Simpson's Paradox가 마케터 보고서에 숨는 법 — 전체와 세그먼트가 정반대를 말할 때
전체로는 A안이 좋아 보이는데 모든 세그먼트별로는 B안이 좋다? 이게 Simpson's Paradox입니다. 실제 광고·CRM·실험 보고서에 빈번하게 숨어있는 통계 함정과 잡아내는 법.
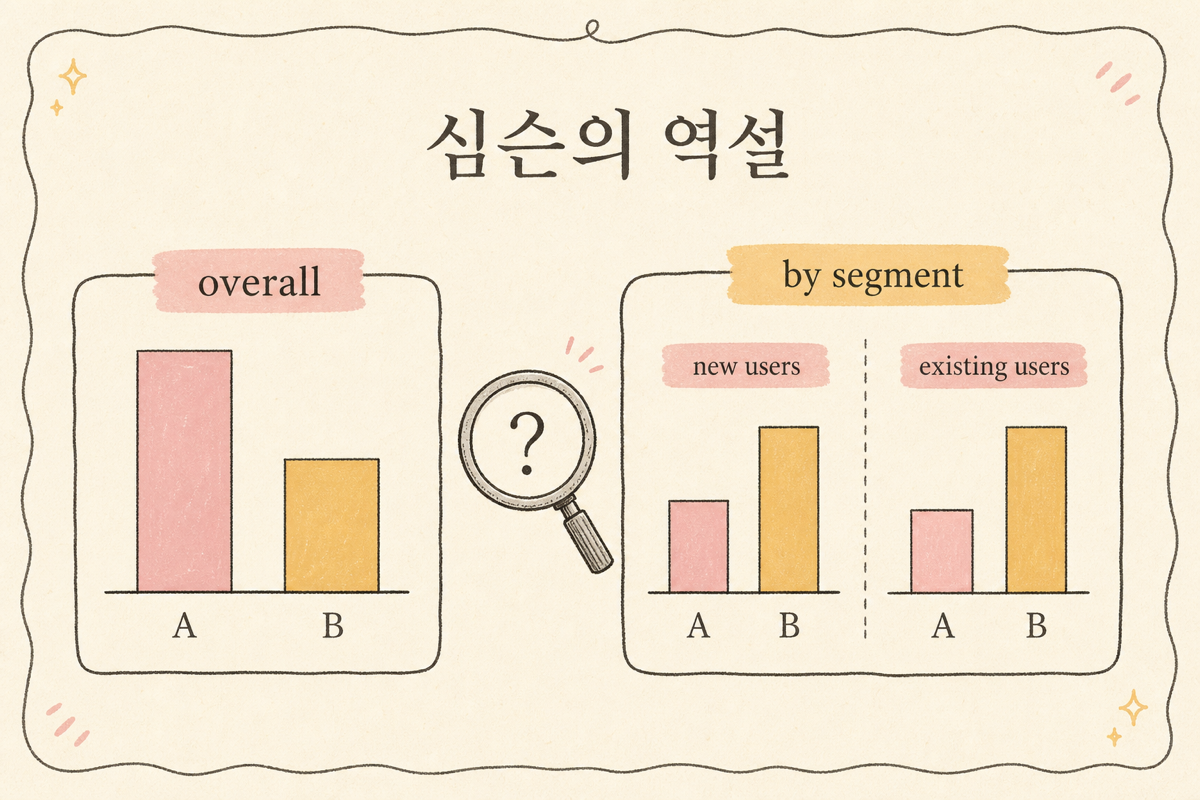
“전체 캠페인 ROAS가 A안이 4.2, B안이 3.8이니까 A안 갈게요.” — 회의 끝나기 직전, 한 분석가가 슬쩍 차트를 보여줍니다. “근데 신규 유저로만 보면 B가 4.5인데요? 기존 유저로만 봐도 B가 3.6이고요. 전체로만 A가 더 좋아요.” 이 순간 회의가 멈춥니다. 이게 바로 Simpson’s Paradox예요. 이 글은 마케터 보고서에 빈번히 숨는 이 함정을 사례로 풀고, 잡아내는 룰을 정리합니다.
한 장으로 보는 Simpson’s Paradox
가상의 캠페인 결과:
| 세그먼트 | A안 노출 | A안 전환 | A 전환율 | B안 노출 | B안 전환 | B 전환율 |
|---|---|---|---|---|---|---|
| 신규 유저 | 1,000 | 30 | 3.0% | 9,000 | 360 | 4.0% |
| 기존 유저 | 9,000 | 540 | 6.0% | 1,000 | 70 | 7.0% |
| 합계 | 10,000 | 570 | 5.70% | 10,000 | 430 | 4.30% |
읽어보세요. 두 세그먼트 모두 B의 전환율이 더 높지만, 전체로 합치면 A가 더 높아요. 이게 어떻게 가능한가?
원인: 세그먼트 크기 불균형입니다.
- A안은 90%가 기존 유저(전환율 6%)
- B안은 90%가 신규 유저(전환율 4%)
각 세그먼트의 전환율은 B가 더 높지만, A가 “전환 잘 되는 기존 유저” 비중이 압도적이라 가중평균이 더 높아 보일 뿐. 진짜 답은 B안이 모든 세그먼트에서 더 좋다는 거예요.
마케팅에서 진짜 자주 일어나는 시나리오
시나리오 1 — 광고 노출 비중이 다른 캠페인 비교
A 캠페인은 리타겟팅 비중이 높음 → 기존 고객 위주 → CTR/CVR이 자연스럽게 높음. B 캠페인은 신규 prospecting 비중이 높음. 두 캠페인 전체 전환율 비교는 의미 없음. 세그먼트 분리 후 비교가 정답.
시나리오 2 — A/B 테스트의 트래픽 불균형
이상적으론 50:50이지만 실험 도중 한쪽 트래픽이 다른 채널에서 밀려들어와 60:40으로 깨졌다고 합시다. 그 “밀려든 트래픽”이 다른 세그먼트라면 전체 결과가 흔들립니다. SRM(Sample Ratio Mismatch) 검정이 발견하는 게 거의 이 케이스.
시나리오 3 — CRM 이메일 응답률 비교
A 템플릿: VIP 고객한테 자주 발송. B 템플릿: 일반 고객한테 발송. “전체 응답률 A=12%, B=8%“는 템플릿이 좋아서가 아니라 받는 사람이 다른 사람이라 그런 거예요.
시나리오 4 — 채널별 ROAS 비교
검색광고 ROAS 8 vs 디스플레이 ROAS 3. 단순 비교는 함정. 검색은 “이미 살 사람” 비중이 압도적이라 incrementality 적용 후엔 디스플레이가 더 효율적인 케이스 흔함.
코드로 만나기 — 실제 잡아내는 법
판다스로 두 그룹의 “전체 vs 세그먼트별” 결과를 함께 보고, 자동으로 역설을 감지하는 완결형 함수입니다.
import pandas as pdimport numpy as np
# ── 1. 가상 데이터 생성 ──────────────────────────────────────df = pd.DataFrame({ "variant": ["A"]*10000 + ["B"]*10000, "segment": (["new"]*1000 + ["existing"]*9000) + (["new"]*9000 + ["existing"]*1000), "converted": ( [1]*30 + [0]*970 + [1]*540 + [0]*8460 + # A안: 신규 3.0%, 기존 6.0% [1]*360 + [0]*8640 + [1]*70 + [0]*930 # B안: 신규 4.0%, 기존 7.0% ),})
# ── 2. 전체 비교 ─────────────────────────────────────────────overall = ( df.groupby("variant")["converted"] .agg(conversions="sum", impressions="count", rate="mean") .round(4))print("=== 전체 전환율 ===")print(overall)# 출력:# conversions impressions rate# variant# A 570 10000 0.0570 ← 전체로는 A가 더 높아 보임# B 430 10000 0.0430
# ── 3. 세그먼트별 비교 ───────────────────────────────────────seg = ( df.groupby(["segment", "variant"])["converted"] .agg(conversions="sum", impressions="count", rate="mean") .round(4))print("\n=== 세그먼트별 전환율 ===")print(seg)# 출력:# conversions impressions rate# segment variant# existing A 540 9000 0.0600# B 70 1000 0.0700 ← 기존 유저에서도 B가 더 높음# new A 30 1000 0.0300# B 360 9000 0.0400 ← 신규 유저에서도 B가 더 높음
# ── 4. Simpson's Paradox 자동 탐지 함수 ─────────────────────def detect_simpsons(df, group_col, segment_col, metric_col, higher_is_better=True): """ Simpson's Paradox 탐지기.
Parameters ---------- df : DataFrame group_col : 비교할 그룹 컬럼 (예: "variant") segment_col : 층화 기준 컬럼 (예: "segment") metric_col : 결과 컬럼 (예: "converted") higher_is_better: True면 mean이 높을수록 좋음
Returns ------- dict with keys: overall_winner : 전체 기준 승자 segment_winner : 세그먼트별 승자 (세그먼트마다) paradox_detected : Simpson's Paradox 발생 여부 summary : 요약 문자열 """ groups = df[group_col].unique() if len(groups) != 2: raise ValueError("group_col은 정확히 2개 값이어야 합니다.")
g0, g1 = groups
# 전체 평균 overall_means = df.groupby(group_col)[metric_col].mean() if higher_is_better: overall_winner = overall_means.idxmax() else: overall_winner = overall_means.idxmin()
# 세그먼트별 평균 seg_means = df.groupby([segment_col, group_col])[metric_col].mean().unstack(group_col) if higher_is_better: seg_winners = seg_means.idxmax(axis=1) else: seg_winners = seg_means.idxmin(axis=1)
# 역설 감지: 전체 승자 ≠ 모든 세그먼트 승자 all_seg_same = (seg_winners == seg_winners.iloc[0]).all() if all_seg_same and seg_winners.iloc[0] != overall_winner: paradox_detected = True summary = ( f"⚠️ Simpson's Paradox 감지!\n" f" 전체 승자: {overall_winner} " f"(mean={overall_means[overall_winner]:.4f})\n" f" 모든 세그먼트 승자: {seg_winners.iloc[0]}\n" f" → 세그먼트 분리 결과를 우선 신뢰하세요." ) else: paradox_detected = False summary = f"✅ 역설 없음. 전체 승자: {overall_winner}"
return { "overall_winner": overall_winner, "segment_winners": seg_winners.to_dict(), "paradox_detected": paradox_detected, "summary": summary, }
result = detect_simpsons(df, "variant", "segment", "converted")print("\n" + result["summary"])# 출력:# ⚠️ Simpson's Paradox 감지!# 전체 승자: A (mean=0.0570)# 모든 세그먼트 승자: B# → 세그먼트 분리 결과를 우선 신뢰하세요.이 함수를 실험 보고서 자동화 파이프라인에 추가하면, 분석가가 결과 슬라이드를 만들기 전에 자동으로 빨간불이 켜집니다. metric_col은 전환율·ROAS·LTV 등 어떤 연속형 지표도 대입 가능하고, segment_col은 신규/기존·채널·디바이스 등 자유롭게 교체 가능합니다.
어느 쪽을 믿어야 하나 — DAG 기반 의사결정 가이드
세그먼트별과 전체가 다를 때, 어느 답을 보고서에 가져갈지는 단순히 “사용 시나리오”가 아니라 인과 그래프(DAG)의 구조에 따라 결정됩니다. 세 가지 상황을 구분하세요.
1) 세그먼트 변수가 confounder인가? → 세그먼트 분리 필수
세그먼트 변수(신규/기존 유저)가 캠페인 배정과 결과 모두에 영향을 미치는 confounder라면, 전체 평균은 backdoor path가 열린 편향 추정입니다. 세그먼트별 비교가 정답이에요.
판단 기준: “이 변수가 어느 캠페인에 배정될지에도 영향을 미쳤는가?” → YES이면 confounder.
2) 세그먼트 변수가 collider인가? → 세그먼트 분리 금지
“결과에만 영향받는” 변수로 층화하면 오히려 편향이 생깁니다(collider bias). 예: 캠페인 결과로 정의된 “전환자/비전환자” 세그먼트로 다시 비교하면 역선택 편향 발생. 이 경우 전체 비교가 더 안전합니다.
3) 트래픽 구성이 같다면 → 전체 OK
두 캠페인이 동일한 모집단에서 랜덤 배정된 실험이라면 confounder가 통제됩니다. 전체 평균이 올바른 추정. SRM(Sample Ratio Mismatch) 검정이 통과된 A/B 테스트에서는 전체 결과를 신뢰할 수 있어요.
4) 의사결정의 단위가 “전체 매출”이라면 → 타겟 구성 가중평균
CFO 입장에선 “이번 분기 전체 매출이 얼마인가”가 중요하니, 타겟 시점의 트래픽 구성으로 가중평균한 값을 보고합니다. 위 예시에서는 “운영 시 신규/기존 유저 비중이 50:50이 된다면” 그 비중으로 가중한 B의 성과가 정답.
# 타겟 트래픽 구성(신규 50%, 기존 50%)으로 가중평균target_weights = {"new": 0.5, "existing": 0.5}
seg_rate = df.groupby(["segment", "variant"])["converted"].mean()
for variant in ["A", "B"]: weighted = sum( seg_rate[seg][variant] * w for seg, w in target_weights.items() ) print(f"{variant}: {weighted:.4f}")# A: (0.0300 × 0.5) + (0.0600 × 0.5) = 0.0450# B: (0.0400 × 0.5) + (0.0700 × 0.5) = 0.0550 ← B가 정답인과 그래프(DAG)로 보는 Simpson’s Paradox — 왜 일어나는가
Simpson’s Paradox의 구조적 원인은 confounder(혼재변수)입니다. 단순히 “세그먼트 크기가 다르다”가 아니라, 세그먼트 크기 불균형을 만드는 배경 변수가 동시에 결과에 영향을 미치는 구조.
Judea Pearl의 인과 그래프(Directed Acyclic Graph, DAG)로 표현하면:
유저 타입(신규/기존) │ ├──────────────► 캠페인 배정(A vs B) │ │ │ │ └──────────────► 전환율 ◄──┘“유저 타입”이 캠페인 배정과 전환율 모두에 영향을 미치는 confounder. 이 경로를 backdoor path라고 합니다. 분석가가 전체 전환율로 캠페인 효과를 비교할 때, 이 backdoor path를 막지 않으면 편향된 추정이 됩니다.
Pearl의 backdoor criterion: confounder(유저 타입)를 조건부로 막으면 편향 없는 효과 추정 가능. 마케팅 언어로 번역하면 “세그먼트를 고정해서 보는 것”이 backdoor path를 막는 행위.
Collider bias와의 구분: confounder는 “두 변수의 공통 원인”이지만, collider는 “두 변수의 공통 결과”입니다. collider로 층화(stratify)하면 역설적으로 편향이 생기므로, 어떤 변수가 confounder이고 어떤 게 collider인지 DAG 없이는 구분이 어렵습니다. 보고서에서 세그먼트를 추가할 때 항상 “이 변수가 캠페인 배정에 영향을 미쳤는가, 아니면 결과 이후에 정의되는가”를 먼저 확인하세요.
잠재 변수(confounder) 후보
Simpson’s Paradox의 더 깊은 원인은 거의 항상 잠재 변수예요. 위 사례에서 “신규 vs 기존”을 안 봤다면 진짜 원인을 못 찾는 거죠. 잠재 변수 후보:
- 시즌성: 같은 캠페인을 다른 주에 돌렸으면 트래픽 구성이 다름
- 유입 채널: 검색에서 들어온 사람과 SNS에서 들어온 사람의 행동 차이
- 디바이스: 모바일 vs 데스크탑 전환율 차이
- 세그먼트 상호작용: 신규×SNS×모바일 같은 교차 그룹
이걸 다 잡으려면 결국 인과추론(causal inference)의 영역이에요. Geo-lift 글이나 DiD 글에서 다루는 holdout test가 이 함정에서 빠져나오는 가장 깔끔한 답입니다.
운영 팁 — 보고서 빌드 단계에 넣을 룰
1) 자동 세그먼트 분리
BI 대시보드에서 “전체 + 신규/기존 + 디바이스 + 채널” 4가지 분해를 기본 뷰로. 차트가 4개라 부담스러우면 “세그먼트별 일관성 표시 한 칸”만이라도 추가.
2) 가중평균 컬럼 한 칸
전체 평균 옆에 “타겟 트래픽 구성 가중평균” 한 칸 추가. 둘이 다르면 노란불.
3) SRM 검정
A/B 테스트는 SRM 검정을 자동화. p < 0.001이면 트래픽이 50:50 깨졌다는 뜻이고, 거기엔 거의 항상 Simpson’s Paradox가 숨어 있어요.
4) 사전 “세그먼트 가설” 등록
실험 시작 전에 “이 실험은 신규 유저 세그먼트에서 더 효과 클 것” 같은 가설을 등록. 결과를 그 가설 단위로 1차 분석 → 전체로 2차 분석 순서.
마치며
Simpson’s Paradox는 “고급 통계 이슈”가 아니에요. 마케터 보고서에 매주 한두 번씩 숨어 들어오는 흔한 함정이고, 3분짜리 세그먼트 분해 룰만 적용해도 90%는 잡힙니다. 그런데 이 함정이 흔한 이유는 인과 구조(DAG)를 모른 채 데이터를 집계하기 때문입니다.
핵심 원칙 세 줄:
- 전체 평균을 단독으로 보고하지 않는다. 항상 “세그먼트별로도 같은 결론인가”를 함께.
- 세그먼트 변수가 confounder인지 collider인지를 DAG로 먼저 확인한다.
- 역설이 감지되면
detect_simpsons()함수로 자동화하고, 타겟 트래픽 구성 가중평균으로 최종 보고한다.
“B안: 전환율 4.55% (신규 4.0% / 기존 7.0%, 타겟 50:50 가중평균)” — 이 한 줄이 “A안: 5.7%“보다 훨씬 더 정직한 보고서입니다.
참고
- Simpson’s Paradox — Wikipedia — 정의와 역사
- Pearl, J. (2009), Causality: Models, Reasoning, and Inference (2nd ed.), Cambridge University Press — backdoor criterion·DAG·do-calculus 원전
- The Book of Why — Judea Pearl & Dana Mackenzie (2018) — 인과추론과 함께 보는 Simpson’s Paradox, 마케터도 읽을 수 있는 수준
- Sample Ratio Mismatch — Microsoft Experimentation Platform — A/B 테스트의 SRM 진단
- Trustworthy Online Controlled Experiments — Kohavi, Tang, Xu — 실험 운영 표준서, 6장이 정확히 이 주제
- huny.log 내부 글: Geo-lift 인과추론, DiD 인과추론, A/B 테스트 함정, Uplift 모델링
통계·ML 카테고리의 다른 글
전체 보기 →-
2026·05·10
마케팅 실험 플랫폼 설계 — 사내 A/B 시스템의 5가지 원칙
광고 플랫폼 자체 A/B로는 부족하고 외부 SaaS는 비쌉니다. 사내 마케팅 실험 플랫폼을 설계할 때 깔아야 할 split assignment·exposure log·SRM 검정·sequential safe·메타 표준 5가지 원칙.
-
2026·05·09
Bayesian A/B 테스트 심화 — prior 잡는 법과 HDI 해석
베이지안 A/B는 "p-value < 0.05"가 아니라 "B가 A보다 좋을 확률 0.92"를 줍니다. 그 확률이 정직하려면 prior를 잘 잡아야 하고, HDI를 잘못 읽으면 함정이 옵니다. 마케터 시선에서 prior·posterior·HDI 정리.
-
2026·05·09
Doubly robust estimation — IPW와 outcome 모델의 결합으로 인과 추정 안정화
PSM·IPW는 propensity 모델이 틀리면 무너지고, 회귀는 outcome 모델이 틀리면 무너집니다. doubly robust는 두 모델을 결합해 둘 중 하나만 맞으면 정직한 효과 추정. 마케팅 인과 분석의 안전판.
-
2026·05·09
Heterogeneous treatment effects — 평균 효과 너머의 개인별 효과
A/B 평균 효과 +5%p가 모든 사람에게 같지 않습니다. 일부에게는 +20%p, 일부에게는 -3%p. CATE·uplift forest로 효과의 이질성을 추정해 타겟 마케팅을 정밀화하는 흐름.