAE:', mean_absolute_error(y_test, y_pred_reg))
# 분류 — 이탈 예측clf = LogisticRegression().fit(X_train, y_train_binary)y_pred_clf = clf.predict(X_test)print('Accuracy:', accuracy_score(y_test_binary, y_pred_clf))이게 본문에 박는 유일한 코드입니다. sklearn 한 묶음으로 회귀·분류의 표준 흐름.
6. 운영 자리에서의 함정 3가지
6-1. 분류로 풀어야 할 자리에 회귀 사용
“이 광고가 좋은가? 5점 만점”으로 회귀 → 모델이 평균 3.0 근처로 수렴해 변별력 부족. 이진 또는 카테고리 분류가 더 적합한 자리가 많음.
6-2. 회귀의 outlier에 모델이 흔들림
매출의 분포가 long-tail이라 outlier 강함. linear regression은 제곱 오차로 outlier에 민감 → 평균 5% 유저의 매출에 모델이 끌려감. log 변환·robust regression·tree 기반 모델이 답.
6-3. 분류의 클래스 불균형 무시
이탈률 2%면 모델이 “모두 안 이탈” 예측만으로 98% accuracy. 의미 없는 모델. AUC-PR·Recall·class weight 조정으로 보정.
7. 마케팅 실무 케이스 3개
7-1. LTV 예측 모델 — 회귀
가입자 행동 첫 30일 → 12개월 LTV. XGBoost 회귀. MAPE 25% 정도가 운영 표준 (LTV 분산이 워낙 큼). 광고 단가 한도 산정에 직접 사용.
7-2. 이탈 예측 모델 — 분류
행동 데이터 → 30일 안에 이탈할까. 클래스 불균형이 큼 (이탈률 5%). AUC-PR·F1 평가. Recall 우선 (놓치면 윈백 못 함).
7-3. 카피 분류기 — 다중 분류
광고 카피 → 친근/전문/신뢰/유머 4 카테고리. fine-tuned BERT 또는 prompting LLM. F1 macro 평가 (각 카테고리 균등 중요).
8. 회귀·분류에 익숙해지면 다음 글들
이 두 가족의 직관이 잡혀 있으면 huny.log의 다음 글들이 자연스럽게 이어집니다.
- BG/NBD LTV — LTV 회귀의 도메인 특화 모델
- Survival churn — 이탈 분류의 시간 의존 확장
- Uplift 모델링 — 분류의 인과추론 확장
- Conformal Prediction — 회귀·분류 위에 신뢰구간 씌우기
- Cold start Thompson — 분류 베이지안 사전 활용
9. 마치며 — ML 기초의 첫 자리
마케팅에서 머신러닝은 늘 회귀·분류 두 가족 중 하나로 시작합니다. 두 가족의 차이·평가·운영 결정을 잡고 있으면 시리즈 1·2·3의 모든 도구가 자연스럽게 읽힙니다.
출력이 숫자면 회귀, 카테고리면 분류. 평가는 자리의 비대칭 손실에 맞춰. 클래스 불균형·outlier가 흔들리는 자리.
다음 글에서는 이 두 가족이 어떻게 데이터로부터 학습하는지 — 손실 함수와 학습의 직관을 다룹니다.
참고
- Hastie, Tibshirani & Friedman (2009), The Elements of Statistical Learning — 머신러닝 표준 교과서, 회귀·분류 종합
- James, Witten, Hastie & Tibshirani (2013), An Introduction to Statistical Learning — 입문 표준 교과서
- Géron (2022), Hands-On Machine Learning with Scikit-Learn — 실무 적용
- scikit-learn 문서 — 운영 표준 도구
- Kaggle Learn — Intro to Machine Learning — 무료 입문
- huny.log 내부 글: BG/NBD LTV, Survival churn, Uplift 모델링, Conformal Prediction
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.